
多重插補做對了嗎:congeniality、收斂診斷與資料品質的進階視角
從跑得出結果,到跑得對結果——深入 MICE 收斂、補幾套的 FMI 法則、多層插補陷阱,以及預測任務與測量誤差的不同遊戲規則
你照著教科書跑了多重插補,但補出來的結果可信嗎?
你已經知道遺漏分 MCAR/MAR/MNAR,也知道該用多重插補(multiple imputation, MI)而非直接刪除。於是你打開 R 的 mice 套件,設好 m=20,按下執行,跑出一份漂亮的合併結果。問題來了:你怎麼知道這份插補本身是「跑對的」? 鏈式方程收斂了嗎?$m=20$ 夠不夠?插補模型和你的分析模型「合得來」嗎?如果分析涉及多層結構(學生巢套在班級裡),把這個結構忽略掉的插補會悄悄造成什麼偏誤?而如果你的目標根本不是統計推論、而是訓練一個預測模型,那一整套 Rubin 規則還適用嗎?
入門篇告訴你「該做什麼」,這篇要回答「怎麼做才不會做錯」——把多重插補從一個黑盒子,變成一套你能診斷、能調校、能信任的工具。我們也會把視野從「遺漏值」這一個點,拉開到「資料品質」這整個面,看看遺漏與測量誤差如何交纏。
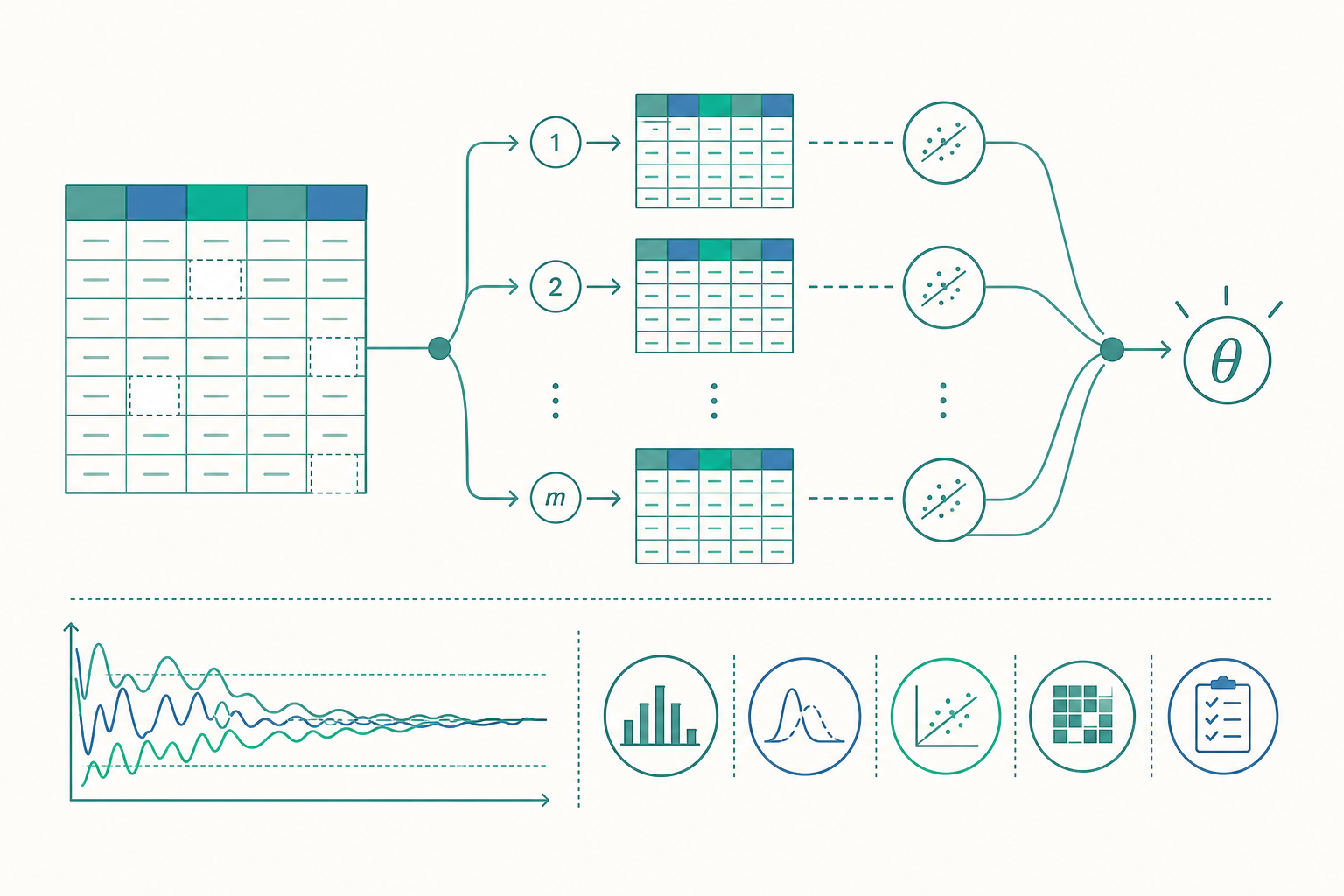
congeniality:插補模型與分析模型必須「合得來」
入門篇提過「插補模型要相容於分析模型」,但這句話背後有一個深刻的理論名詞——congeniality(相容性/同源性),由 Xiao-Li Meng 在 1994 年正式提出。它指的不只是「別漏掉交互項」這種操作層面的提醒,而是一個關於「兩個模型是否來自同一個聯合分布」的數學條件。
直覺是這樣:多重插補有一個獨特性質——插補者(imputer)與分析者(analyst)可以是不同的人。資料中心可以先用一個豐富的插補模型補好缺漏、釋出 $m$ 套完整資料,下游無數研究者再各自跑各自的分析。這種分工只有在「插補模型至少和分析模型一樣豐富」時才安全。若插補模型比分析模型更貧乏(uncongenial),會出兩種典型問題:
- 插補模型遺漏了分析需要的關聯:例如插補時沒放入「動機 $\times$ 性別」交互項,但分析要估這個交互效果。補出來的值不帶這層關聯,估計被往零拉。
- 插補模型遺漏了輔助變數:某個強預測缺漏的變數沒進插補模型,MAR 的支撐就垮了。
反過來,插補模型比分析模型更豐富通常是安全甚至有益的——這正是「插補時納入輔助變數」的理論依據。一個實務鐵則:插補模型應該是分析模型的超集(superset)。把所有結果變數(是的,包括依變數 $Y$!很多人怕「用 $Y$ 補自變數」會作弊,但在 MI 框架下這是必須的,否則會系統性削弱變數間關聯)、所有交互項、所有非線性轉換、所有輔助變數都放進去。
