
計數模型動物園:零膨脹、離散結構與階層 GLM
當 Poisson 與負二項都解釋不了那一半「永遠是零」的學生,進階計數模型如何把資料的真實生成機制建對
為什麼一半的學生「永遠是零」,模型卻假裝看不見?
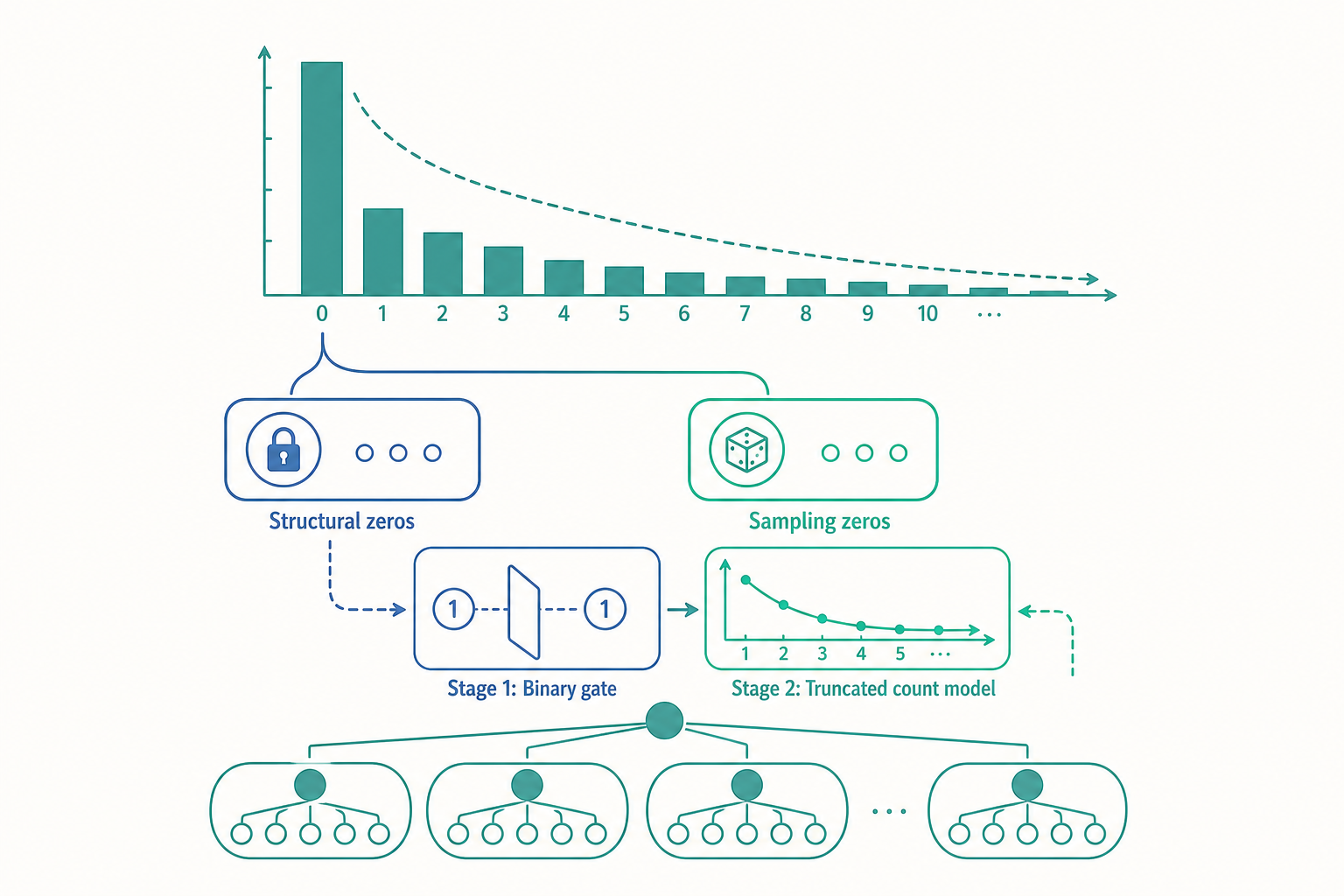
你已經知道計數資料該先想 Poisson、變異太大就換負二項。但真正分析 Uedu 的討論區發文數時,你會撞上一個 Poisson 與負二項都解釋不了的現象:發文數為 0 的學生占了整整六成,而且這六成裡頭其實藏著兩種完全不同的人。一種是「這週剛好沒空、但本來會發文」的潛在參與者;另一種是「根本不打算用討論區、無論如何都不會發文」的結構性退出者。標準計數模型把這兩種零混為一談,於是它對零的預測總是差一截——不是高估就是低估,殘差圖上 0 附近永遠鼓起一個它配不平的山丘。
這篇進階文章不再重述連結函數與率比,而是要帶你進入計數模型真正棘手、也真正有趣的地帶:離散度(dispersion)的本質、零膨脹與障礙模型的分工、診斷該怎麼做,以及把這些觀念延伸到階層資料的 GLMM。換句話說,當入門篇教你「選對分布家族」,這篇要教你「在分布家族之內,如何把資料的真實生成機制建對」。
離散度不是一個數字,而是一種結構
入門篇把過度離散(overdispersion)講成「變異大於平均」,並給了兩個處方:負二項與 quasi-Poisson。但這兩者修正的是不同的東西,混用會出錯。
負二項(Negative Binomial, NB)假設每個觀測背後有一個 Gamma 分布的潛在率(latent rate),把個體異質性(unobserved heterogeneity)顯式地模型化。它推得的變異是二次型:
$$\mathrm{Var}(Y)=\mu+\alpha\mu^2.$$
quasi-Poisson 則完全不碰分布,只把變異膨脹成線性型:
$$\mathrm{Var}(Y)=\phi\,\mu,\qquad \phi>1.$$
差別在哪?線性型假設「離散倍數固定」,二次型假設「離散隨平均加速放大」。對長尾嚴重的社群資料(少數超活躍使用者拉爆尾巴),變異往往隨 $\mu$ 平方成長,NB 比 quasi-Poisson 更貼合。文獻上這兩種還細分為 NB1(變異 $\mu+\alpha\mu$,線性)與 NB2(變異 $\mu+\alpha\mu^2$,二次),多數軟體的 glm.nb 預設是 NB2。
更重要的提醒:過度離散不必然代表「需要更花俏的分布」,它常常是模型設定錯誤的徵兆。 漏掉一個重要的解釋變數、忽略非線性關係、或忽略階層結構(同一課程的學生彼此相關),都會在殘差裡偽裝成過度離散。所以看到離散度比值大於 1,第一步不是急著換 NB,而是先問:我是不是漏了什麼?
兩種零,兩種模型:零膨脹 vs 障礙
回到開頭那六成的零。處理「零太多」有兩個主流框架,它們對「零是怎麼來的」有截然不同的假設。
零膨脹模型(Zero-Inflated, ZIP/ZINB) 假設零來自兩個來源的混合。一部分是「結構性零」——一群人以機率 $\pi$ 永遠輸出零;另一部分是「抽樣零」——剩下的人服從一個計數分布(Poisson 或 NB),而這個分布本身也可能吐出零。其機率質量函數為:
$$ P(Y=0)=\pi+(1-\pi)\,f(0),\qquad P(Y=k)=(1-\pi)\,f(k)\;\;(k\ge 1), $$
其中 $f$ 是底層計數分布。模型同時配適兩條迴歸:一條 logistic 預測「是否屬於結構性零那群」,一條 Poisson/NB 預測「屬於可參與那群的人發幾篇」。
