
為什麼問一千人就能猜中全台灣?抽樣與抽樣分布的推論魔法
從隨機抽樣、抽樣誤差到中央極限定理,看懂民調與信賴區間背後的數學
為什麼問幾千個人,就能猜中全台灣的想法?
每到選舉前夕,新聞總會出現這樣的標題:「民調顯示某候選人支持度 48%,誤差正負 3 個百分點。」你可能會困惑:全台灣有兩千多萬名選民,民調公司明明只訪問了一千多人,憑什麼敢說自己「猜」中了全體的想法?更神奇的是,他們不只給出一個數字,還能告訴你這個數字大概會偏差多少。
這背後的魔法,就是統計學裡最迷人也最核心的概念:抽樣(sampling)與抽樣分布(sampling distribution)。理解了它,你會發現「用一小撮樣本推論整個母體」不是隨便猜,而是建立在嚴謹數學基礎上的推論藝術。
母體、樣本與隨機抽樣
先把幾個名詞講清楚。我們真正想了解的整體對象,叫做母體(population),例如「全台灣的合格選民」。但母體通常太大、太貴、太難全部調查,於是我們從中抽出一部分來研究,這一部分就是樣本(sample)。
關鍵在於:樣本怎麼抽?如果你只在某個政黨的造勢晚會現場發問卷,得到的結果當然會偏向那個政黨——這叫做選樣偏誤(selection bias)。要讓樣本能代表母體,最重要的原則是隨機抽樣(random sampling):母體中的每一個個體,都有已知且非零的機率被抽中。最單純的版本是簡單隨機抽樣,就像把所有人的名字放進一個巨大的籤筒,閉著眼睛抽。
隨機抽樣的價值不在於「保證抽到的樣本和母體一模一樣」,而在於它讓我們能用機率語言去描述「樣本和母體可能差多少」。這正是下一個概念要回答的。
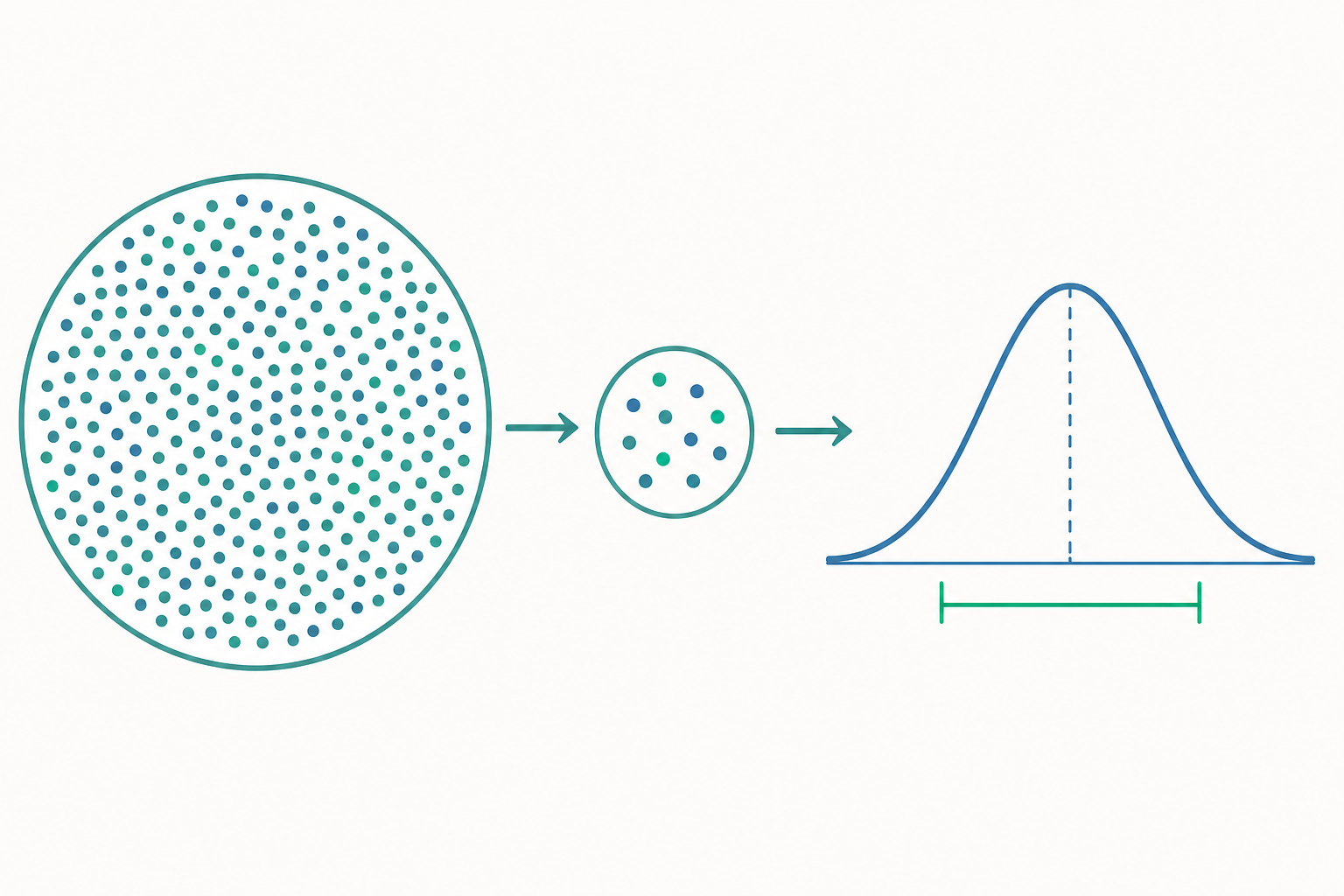
抽樣誤差:同一個母體,每次抽都不一樣
想像你有一鍋均勻攪拌的綠豆湯,想知道甜度。你舀一小匙嘗嘗——但每一匙的甜度都會略有差異,這種「因為只取了一部分而產生的天然波動」就是抽樣誤差(sampling error)。它不是錯誤,而是抽樣這件事本身無法避免的隨機性。
我們用樣本平均數 $\bar{x}$ 來估計母體平均數 $\mu$:
$$\bar{x}=\frac{1}{n}\sum_{i=1}^{n} x_i$$
如果重抽一次,會得到另一個略微不同的 $\bar{x}$。抽一千次,就有一千個 $\bar{x}$。這些 $\bar{x}$ 並非雜亂無章,它們本身會形成一個分布——這就是抽樣分布:某個統計量(如樣本平均數)在所有可能樣本下的機率分布。
中央極限定理:抽樣分布的鐘形奇蹟
抽樣分布最驚人的性質,由中央極限定理(Central Limit Theorem, CLT)揭示:只要樣本數 $n$ 夠大,不管母體原本長什麼形狀(偏態、雙峰都行),樣本平均數的抽樣分布都會趨近於常態分布(鐘形曲線),且:
