
從食譜到佳餚:DNA、RNA 與蛋白質的中心法則
一段四字母的密碼,如何變成活生生的你
從一本食譜到一桌好菜:基因到底在說什麼?
想像你家裡有一本傳家寶食譜,厚厚一大本,記著祖傳幾百道菜的做法。這本食譜太珍貴了,從來不准帶出廚房,更不能弄髒弄壞。每當廚師想做某一道菜,他不會把整本書搬到爐火邊,而是先把那一頁「抄」到一張小紙條上,再拿著紙條去料理。
你身體裡的每一個細胞,幾乎都做著一模一樣的事。那本不准外帶的「食譜」就是 DNA,安安穩穩地待在細胞核裡;那張臨時抄寫的「紙條」叫做 RNA;而最後端上桌的那道菜,就是讓你能呼吸、消化、思考、跑跳的蛋白質。
這一整套「DNA → RNA → 蛋白質」的流程,生物學家給它一個很有份量的名字:中心法則(Central Dogma)。這篇文章就要帶你一步步看懂,一段看似無聊的字母排列,是怎麼變成活生生的你。
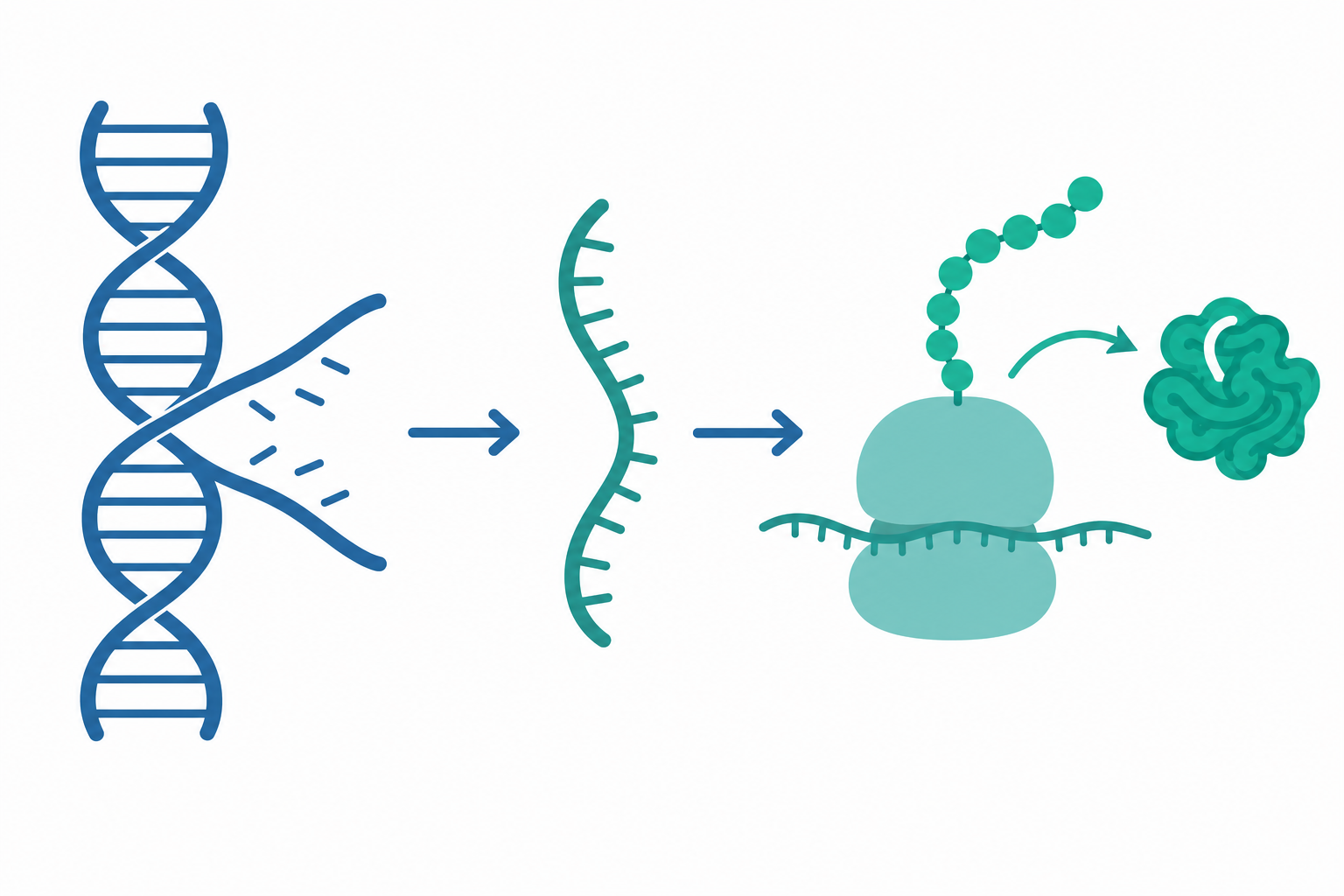
DNA:用四個字母寫成的生命之書
DNA 的全名是「去氧核糖核酸」。它的長相很有名——兩條鏈互相纏繞,像一道旋轉的樓梯,這就是雙螺旋(double helix)。
這道樓梯的「階梯」由四種鹼基組成,我們用四個字母代表:A(腺嘌呤)、T(胸腺嘧啶)、G(鳥糞嘌呤)、C(胞嘧啶)。它們的配對非常嚴格,像鎖和鑰匙一樣:
- A 永遠對 T
- G 永遠對 C
這叫做互補配對。所以如果你知道一條鏈是 A-T-G-C,另一條鏈就一定是 T-A-C-G。這個「一邊決定另一邊」的特性,正是生命能夠複製自己的關鍵。
生命的所有資訊,就藏在這四個字母的排列順序裡。三十億個字母排成一排,就寫成了一個人的「使用說明書」。
DNA 複製:細胞分裂前的抄書工程
