
聯合分布、共變異數與獨立性:耦合結構的嚴謹剖析
從共變異數的推導、不相關與獨立的差異,到估計量漸近性質與因果推論的連結
從邊際到聯合:為何「各自的分布」遠遠不夠
兩個隨機變數各自的分布,無法告訴你它們如何「一起變動」。身高高的人是否傾向體重也重?股票 A 漲時 B 是否跟著漲?這類問題的答案藏在聯合分布裡,而非任何單一變數的邊際分布。本文從聯合分布的定義出發,嚴謹推導共變異數的性質、釐清「不相關」與「獨立」的差異,並以一個離散範例貫穿計算。
設 $(X, Y)$ 為定義在同一機率空間上的隨機變數對。其聯合行為由聯合累積分布函數完整刻畫:
$$F_{X,Y}(x,y) = P(X \le x,\ Y \le y).$$
連續情形下若存在聯合密度 $f_{X,Y}(x,y)$,則 $F_{X,Y}(x,y) = \int_{-\infty}^{x}\int_{-\infty}^{y} f_{X,Y}(u,v)\,dv\,du$。邊際分布是聯合分布「積分掉」另一個變數的投影:$f_X(x) = \int_{-\infty}^{\infty} f_{X,Y}(x,y)\,dy$。關鍵在於:從聯合可唯一決定邊際,但從邊際無法還原聯合——除非加上額外結構(如獨立性)。
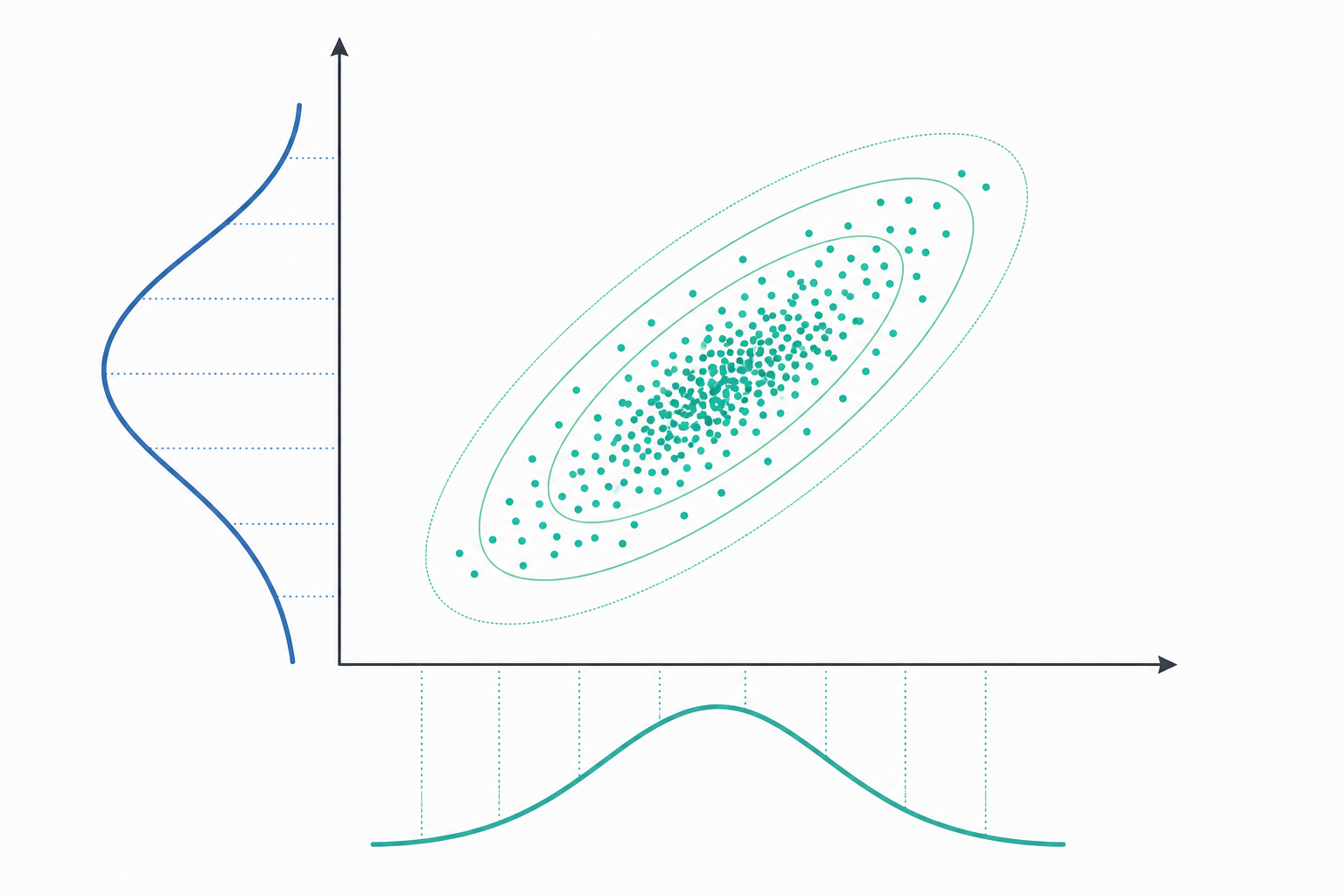
共變異數:一階耦合的度量
共變異數量化 $X$ 與 $Y$ 的線性共變趨勢,定義為
$$\operatorname{Cov}(X,Y) = E\big[(X - \mu_X)(Y - \mu_Y)\big],\qquad \mu_X = E[X],\ \mu_Y = E[Y].$$
展開內積並利用期望值的線性性質,可得最常用的計算公式。推導如下:
$$ \begin{aligned} \operatorname{Cov}(X,Y) &= E[XY - X\mu_Y - \mu_X Y + \mu_X\mu_Y] \\ &= E[XY] - \mu_Y E[X] - \mu_X E[Y] + \mu_X\mu_Y \\ &= E[XY] - \mu_X\mu_Y. \end{aligned} $$
由此立刻看出 $\operatorname{Cov}(X,X) = E[X^2] - \mu_X^2 = \operatorname{Var}(X)$,即變異數是共變異數的對角特例。共變異數具雙線性性:對常數 $a,b$ 與隨機變數 $Z$,
$$\operatorname{Cov}(aX + bZ,\ Y) = a\operatorname{Cov}(X,Y) + b\operatorname{Cov}(Z,Y),$$
且 $\operatorname{Cov}(X, c) = 0$ 對任意常數 $c$。這個雙線性性質直接導出和的變異數公式:
