
正則化迴歸(Ridge/Lasso)與過擬合
從偏誤—變異數權衡到稀疏估計:收縮估計量的統計原理、推導與漸近性質
從過擬合的代價談起
當我們用最小平方法(OLS)擬合一個高維線性模型時,常常會遇到一個矛盾:模型在訓練資料上表現極佳,但對新資料的預測卻荒腔走板。這正是過擬合(overfitting)——模型把資料中的雜訊也當成訊號學了進去。正則化(regularization)的核心思想,就是「故意」在估計時引入一點偏誤(bias),來換取變異數(variance)的大幅下降,從而降低整體的預測誤差。
考慮標準線性模型 $y_i = \mathbf{x}_i^\top \boldsymbol\beta + \varepsilon_i$,其中 $\varepsilon_i$ 為零均值、變異數 $\sigma^2$ 的隨機誤差。OLS 估計量 $\hat{\boldsymbol\beta}_{\text{OLS}} = (\mathbf{X}^\top\mathbf{X})^{-1}\mathbf{X}^\top\mathbf{y}$ 在 Gauss–Markov 條件下是最佳線性不偏估計量(BLUE)。問題在於:當特徵高度共線(multicollinearity)或維度 $p$ 接近樣本數 $n$ 時,$\mathbf{X}^\top\mathbf{X}$ 接近奇異,其逆矩陣的特徵值會爆炸,導致 $\operatorname{Var}(\hat{\boldsymbol\beta}_{\text{OLS}}) = \sigma^2 (\mathbf{X}^\top\mathbf{X})^{-1}$ 巨大。不偏,但極不穩定。
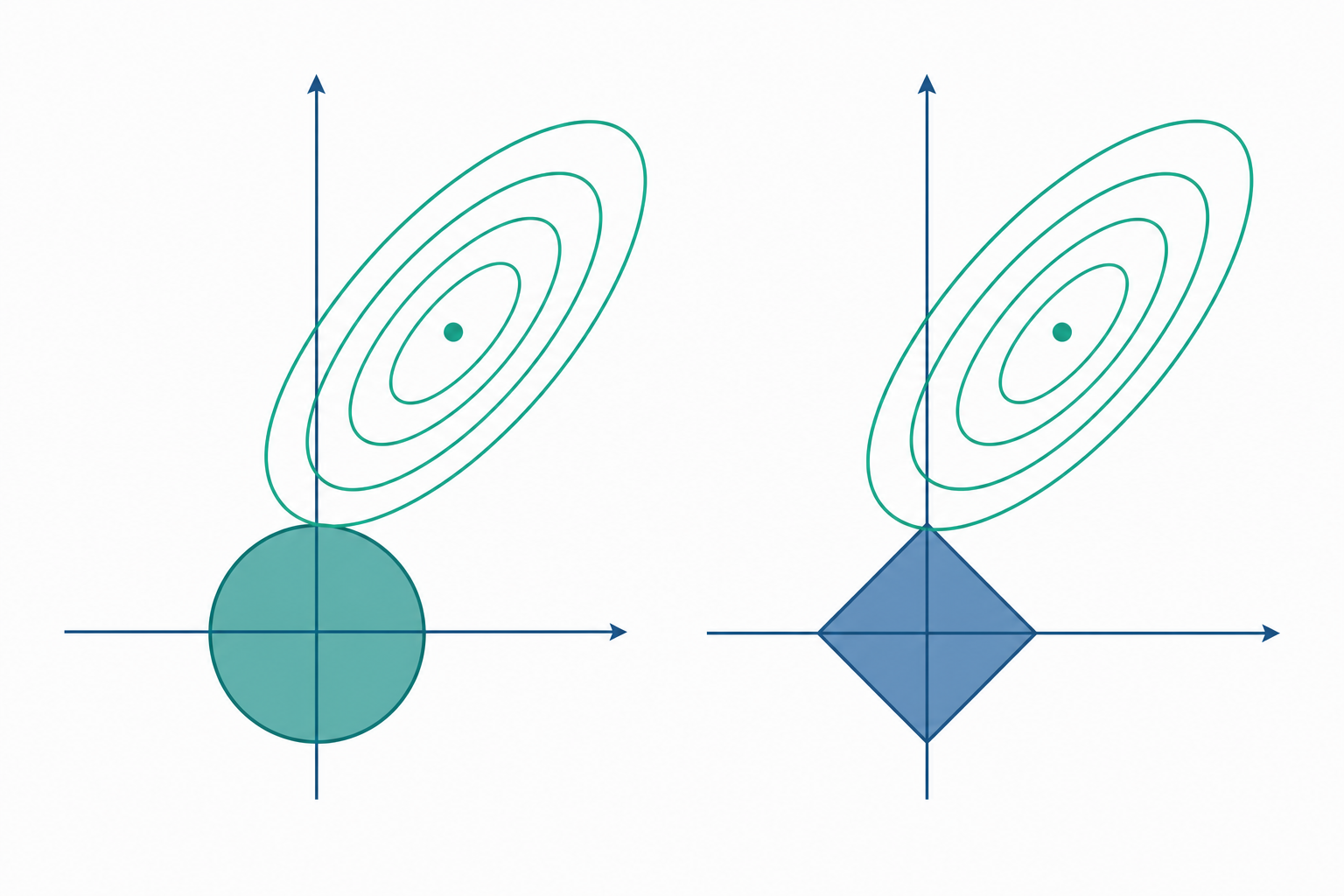
偏誤—變異數分解:為何「故意偏一點」是值得的
對任一估計量 $\hat\beta$,其在某點的均方誤差(MSE)可分解為
$$ \mathbb{E}\big[(\hat\beta - \beta)^2\big] = \underbrace{\big(\mathbb{E}[\hat\beta] - \beta\big)^2}_{\text{偏誤}^2} + \underbrace{\operatorname{Var}(\hat\beta)}_{\text{變異數}}. $$
OLS 把偏誤項壓成零,卻放任變異數膨脹。正則化的策略是反過來:容許一個小偏誤,讓變異數大幅縮小,使總 MSE 下降。這就是 James–Stein 現象的精神——在高維下,有偏的收縮估計量可以一致地優於不偏估計量。
Ridge 迴歸:$L_2$ 懲罰與閉式解
Ridge 迴歸在 OLS 的殘差平方和上加一個 $L_2$ 懲罰項:
$$ \hat{\boldsymbol\beta}_{\text{ridge}} = \arg\min_{\boldsymbol\beta} \; \|\mathbf{y} - \mathbf{X}\boldsymbol\beta\|_2^2 + \lambda \|\boldsymbol\beta\|_2^2, \qquad \lambda \ge 0. $$