$$\bar{x} \sim N\!\left(\mu,\ \frac{\sigma^2}{n}\right)$$
注意那個 $\frac{\sigma^2}{n}$。它告訴我們抽樣分布的標準差(稱為標準誤,standard error)是 $\dfrac{\sigma}{\sqrt{n}}$。樣本數 $n$ 越大,標準誤越小,$\bar{x}$ 就越穩定、越貼近 $\mu$。這就是「樣本越多越準」的數學根據——但請注意是 $\sqrt{n}$,要把誤差減半,樣本得增為四倍。
一個帶數字的小範例:算一個信賴區間
假設我們想估計某大學學生每週的平均自習時數。已知(由長年資料)母體標準差 $\sigma=6$ 小時。我們隨機抽出 $n=36$ 名學生,算出樣本平均數 $\bar{x}=14$ 小時。
步驟一:算標準誤。
$$SE=\frac{\sigma}{\sqrt{n}}=\frac{6}{\sqrt{36}}=\frac{6}{6}=1 \text{(小時)}$$
步驟二:選信賴水準。 取常用的 95%,對應的 $z$ 臨界值約為 $1.96$。
步驟三:算 95% 信賴區間。
$$\bar{x} \pm z \times SE = 14 \pm 1.96 \times 1 = 14 \pm 1.96$$
得到區間 $[12.04,\ 15.96]$ 小時。
我們可以說:「以這個方法建構的區間,有 95% 的把握涵蓋真正的母體平均數。」
這裡有個極常見的誤解要點破:95% 信賴區間不是指「母體平均數有 95% 的機率落在 12.04 到 15.96 之間」。母體平均數 $\mu$ 是一個固定值(雖然我們不知道它),它要嘛在區間內、要嘛不在,沒有機率可言。95% 指的是「方法的長期表現」——如果我們重複抽樣、重複造區間一百次,大約會有 95 個區間框住真值。機率是描述「程序」,不是描述「這一個特定區間」。
樣本量、誤差與成本的拔河
回到開頭的民調。「誤差正負 3%」其實就是上面那個 $z \times SE$ 算出來的誤差界限(margin of error)。想把誤差從 3% 縮到 1.5%,因為標準誤含 $\sqrt{n}$,樣本量得從約一千暴增到約四千。這就是民調公司在「精準度」與「調查成本」之間永遠在做的拔河。
理解抽樣,最終是培養一種統計素養:看到任何「根據調查」的數字,都會本能地問三件事——樣本是怎麼抽的(隨機嗎)?樣本多大(誤差多少)?這個結論有沒有把相關當成因果?這三個問題,能幫你過濾掉生活中大量似是而非的數據宣稱。
深入探討(研究所視角)
進入較嚴謹的層次,抽樣分布的核心是把統計量視為隨機變數,並研究其分布性質。對一個估計量 $\hat{\theta}$,我們關注三項性質:
- 不偏性(unbiasedness):$E[\hat{\theta}]=\theta$。樣本平均數 $\bar{x}$ 是 $\mu$ 的不偏估計量;而樣本變異數使用 $n-1$ 為分母,$s^2=\frac{1}{n-1}\sum (x_i-\bar{x})^2$,正是為了讓 $E[s^2]=\sigma^2$。這裡的 $n-1$ 即自由度(degrees of freedom)——因為 $\bar{x}$ 已從資料估出,限制了一個線性約束,獨立的偏差只剩 $n-1$ 個。
- 一致性(consistency):當 $n\to\infty$ 時 $\hat{\theta}\xrightarrow{p}\theta$,由大數法則(Law of Large Numbers)保證 $\bar{x}\xrightarrow{p}\mu$。一致性是漸近性質,不偏性是有限樣本性質,兩者並不互相蘊含。
- 有效性(efficiency):在不偏估計量中變異數最小者最有效,其下界由 Cramér–Rao 不等式給出。
最大概似估計(MLE)是構造估計量的通用法門:選擇使概似函數 $L(\theta)=\prod_i f(x_i;\theta)$ 最大化的 $\hat{\theta}$。MLE 在正則條件下具有漸近不偏、漸近常態與漸近有效性,是頻率學派推論的支柱。
當母體標準差 $\sigma$ 未知、需用 $s$ 取代時,統計量不再服從常態,而是服從自由度 $n-1$ 的 Student t 分布:$t=\frac{\bar{x}-\mu}{s/\sqrt{n}}$。t 分布的尾部較常態厚,反映了用 $s$ 估計 $\sigma$ 帶來的額外不確定性,小樣本時尤其明顯。
關於 p 值的常見誤解也值得在此釐清:p 值是「在虛無假設為真的前提下,觀察到當前或更極端結果的機率」,它不是「虛無假設為真的機率」,也不是「結果由偶然造成的機率」。此外,統計顯著(小 p 值)不等於實務重要,因此現代研究強調同時報告效果量(effect size),如 Cohen's $d=\frac{\bar{x}_1-\bar{x}_2}{s_p}$,以量化差異的實際大小,而非僅看是否「顯著」。
貝氏觀點則提供另一條路徑。它不把 $\theta$ 視為固定常數,而是賦予先驗分布,再由貝氏定理更新為後驗:
$$P(\theta\mid D)=\frac{P(D\mid \theta)\,P(\theta)}{P(D)}$$
如此得到的後驗分布可直接做出「$\theta$ 落在某區間的機率為 95%」這類陳述(稱為可信區間),這恰好是頻率學派信賴區間無法宣稱的。
最後,這些概念與機器學習深度相連:訓練/測試集劃分本質上是抽樣;bootstrap 重抽樣以樣本經驗分布逼近抽樣分布來估計不確定性;而模型的偏差—變異權衡(bias–variance tradeoff),正是估計量不偏性與有效性張力在預測情境下的延伸。理解抽樣分布,是理解一切資料推論的共同地基。