congeniality 的一個微妙後果是:當插補與分析不相容時,Rubin 變異公式 $T=\bar U+(1+1/m)B$ 可能高估也可能低估真實變異——它不再保證是「保守」的。這就是為什麼我們不能只盯著輸出的標準誤,而要回頭檢查插補模型本身。
MICE 真的收斂了嗎:鏈式方程的診斷
入門篇提到 MICE(鏈式方程多變量插補)這個主流引擎:對每個有缺的變數,輪流以其餘變數為預測子建條件模型,迭代抽樣。但 MICE 有一個常被忽略的事實——它是一個吉布斯抽樣(Gibbs sampler)式的迭代過程,需要「燒入(burn-in)」並達到平穩分布,而不是一跑就好。
每一次「迭代」會把所有有缺變數各更新一輪。一開始的補值受隨機初始化影響,要跑若干輪後,鏈才會「忘記」起點、進入平穩分布。診斷收斂的標準做法是看 trace plot:把每個變數補值的「平均」與「標準差」對迭代次數作圖,畫出 $m$ 條鏈。判讀原則:
- 健康:$m$ 條鏈彼此交織纏繞、沒有明顯趨勢或週期,像一團水平的毛線。
- 未收斂:鏈持續上升或下降(還沒到平穩)、或不同鏈長期分層不交會(需要更多迭代或插補模型有問題)。
預設常見的迭代數是 5–10,但對高遺漏比例或變數間強相關的資料,可能需要 20–50 輪。MICE 還有一個理論隱憂:它指定的是一組條件分布,而這組條件分布未必對應到任何合法的聯合分布(這叫 incompatibility,與前面的 congeniality 是不同概念)。實務上若條件模型設定合理,這個問題影響通常很小,但它解釋了為什麼 MICE 偶爾會行為怪異——例如補值在兩個極端間震盪不收斂。遇到時,檢查是否有變數幾乎被其他變數完美決定,或加上適當的限制(如把比例限制在 $[0,1]$)。
到底要補幾套:從「5 套夠了」到 FMI 法則
老教科書常說 $m=5$ 就夠。這個建議來自 Rubin 早期的計算:MI 的相對效率約為 $\left(1+\frac{\lambda}{m}\right)^{-1}$,其中 $\lambda$ 是遺漏資訊比例(fraction of missing information, FMI)。在 $\lambda=0.3$、$m=5$ 時效率約 $94\%$,看起來確實夠。
但這只說對了一半。效率高不代表結果穩定。 點估計或許用 $m=5$ 就八九不離十,但「標準誤、$p$ 值、信賴區間寬度」這些對 $B$(組間變異)敏感的量,在小 $m$ 下本身帶有很大的蒙地卡羅誤差——你今天跑 $m=5$ 得到 $p=0.04$,換個亂數種子再跑可能變 $p=0.06$。對需要做正式假設檢定、或結論卡在顯著邊緣的研究,這種不穩定是不可接受的。
