
辛普森悖論的深入剖析:當分層與聚合給出相反結論
從加權平均的代數機制到因果識別、標準化估計與雙重穩健推論
從聚合到分層:悖論的本質
當我們把多個子群體的資料「合併」起來計算一個整體關聯,常會得到與每個子群體內部完全相反的結論。這就是辛普森悖論(Simpson's Paradox):在每一層都成立的方向,在加總後翻轉了。直覺上令人困惑,但其本質並非弔詭的機率現象,而是「加權平均的順序」與「混淆變數的分佈不均」共同作用的代數必然結果。本篇假設讀者已熟悉條件機率、期望值與線性迴歸,目標是把悖論拆解到可推導、可估計的層次。
考慮一個二元處理 $X\in\{0,1\}$、二元結果 $Y\in\{0,1\}$,以及一個分層變數 $Z$。整體關聯由邊際機率 $P(Y=1\mid X)$ 描述,而分層關聯由 $P(Y=1\mid X,Z)$ 描述。悖論的形式定義是:存在某種方向(例如「正向」),使得對所有層 $z$ 都有
$$P(Y=1\mid X=1, Z=z) > P(Y=1\mid X=0, Z=z),$$
但邊際上卻反向:
$$P(Y=1\mid X=1) < P(Y=1\mid X=0).$$
關鍵在於邊際機率是分層機率對 $Z$ 的加權平均,而兩個處理組的權重 $P(Z=z\mid X)$ 並不相同。
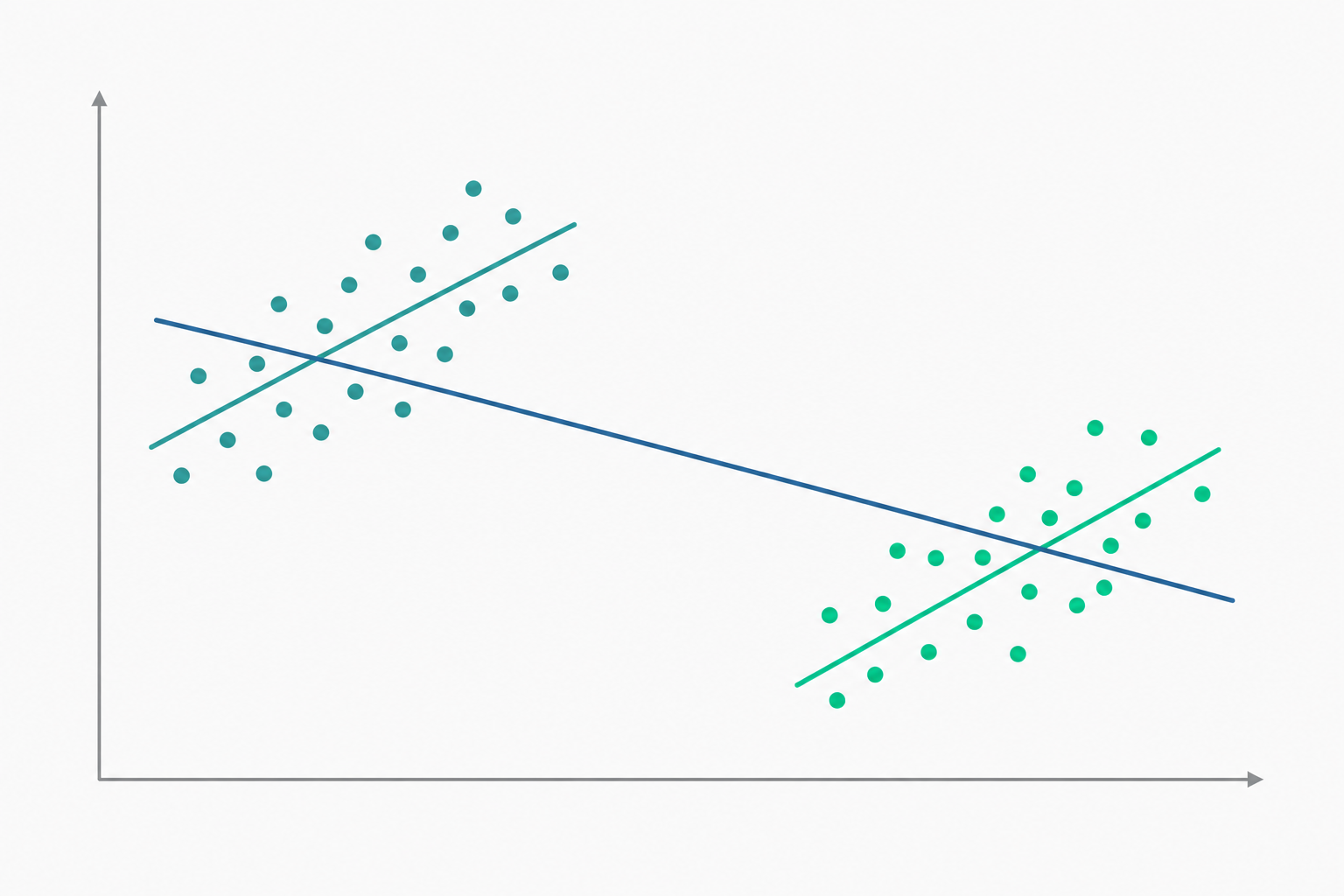
加權平均的代數機制
把邊際機率展開為全機率公式:
$$P(Y=1\mid X=x)=\sum_{z} P(Y=1\mid X=x, Z=z)\,P(Z=z\mid X=x).$$
令 $p_{xz}=P(Y=1\mid X=x,Z=z)$ 為分層成功率,$w_{xz}=P(Z=z\mid X=x)$ 為該處理組內分層的權重。邊際成功率即為 $\bar p_x=\sum_z p_{xz} w_{xz}$。即使對每一層都有 $p_{1z}>p_{0z}$,兩組所用的權重向量 $\{w_{1z}\}$ 與 $\{w_{0z}\}$ 不同,因此 $\bar p_1$ 與 $\bar p_0$ 的比較可能翻轉。