對 $\boldsymbol\beta$ 求導並令其為零,$-2\mathbf{X}^\top(\mathbf{y}-\mathbf{X}\boldsymbol\beta) + 2\lambda\boldsymbol\beta = \mathbf{0}$,整理得閉式解
$$ \hat{\boldsymbol\beta}_{\text{ridge}} = (\mathbf{X}^\top\mathbf{X} + \lambda \mathbf{I})^{-1}\mathbf{X}^\top\mathbf{y}. $$
關鍵在於 $\lambda \mathbf{I}$:它把 $\mathbf{X}^\top\mathbf{X}$ 的每個特徵值都抬高了 $\lambda$,因此即使原矩陣接近奇異,加上 $\lambda\mathbf{I}$ 後也必定可逆。這正是 Hoerl 與 Kennard(1970)提出 Ridge 的初衷——解決共線性下的數值不穩定。
從統計性質看,設 $\mathbf{X}^\top\mathbf{X}$ 的特徵值為 $d_j^2$。可證明 Ridge 估計沿第 $j$ 個主成分方向把 OLS 係數收縮為原來的 $d_j^2/(d_j^2+\lambda)$ 倍;小特徵值(不穩定方向)被收縮得最厲害。其偏誤與變異數為
$$ \operatorname{Bias} = -\lambda(\mathbf{X}^\top\mathbf{X}+\lambda\mathbf{I})^{-1}\boldsymbol\beta, \quad \operatorname{Var} = \sigma^2 (\mathbf{X}^\top\mathbf{X}+\lambda\mathbf{I})^{-1}\mathbf{X}^\top\mathbf{X}(\mathbf{X}^\top\mathbf{X}+\lambda\mathbf{I})^{-1}. $$
Hoerl–Kennard 定理保證:存在某個 $\lambda>0$,使 Ridge 的總 MSE 嚴格小於 OLS。
Lasso 迴歸:$L_1$ 懲罰與稀疏性
Lasso(Tibshirani, 1996)改用 $L_1$ 懲罰:
$$ \hat{\boldsymbol\beta}_{\text{lasso}} = \arg\min_{\boldsymbol\beta}\; \|\mathbf{y}-\mathbf{X}\boldsymbol\beta\|_2^2 + \lambda\|\boldsymbol\beta\|_1. $$
$L_1$ 範數在座標軸上有「尖角」,使解傾向落在軸上——也就是讓部分係數恰好等於零,達成自動變數選擇。Ridge 的 $L_2$ 球面光滑,只會把係數推向小、卻不會歸零。
Lasso 無一般閉式解,但在特徵正交($\mathbf{X}^\top\mathbf{X}=\mathbf{I}$)的特例下,解就是對 OLS 係數做軟閾值(soft-thresholding):