障礙模型(Hurdle Model) 的哲學不同:它認為「從 0 跨到 1」與「已經發文後發幾篇」是兩個獨立的決策階段。第一階段用一個二元模型決定「是否跨過障礙」(發不發文),第二階段用一個截斷在零以上(zero-truncated)的計數模型決定「跨過後發幾篇」。關鍵差異是:障礙模型裡所有的零都來自第一階段,計數階段不再產生任何零;零膨脹模型則允許計數階段也吐出零。
該選哪個?問一個實質問題:你的零有沒有可能來自「想參與但這次剛好沒發」的抽樣波動?若有(例如忙碌但仍在群體中的學生),ZINB 較合理;若你認為「只要發過一次就代表跨過了某道門檻,沒發就是完全沒跨」,hurdle 更乾淨。教育行為資料兩者都常見,建議兩個都配,比較 AIC 與對零的預測校準。
看一個例子:分辨「結構零」與「抽樣零」
假設我們對一週發文數配適了 ZIP,結果是:
零膨脹部分(logistic,預測屬於結構零群的機率):
$$\operatorname{logit}(\hat\pi)=0.20-1.10\,\text{(是否啟用 AIDA)}.$$
計數部分(Poisson,給定屬於可參與群):
$$\log\hat\mu=0.30+0.45\,\text{(是否啟用 AIDA)}.$$
對一位未啟用 AIDA 的學生:結構零機率 $\hat\pi=\dfrac{1}{1+e^{-0.20}}\approx 0.55$。也就是說,模型估計約 55% 的未啟用者根本不打算碰討論區。
對一位啟用 AIDA 的學生:$\operatorname{logit}(\hat\pi)=0.20-1.10=-0.90$,$\hat\pi=\dfrac{1}{1+e^{0.90}}\approx 0.29$。啟用 AIDA 讓「完全退出」的機率從 55% 降到 29%。
再看計數部分,給定屬於可參與群,啟用者的期望發文數是 $e^{0.30+0.45}=e^{0.75}\approx 2.12$ 篇,未啟用者是 $e^{0.30}\approx 1.35$ 篇。
把兩段合起來,AIDA 的整體效果被拆成兩個機制:它既把人從「結構性退出」拉回參與群(降低 $\pi$),又讓已參與者發得更多(提高 $\mu$)。 這正是單純 Poisson/NB 看不見的洞察——它只會給你一個混在一起的平均效果,而 ZIP 告訴你效果是「拉人進場」還是「催人多發」,這對教學介入的設計天差地別。
GLM 的殘差該怎麼看
OLS 的殘差是 $y-\hat y$,常態又等變異,畫個散布圖就能診斷。GLM 不行:應變數離散、變異隨平均改變,原始殘差幾乎沒法判讀。GLM 用兩種標準化殘差。
Pearson 殘差 把殘差除以該點的標準差估計:
$$r_i^{P}=\frac{y_i-\hat\mu_i}{\sqrt{V(\hat\mu_i)}}.$$
它們的平方和正是 Pearson $\chi^2$ 統計量,除以殘差自由度就是入門篇提過的離散度比值。
Deviance 殘差 則把每個觀測對總 deviance 的貢獻開根號、保留符號:
$$r_i^{D}=\operatorname{sign}(y_i-\hat\mu_i)\sqrt{d_i},\qquad D=\sum_i d_i.$$
對配適良好的模型,deviance 殘差近似常態,因此可以拿來畫 Q–Q 圖、找離群點。實務經驗是:deviance 殘差比 Pearson 殘差更接近常態,做圖診斷優先用它。
但對計數模型,最有說服力的診斷其實不是殘差圖,而是 rootogram(根圖)。它把「觀測到的各計數值次數」與「模型預測的次數」疊在一起(縱軸取平方根以壓抑大數),一眼就能看出模型在哪些計數值上系統性地高估或低估。零膨脹的典型特徵就是:在 $k=0$ 處觀測值遠高於 Poisson 預測,而在 $k=1,2$ 處被低估——根圖會清楚顯示 0 那根「吊」在預測曲線下方一大截。看到這個形狀,就知道該換 ZIP/hurdle 了。