$$\operatorname{Var}(X+Y) = \operatorname{Var}(X) + \operatorname{Var}(Y) + 2\operatorname{Cov}(X,Y).$$
推廣到 $n$ 個變數,$\operatorname{Var}\!\big(\sum_i X_i\big) = \sum_i \operatorname{Var}(X_i) + 2\sum_{i<j}\operatorname{Cov}(X_i, X_j)$。整組變數的二階結構可整理成共變異數矩陣 $\Sigma$,其中 $\Sigma_{ij} = \operatorname{Cov}(X_i, X_j)$;$\Sigma$ 恆為對稱半正定矩陣,因為對任意常數向量 $a$,$a^\top \Sigma a = \operatorname{Var}(a^\top X) \ge 0$。
相關係數與量綱不變性
共變異數的數值受量綱影響(把公分換成公尺,數值就變),難以橫向比較。Pearson 相關係數將其標準化:
$$\rho_{X,Y} = \frac{\operatorname{Cov}(X,Y)}{\sigma_X \sigma_Y}.$$
由 Cauchy–Schwarz 不等式 $\big(E[(X-\mu_X)(Y-\mu_Y)]\big)^2 \le E[(X-\mu_X)^2]\,E[(Y-\mu_Y)^2]$,可證 $-1 \le \rho \le 1$。等號成立($|\rho| = 1$)當且僅當 $Y$ 幾乎必然是 $X$ 的線性函數 $Y = aX + b$。務必記住:$\rho$ 只捕捉線性關聯,對非線性依賴可能完全失靈。
獨立 vs. 不相關:一個關鍵的不對稱
$X$ 與 $Y$ 獨立的定義是聯合分布可分解為邊際之積:
$$f_{X,Y}(x,y) = f_X(x)\,f_Y(y)\quad\text{對所有 } (x,y).$$
若獨立,則對任意(可積)函數 $g, h$ 有 $E[g(X)h(Y)] = E[g(X)]\,E[h(Y)]$。取 $g, h$ 為恆等函數即得 $E[XY] = E[X]E[Y]$,故 $\operatorname{Cov}(X,Y) = 0$。
獨立 $\Rightarrow$ 不相關,但反之不成立。 不相關只約束了一階耦合(線性部分),獨立卻要求所有階的耦合都消失。一個經典反例:令 $X \sim \mathcal{N}(0,1)$,$Y = X^2$。則
$$\operatorname{Cov}(X,Y) = E[X^3] - E[X]E[X^2] = 0 - 0\cdot 1 = 0,$$
因為標準常態的奇數階動差為零。$X$ 與 $Y$ 不相關,卻顯然高度相依($Y$ 完全由 $X$ 決定)。唯一的重要例外是聯合常態分布:此時不相關 $\Leftrightarrow$ 獨立,因為多元常態的依賴結構完全由 $\Sigma$ 決定。
定量小範例:擲兩枚硬幣的耦合