$$ \hat\beta_j^{\text{lasso}} = \operatorname{sign}(\hat\beta_j^{\text{OLS}})\,\big(|\hat\beta_j^{\text{OLS}}| - \tfrac{\lambda}{2}\big)_+ , $$
其中 $(z)_+ = \max(z,0)$。對照之下,Ridge 在同樣情境是比例收縮 $\hat\beta_j^{\text{ridge}} = \hat\beta_j^{\text{OLS}}/(1+\lambda)$——一個把小係數砍成零,一個只是等比例縮小,差異一目了然。
定量小範例:軟閾值與比例收縮
設特徵已標準化且正交,OLS 給出三個係數 $\hat\beta^{\text{OLS}} = (2.0,\ 0.3,\ -1.2)$。取 $\lambda = 1.0$。
Lasso(軟閾值,閾值 $\lambda/2 = 0.5$):
- $\beta_1:\ \operatorname{sign}(2.0)\cdot(2.0-0.5)_+ = +1.5$
- $\beta_2:\ \operatorname{sign}(0.3)\cdot(0.3-0.5)_+ = (-0.2)_+ = 0$(被選掉)
- $\beta_3:\ \operatorname{sign}(-1.2)\cdot(1.2-0.5)_+ = -0.7$
結果 $\hat\beta^{\text{lasso}} = (1.5,\ 0,\ -0.7)$,弱特徵 $\beta_2$ 直接歸零。
Ridge(比例收縮,除以 $1+\lambda = 2$):
$$ \hat\beta^{\text{ridge}} = \big(\tfrac{2.0}{2},\ \tfrac{0.3}{2},\ \tfrac{-1.2}{2}\big) = (1.0,\ 0.15,\ -0.6). $$
三個係數全部保留、僅等比例縮小一半。同一組資料、同一個 $\lambda$,Lasso 做了「選擇」,Ridge 做了「收縮」。
如何選 $\lambda$:交叉驗證與正則化路徑
$\lambda$ 是調節偏誤—變異數權衡的旋鈕:$\lambda\to 0$ 退化為 OLS(低偏誤、高變異),$\lambda\to\infty$ 把所有係數壓向零(高偏誤、低變異)。實務上以 $k$ 折交叉驗證(cross-validation)在驗證集上挑使預測誤差最小的 $\lambda$,並常採用「1 標準誤規則」選一個略大、更簡約的 $\lambda$。LARS 演算法可一次算出 Lasso 的完整正則化路徑。
統計素養提醒:正則化是為了預測穩定與變數篩選,被 Lasso 選中不代表該變數與結果有因果關係——它只是在這組樣本與這個 $\lambda$ 下對預測有貢獻。共線特徵中 Lasso 往往「隨機」只留一個,切勿據此宣稱被留下者「比較重要」。
深入探討(研究所視角)