分離(separation):邏輯斯迴歸的隱形地雷
換個方向談一個 logistic 迴歸特有、卻常被忽略的陷阱。當某個預測變數(或其線性組合)能完美地把 0 與 1 分開時,會發生完全分離(complete separation)。例如「凡是出席率 100% 的學生全部通過、低於 100% 的全部沒通過」。這時最大概似估計會試圖把對應係數推向 $\pm\infty$——因為把斜率調得越陡,概似就越大,永遠沒有極大值。
徵兆是:某個係數的估計值與標準誤都大得離譜(係數 15、標準誤 8000),$p$ 值接近 1,模型卻號稱「完美配適」。很多人誤以為這是強效果,其實是估計崩潰。
解法不是刪資料,而是換估計方法。Firth 懲罰概似(penalized likelihood) 在 score 方程式加一個 Jeffreys 先驗導出的修正項,保證估計有限且減少小樣本偏誤,是目前處理分離的標準作法。貝氏取向則可對係數加一個弱資訊先驗(如 Cauchy(0, 2.5))達到類似的正則化效果。這在樣本小、類別不平衡的教育資料(例如「退選」這種罕見事件)裡特別常見,值得警覺。
當資料有階層:GLMM 的隨機效果
Uedu 的資料幾乎都有巢狀結構:同一位學生的多週發文彼此相關、同一門課的學生共享授課風格。把它們當成獨立觀測丟進 GLM,會嚴重低估標準誤——這跟過度離散是同一個病根的不同表現。廣義線性混合模型(GLMM) 在線性預測子裡加入隨機效果來吸收這種相關:
$$g(\mu_{ij})=\mathbf{x}_{ij}^\top\boldsymbol{\beta}+u_j,\qquad u_j\sim\mathcal{N}(0,\sigma_u^2),$$
其中 $u_j$ 是第 $j$ 群(如課程)的隨機截距,$\sigma_u^2$ 衡量群間異質性。它同時也提供了一條優雅看待過度離散的路徑:在 Poisson-lognormal 模型裡,個體層的隨機效果 $u_i$ 直接吸收掉多餘變異,效果類似負二項但更有彈性。
代價是估計變難。GLMM 的概似需要對隨機效果積分,而這個積分通常沒有封閉解:
$$\ell(\boldsymbol{\beta},\sigma_u^2)=\sum_j \log\int \prod_i f(y_{ij}\mid u_j)\,\phi(u_j;\sigma_u^2)\,du_j.$$
實務上用 Laplace 近似 或 adaptive Gauss–Hermite quadrature 數值逼近這個積分;節點數越多越準但越慢。要特別小心的是:GLMM 的固定效果是條件解讀(conditional / subject-specific)——「在同一門課內、其他不變下」的效果,而不是 GLM 那種邊際解讀(marginal / population-averaged)。對非線性連結(logit、log),這兩種效果的數值不相等,條件效果通常比邊際效果更大。報告係數時務必講清楚是哪一種,否則讀者會誤讀效果量。
重點回顧
- 過度離散有結構之分:負二項是二次型變異($\mu+\alpha\mu^2$)、quasi-Poisson 是線性型($\phi\mu$);長尾社群資料多半偏二次型。看到離散先懷疑「漏變數/漏階層」,再考慮換分布。
- 零太多要分辨兩種零:零膨脹(ZIP/ZINB)容許計數階段也產生零、適合「想參與但這次沒發」;障礙模型把所有零歸給第一階段、計數階段截斷在零以上。兩者都配、比 AIC 與零的校準。