直觀地說:若 $X=1$ 的個體大量集中在「本來成功率就低」的層,而 $X=0$ 的個體集中在「本來成功率就高」的層,那麼處理組的優勢會被不利的權重稀釋掉。悖論的成立條件本質上要求 $Z$ 同時與 $X$ 相關($w_{1z}\neq w_{0z}$)且與 $Y$ 相關($p_{xz}$ 隨 $z$ 變化)——這正是混淆變數(confounder)的定義。換言之,辛普森悖論是混淆現象的極端可視化案例。
定量小範例
設兩層 $Z\in\{A,B\}$,分層成功率與權重如下。處理組 $X=1$ 在每層都優於 $X=0$:
| 層 | $p_{1z}$ | $p_{0z}$ | $w_{1z}$ | $w_{0z}$ |
|---|---|---|---|---|
| A | $0.90$ | $0.80$ | $0.10$ | $0.80$ |
| B | $0.40$ | $0.30$ | $0.90$ | $0.20$ |
每層內 $X=1$ 都高出 $0.10$。計算邊際成功率:
$$\bar p_1 = 0.90\times 0.10 + 0.40\times 0.90 = 0.09 + 0.36 = 0.45.$$
$$\bar p_0 = 0.80\times 0.80 + 0.30\times 0.20 = 0.64 + 0.06 = 0.70.$$
於是邊際上 $\bar p_1=0.45 < \bar p_0=0.70$,整體看來處理「有害」,與每層結論恰好相反。差距來源很清楚:$X=1$ 的樣本九成落在低成功率的 B 層,$X=0$ 的樣本八成落在高成功率的 A 層。權重的不對稱完全主導了邊際比較。
因果視角:該看哪一個數字?