懲罰似然與貝氏對應。 正則化估計可統一視為「懲罰最大概似」。在高斯誤差下,OLS 的目標函數等價於對數概似;加上懲罰項後,目標 $-\log L(\boldsymbol\beta) + \lambda\, J(\boldsymbol\beta)$ 恰是最大後驗(MAP)估計的負對數後驗。具體而言,Ridge 對應在 $\boldsymbol\beta$ 上施加高斯先驗 $\beta_j \sim \mathcal{N}(0,\tau^2)$,其中 $\lambda = \sigma^2/\tau^2$;Lasso 則對應拉普拉斯(雙指數)先驗 $\pi(\beta_j)\propto \exp(-|\beta_j|/b)$。拉普拉斯先驗在原點的尖峰正是稀疏性的來源。這個觀點開啟了完整的貝氏 Lasso(Park & Casella, 2008),能透過 MCMC 給出後驗區間,而非僅點估計——值得注意的是,標準 Lasso 的後選擇推論(post-selection inference)因為「先選變數再做推論」會使天真的信賴區間與 p 值嚴重失真,這是 selective inference(Lee et al., 2016)這一支文獻試圖修正的核心問題。切勿把 Lasso 選後再跑 OLS 得到的 p 值當成有效推論。
漸近性質。 在固定 $p$、$n\to\infty$ 下,若真實參數中有一組為零,Knight 與 Fu(2000)證明 Lasso 估計量在適當的 $\lambda_n = O(\sqrt{n})$ 速率下收斂,但其極限分布並非高斯,而是某個受 $L_1$ 懲罰扭曲的非常態分布——這解釋了為何標準 Wald 型推論失效。更進一步,Zou(2006)指出原始 Lasso 不滿足「oracle property」(無法同時做到變數選擇一致與 $\sqrt{n}$-漸近有效),並提出以權重懲罰 $\sum_j w_j|\beta_j|$ 的 Adaptive Lasso 來補足,在 irrepresentable condition 下達成 oracle 性質。高維($p\gg n$)下,Bickel、Ritov 與 Tsybakov(2009)在 restricted eigenvalue 條件下建立了 Lasso 的預測與估計誤差非漸近上界 $\|\hat{\boldsymbol\beta}-\boldsymbol\beta\|_2^2 = O_p\!\big(s\log p / n\big)$,其中 $s$ 為真實非零係數個數。
動差法與更廣的連結。 從另一視角,Ridge 可看成對含測量誤差的設計矩陣做動差修正。Elastic Net(Zou & Hastie, 2005)結合 $L_1$ 與 $L_2$ 懲罰,兼得 Lasso 的稀疏與 Ridge 對共線群組的「群組收縮」效果。在機器學習中,$L_2$ 懲罰等價於對權重的衰減(weight decay),與早停(early stopping)在梯度下降下有近似等效關係。而在因果推論前沿,double/debiased machine learning(Chernozhukov et al., 2018)刻意用 Lasso 等正則化方法擬合高維干擾參數(nuisance),再透過 Neyman 正交化與交叉擬合去除正則化偏誤,得到對處理效應的 $\sqrt{n}$-有效、可信賴區間的估計。這恰恰呼應前述提醒:正則化是強大的預測與降維工具,但要從中萃取因果結論,必須額外搭配識別假設與去偏程序,不能僅憑係數被選中與否來下因果判斷。