設一次試驗擲兩枚公平硬幣。令 $X$ 為「正面總數」,$Y$ 為「第一枚是否為正面」(正面記 1,反面記 0)。四個等機率結果 $\{HH, HT, TH, TT\}$ 各佔 $1/4$。列出聯合分布:
| 結果 | 機率 | $X$ | $Y$ | $XY$ |
|---|---|---|---|---|
| HH | 1/4 | 2 | 1 | 2 |
| HT | 1/4 | 1 | 1 | 1 |
| TH | 1/4 | 1 | 0 | 0 |
| TT | 1/4 | 0 | 0 | 0 |
步驟 1:邊際期望值。 $$E[X] = \tfrac14(2+1+1+0) = 1,\qquad E[Y] = \tfrac14(1+1+0+0) = \tfrac12.$$
步驟 2:交叉期望值。 $$E[XY] = \tfrac14(2 + 1 + 0 + 0) = \tfrac34.$$
步驟 3:共變異數。 $$\operatorname{Cov}(X,Y) = E[XY] - E[X]E[Y] = \tfrac34 - 1\cdot\tfrac12 = \tfrac14.$$
步驟 4:標準化為相關係數。 由 $\operatorname{Var}(X) = E[X^2] - 1 = \tfrac14(4+1+1+0) - 1 = \tfrac12$,$\operatorname{Var}(Y) = \tfrac12 - \tfrac14 = \tfrac14$,得
$$\rho_{X,Y} = \frac{1/4}{\sqrt{1/2}\sqrt{1/4}} = \frac{1/4}{1/(2\sqrt2)} = \frac{\sqrt2}{2} \approx 0.707.$$
正號合理:第一枚為正面時,正面總數傾向偏高。$X$ 與 $Y$ 顯然不獨立——$P(X=0, Y=1) = 0 \ne P(X=0)P(Y=1) = \tfrac14\cdot\tfrac12$。
素養提醒:相關不是因果
共變異數與相關係數只是聯合分布的二階摘要。高相關可能源自共同的潛在原因(混淆變數)、選擇偏誤,甚至純粹巧合。看到 $\rho$ 大就宣稱「$X$ 導致 $Y$」是統計推論最常見的謬誤;而看到 $\rho \approx 0$ 就斷言「兩者無關」同樣危險,因為非線性依賴會被線性度量漏掉。判斷因果需要設計(隨機化)或可辨識的結構假設,而非僅憑相關數值。
深入探討(研究所視角)
在母體層次,$\operatorname{Cov}(X,Y)$ 是固定參數;實務上我們以樣本估計它。樣本共變異數
$$\hat{\sigma}_{XY} = \frac{1}{n-1}\sum_{i=1}^{n}(X_i - \bar X)(Y_i - \bar Y)$$