一個細胞要分裂成兩個之前,必須先把整本食譜完整抄一份,好讓兩個細胞各拿一本。這個過程叫 DNA 複製。
步驟其實很直覺:
- 雙螺旋像拉鍊一樣被拉開,兩條鏈分開。
- 每一條舊鏈都當作「模板」。
- 細胞按照互補配對規則(A 配 T、G 配 C),在每條舊鏈旁邊補上新的鏈。
- 結果就是兩條一模一樣的新雙螺旋,各保留了一條舊鏈、一條新鏈。
因為每個新分子都「半舊半新」,這種方式被稱為半保留複製(semiconservative replication)。1958 年的梅塞爾森—史塔爾實驗(Meselson–Stahl experiment)漂亮地證實了這一點,被譽為「生物學上最美的實驗之一」。
轉錄:把食譜抄成紙條
要做出蛋白質,細胞不會直接拿 DNA 去用,而是先把需要的那一段基因「抄」成 RNA,這個動作叫 轉錄(transcription)。
抄寫的工人是一種叫 RNA 聚合酶 的酵素。它沿著 DNA 滑動,讀取其中一條鏈,照著互補規則拼出一條 RNA。這裡有個小變化要記住:在 RNA 的世界裡,沒有 T,改用 U(尿嘧啶)。
舉個對照例子,假設 DNA 模板鏈是:
$$\text{DNA 模板:} 3'\text{-T A C G G T-}5'$$
那麼轉錄出來的 RNA(信使 RNA,mRNA)就是:
$$\text{mRNA:} 5'\text{-A U G C C A-}3'$$
你看,A 對 U、C 對 G,規則一以貫之。這條 mRNA 就是那張帶出廚房的「紙條」,它會離開細胞核,前往蛋白質的製造工廠。
轉譯:把字母翻譯成蛋白質
最後一步是 轉譯(translation),發生在細胞質裡一個叫 核糖體(ribosome) 的構造上。
蛋白質是由胺基酸串成的長鏈。問題來了:RNA 只有 4 種字母,胺基酸卻有 20 種,怎麼對應?