- GLM 診斷用 deviance 殘差做 Q–Q 圖、用 rootogram 看計數配適;0 那根吊在預測下方就是零膨脹的訊號。
- logistic 迴歸的完全分離會讓係數爆向無窮、標準誤巨大,用 Firth 懲罰概似或弱資訊先驗處理,別刪資料。
- 資料有巢狀結構就用 GLMM;固定效果是條件(subject-specific)而非邊際解讀,對非線性連結兩者不相等,報告時要講明。
深入探討(研究所視角)
離散度與相關的可交換性(exchangeability)。 過度離散、隨機效果、序列相關,在數學上其實是同一件事的不同切面:它們都讓 $\mathrm{Var}\!\left(\sum_i Y_i\right)$ 大於各自變異之和。這解釋了為什麼 Poisson-Gamma 混合(=負二項)、Poisson-lognormal 混合(=Poisson GLMM)、以及 quasi-likelihood 三者經常給出近似的點估計卻有不同的標準誤——它們對「相關從何而來」的假設不同。在追蹤資料(longitudinal)裡,廣義估計方程式(Generalized Estimating Equations, GEE) 提供了第四條路:它放棄完整概似,只指定一個「工作相關矩陣(working correlation)」,並用穩健的夾心估計量(sandwich estimator)
$$\widehat{\mathrm{Cov}}(\hat{\boldsymbol{\beta}})=\mathbf{B}^{-1}\mathbf{M}\mathbf{B}^{-1}$$
保證即使工作相關設錯,邊際效果的標準誤仍漸近正確。GEE 得到的是邊際(population-averaged)估計,與 GLMM 的條件估計形成互補——選哪個取決於你的科學問題是「群體平均效果」還是「個體內效果」。
零膨脹模型的辨識性陷阱。 ZIP/ZINB 把同一批解釋變數同時放進零膨脹部分與計數部分時,兩條迴歸可能爭奪同一份訊號,造成參數弱辨識(weak identifiability)、概似面平坦、優化不收斂或收斂到鞍點。Vuong 檢定常被用來比較 ZIP 與一般 Poisson,但近年文獻(Wilson, 2015)指出它對非巢狀模型的零膨脹比較並不適切,容易誤判。較穩健的作法是直接比較對零的後驗預測校準(posterior predictive check on the zero count),或改用障礙模型——因為 hurdle 把兩階段的參數完全分離(一個管零、一個管正計數、互不重疊),結構上避開了這種辨識難題,這也是許多計量經濟學者偏好 hurdle 的理由。
指數族離散參數的雙重角色。 入門篇的指數族形式 $f(y;\theta,\phi)=\exp\{[y\theta-b(\theta)]/a(\phi)+c(y,\phi)\}$ 裡,離散參數 $\phi$ 看似只是個尺度常數,但在進階建模裡它可以本身被建模。雙重 GLM(double GLM) 同時用兩個線性預測子分別建模平均與離散:$g_1(\mu)=\mathbf{x}^\top\boldsymbol\beta$ 與 $g_2(\phi)=\mathbf{z}^\top\boldsymbol\gamma$,讓「變異如何隨共變數變化」也成為可估計的科學問題。這在異質變異明顯的資料(例如不同課程的發文離散度本就不同)裡能大幅改善配適與標準誤的正確性,也是 GAMLSS(generalized additive models for location, scale and shape)這類「對分布每個參數都建模」框架的起點。把 $\phi$ 從固定常數釋放為可建模的對象,正是 GLM 從「建模平均」邁向「建模整個分布」的關鍵一步。