採用 $n-1$ 而非 $n$ 作為分母,使其成為無偏估計量(Bessel 校正補償了用 $\bar X, \bar Y$ 取代未知母體均值所損失的自由度)。在 i.i.d. 且四階動差有限的條件下,樣本相關係數 $\hat\rho$ 是 $\rho$ 的一致估計量,且滿足中央極限定理式的漸近常態性。由於 $\hat\rho$ 的抽樣分布在 $\rho \to \pm 1$ 附近高度偏斜,Fisher 的 $z$ 轉換 $z = \tfrac12\ln\frac{1+\hat\rho}{1-\hat\rho} = \operatorname{arctanh}(\hat\rho)$ 是經典的變異數穩定化技巧,使 $z$ 近似常態且變異數約為 $1/(n-3)$,獨立於 $\rho$——這正是建構相關係數信賴區間的標準做法。提醒:信賴區間描述的是「重複抽樣下涵蓋真值的長期頻率」,而非「真值落在此區間的機率」。
從估計理論看,多元常態下的共變異數矩陣 $\Sigma$ 有兩條經典路徑。最大概似估計(MLE) 給出 $\hat\Sigma_{\text{MLE}} = \frac1n \sum_i (X_i-\bar X)(X_i-\bar X)^\top$,它是漸近有效的(達到 Cramér–Rao 下界),但在小樣本下有偏。動差法(MoM) 則直接以樣本動差匹配理論動差,計算簡便但效率通常不及 MLE。當維度 $p$ 與樣本數 $n$ 同階成長時,$\hat\Sigma$ 變得病態(特徵值嚴重偏離真值),此時 Ledoit–Wolf 的收縮估計——把 $\hat\Sigma$ 朝結構化目標(如純量乘單位矩陣)做凸組合——能顯著降低均方誤差,是高維統計的標準工具。
貝氏對應為共變異數估計提供了自然的正則化。多元常態的共軛先驗是 Inverse-Wishart 分布(或對精度矩陣 $\Sigma^{-1}$ 用 Wishart);後驗均值本質上就是樣本共變異數與先驗尺度矩陣的加權平均,先驗強度愈大、收縮愈多,與頻率派的收縮估計殊途同歸。
更前沿地,純線性的共變異數無法捕捉複雜依賴,於是有了多種推廣:Spearman / Kendall 等秩相關對單調非線性關係穩健;互資訊 $I(X;Y) = \operatorname{KL}\!\big(f_{X,Y} \,\|\, f_X f_Y\big)$ 度量任意形式的統計依賴,當且僅當獨立時為零;距離相關(distance correlation)則為零當且僅當完全獨立,彌補了 Pearson $\rho=0$ 不蘊含獨立的缺陷。在機器學習中,Gaussian 圖模型利用「精度矩陣 $\Sigma^{-1}$ 的零元素對應條件獨立」這個性質,以 graphical lasso 在高維下估計稀疏依賴網路。在因果推論中,更要嚴格區分邊際依賴與條件依賴:Simpson 悖論顯示邊際正相關可能在每個分層內翻轉為負,而依賴結構(透過 do-calculus 與因果圖判讀)才是辨識因果效應的關鍵——共變異數本身永遠只是觀察層次的關聯摘要,不等於介入後的反應。