統計素養的核心問題不是「悖論為何發生」,而是「哪個結論是對的」。答案取決於因果結構,而非資料本身。若 $Z$ 是處理之前就決定、且同時影響 $X$ 與 $Y$ 的混淆變數(例如年齡、疾病嚴重度),則正確的因果效應應「校正 $Z$」,即看分層結論。對應的標準化(standardization)估計量為
$$P(Y=1\mid do(X=1)) = \sum_z P(Y=1\mid X=1, Z=z)\,P(Z=z),$$
注意此處權重改用邊際分佈 $P(Z=z)$ 而非組內分佈 $P(Z=z\mid X)$,這正是 $do$-算子切斷 $Z\to X$ 箭頭的數學表現。
反之,若 $Z$ 是處理之後才發生、位於因果路徑上的中介變數(mediator),則校正 $Z$ 會錯誤地阻斷一部分真實效應,此時應看邊際結論。同一組數字,不同的因果圖(DAG),會導出相反的「正確答案」——這是辛普森悖論留給我們最深刻的教訓:資料無法自己告訴你該不該分層,必須引入因果假設。把相關當因果、或機械地「總是分層」都是錯的。
與信賴區間及顯著性的關係
值得強調:辛普森悖論是關於點估計方向的現象,與抽樣誤差無關。即使每一層與邊際的估計都極為精確、信賴區間極窄、$p$ 值極小,方向翻轉依然可能成立。換言之,加大樣本數無法消除悖論。誤以為「顯著」就代表「結論可信」是典型的統計素養陷阱——$p$ 值衡量的是「若無效應,觀察到此等或更極端資料的機率」,它不保證你校正了正確的變數,更不保證因果方向。一個校正了錯誤集合變數的迴歸,可以同時非常顯著且完全誤導。
深入探討(研究所視角)
從估計理論看,分層成功率 $\hat p_{xz}$ 是樣本比例,為 $p_{xz}$ 的最大概似估計(MLE)。在第 $z$ 層中,以二項概似 $L(p_{xz})=p_{xz}^{s}(1-p_{xz})^{n-s}$ 對對數概似求導得 $\hat p_{xz}=s/n$,且由中央極限定理 $\sqrt{n_{xz}}(\hat p_{xz}-p_{xz})\xrightarrow{d}\mathcal N\big(0, p_{xz}(1-p_{xz})\big)$。標準化估計量 $\hat\psi=\sum_z \hat p_{1z}\hat w_z$(其中 $\hat w_z=\hat P(Z=z)$)是平滑函數的線性組合,依 delta method 仍為漸近常態,其漸近變異數可由各層變異數加權求和,並可用 sandwich 估計量取得穩健標準誤。這提供了對「校正後效應」做區間估計與假設檢定的嚴謹基礎。
辛普森悖論的代數可推廣到連續情形:在線性迴歸中,遺漏一個與 $X$ 相關的變數 $Z$ 會產生遺漏變數偏誤,迴歸係數的偏移量為 $\beta_{X}^{\text{naive}}-\beta_X = \beta_Z\cdot\delta$,其中 $\delta$ 是 $Z$ 對 $X$ 迴歸的斜率。當 $\beta_Z\cdot\delta$ 的量級超過真實 $\beta_X$ 且符號相反時,係數符號翻轉,這正是連續版的辛普森悖論,與 Frisch–Waugh–Lovell 定理對「偏迴歸係數即殘差迴歸」的刻畫一脈相承。
在因果推論的現代框架下,Pearl 的後門準則(back-door criterion)給出何時分層能識別因果效應的圖論條件:若集合 $Z$ 阻斷 $X$ 與 $Y$ 之間所有後門路徑且不含 $X$ 的後代,則 $do$-標準化公式可識別。逆機率加權(IPW)提供另一種等價估計:以傾向分數 $e(z)=P(X=1\mid Z=z)$ 加權,$\hat\tau_{\text{IPW}}=\frac1n\sum_i\big(\frac{X_iY_i}{\hat e(Z_i)}-\frac{(1-X_i)Y_i}{1-\hat e(Z_i)}\big)$,在傾向分數模型正確時為一致估計。更進一步,雙重穩健(doubly robust)估計量與目標最大概似估計(TMLE)只要結果模型或傾向分數模型其一正確即一致,並達到半參數效率界,是當代將辛普森悖論問題自動化處理的主流工具。
貝氏對應則把各層成功率視為帶 Beta 先驗的隨機量,後驗 $p_{xz}\mid \text{data}\sim\text{Beta}(\alpha+s,\beta+n-s)$,可進一步用階層模型(hierarchical model)對 $\{p_{xz}\}$ 加上共同超先驗,達成跨層的部分匯聚(partial pooling),在層內樣本稀疏時穩定估計、緩解過度分層導致的高變異。最後,與機器學習的連結在於:高維混淆下傾向分數與結果模型可用隨機森林或神經網路估計,配合 cross-fitting 的雙重機器學習(double/debiased machine learning)在弱條件下保留 $\sqrt n$ 收斂與有效推論——可視為辛普森悖論在演算法時代的延伸解法。