大自然的解法很巧妙:每三個字母一組,叫做一個密碼子(codon)。三個字母為一組,共有 $4^3 = 64$ 種組合,足夠對應 20 種胺基酸還有剩。
核糖體沿著 mRNA 一次讀三個字母,每讀到一個密碼子,就有對應的轉運 RNA(tRNA)搬來正確的胺基酸接上去。例如:
AUG→ 甲硫胺酸(同時也是「開始」的起始訊號)UUU→ 苯丙胺酸UAA、UAG、UGA→ 終止訊號(讀到這裡就停工、放開成品)
一個個胺基酸串起來,折疊成特定的立體形狀,一個功能完整的蛋白質就誕生了。它可能變成你頭髮裡的角蛋白、血液裡運送氧氣的血紅素,或是加速消化的酵素。
把整條流程串起來看
讓我們用一句話複習整條中心法則:
$$\text{DNA} \xrightarrow{\text{轉錄}} \text{mRNA} \xrightarrow{\text{轉譯}} \text{蛋白質}$$
- DNA:細胞核裡的傳家食譜,不外借。
- 複製:分裂前把整本抄一份。
- 轉錄:把要用的那頁抄成 RNA 紙條。
- 轉譯:核糖體照著紙條,把胺基酸組裝成蛋白質。
從一段四字母的密碼,到一個能運作的蛋白質——這就是基因「表現」的全貌。下次你聽到「這是基因決定的」,其實背後就是這套精密又優雅的抄寫與翻譯工程在運轉。
深入探討(研究所視角)
中心法則在教科書裡常被畫成一條乾淨的單行道,但分子層次的真實圖像遠為複雜且充滿調控。
轉錄調控與表觀遺傳。 基因「開或關」並非由序列本身決定,而受啟動子(promoter)、增強子(enhancer)與大量轉錄因子的組合控制。更上一層,表觀遺傳(epigenetics)——DNA 甲基化(CpG island methylation)與組蛋白修飾(如 H3K27ac、H3K9me3)——能在不改變鹼基序列的前提下開關基因,且部分可跨細胞世代遺傳。染色質的三維摺疊(TAD、loop)讓遠端增強子得以接觸目標啟動子,是當前 Hi-C 研究的核心。
RNA 加工與剪接。 真核生物的初級轉錄產物需經過 5' 加帽、3' 多聚腺苷酸化與剪接(splicing),移除內含子(intron)、接合外顯子(exon)。選擇性剪接(alternative splicing)讓單一基因得以編碼多種蛋白質異構體,是人類僅約兩萬個基因卻能維持高度複雜度的關鍵原因之一。
中心法則的「逆流」與例外。 反轉錄病毒(如 HIV)藉反轉錄酶將 RNA 寫回 DNA,打破了「資訊只從 DNA 流向 RNA」的單向假設,這也催生了 RNA-seq 與 cDNA 技術的基礎。普里昂蛋白(prion)則展示了不經核酸、純靠蛋白質構象傳遞的遺傳訊息形式。
翻譯後修飾與蛋白質摺疊。 蛋白質的最終功能不止取決於胺基酸序列,還受磷酸化、醣基化、泛素化等翻譯後修飾調控;摺疊錯誤與聚集則與阿茲海默症等神經退化疾病相關。Levinthal 悖論點出蛋白質不可能靠隨機嘗試找到正確構象,而需分子伴護蛋白(chaperone)協助——AlphaFold 等深度學習模型近年在結構預測上的突破,正是系統生物學與 AI 交會的前沿。
精準編輯與單細胞時代。 CRISPR-Cas9 讓研究者能在特定位點切割並改寫基因組,base editing 與 prime editing 進一步實現單鹼基層級的精準修改。與此同時,單細胞 RNA 定序(scRNA-seq)讓我們得以在單一細胞解析度觀察轉錄組異質性,揭示傳統群體平均所掩蓋的細胞亞型與發育軌跡。將基因組、轉錄組、表觀基因組與蛋白質組整合分析的多體學(multi-omics),正把中心法則從一條線推進成一張動態、相互回饋的調控網絡——這也與本讀本「遺傳與演化」主題群中突變、天擇如何作用於基因表現的議題緊密相連。