現代建議(Graham 等人、von Hippel)是讓 $m$ 隨 FMI 增加,一個常被引用的經驗法則是 $m \approx 100\lambda$(FMI 為 0.3 就用 $m\approx 30$,0.5 就用 $m\approx 50$)。由於計算成本早已不是問題,許多人乾脆直接用 $m=20$ 到 $50$ 作為安全預設。von Hippel 還提出「兩階段法」:先小 $m$ 估出 FMI,再據此決定最終 $m$。重點觀念是:$m$ 不是越省越好,它直接決定你推論的可重複性。
動手算一下:m 不同,蒙地卡羅誤差差多少
承接 FMI $\lambda$ 與組間變異 $B$ 的關係。MI 點估計 $\bar Q$ 的蒙地卡羅標準誤(不同亂數種子間的抖動)大致正比於 $\sqrt{B/m}$。假設真實 $B=0.0025$(即補值間標準差 $\sqrt{B}=0.05$):
- $m=5$:蒙地卡羅 SE $\approx \sqrt{0.0025/5}=\sqrt{0.0005}\approx 0.0224$。
- $m=20$:$\approx \sqrt{0.0025/20}=\sqrt{0.000125}\approx 0.0112$。
- $m=50$:$\approx \sqrt{0.0025/50}=\sqrt{0.00005}\approx 0.0071$。
從 $m=5$ 到 $m=50$,純粹由「補幾套」造成的點估計抖動縮小到約三分之一($0.0224 \to 0.0071$)。更關鍵的是對 $B$ 本身的估計:$B$ 是用 $m$ 個值算的樣本變異數,其估計的相對標準誤約為 $\sqrt{2/(m-1)}$。$m=5$ 時這是 $\sqrt{2/4}\approx 0.71$——也就是說你對「組間變異」的估計本身帶有 $71\%$ 的相對誤差!$m=50$ 時降到 $\sqrt{2/49}\approx 0.20$。這就是為什麼依賴 $B$ 的標準誤與 $p$ 值,在小 $m$ 下如此不穩。結論很清楚:只要你關心推論而非僅僅點估計,就別吝嗇 $m$。
多層資料的隱形陷阱:把班級結構補平了
教育資料幾乎都是巢狀的:學生在班級裡、班級在學校裡。當這類資料有缺,一個極常見的錯誤是——用忽略層級結構的「單層插補」去補多層資料。
假設你的分析是多層模型(multilevel model),關心班級層的隨機效果(例如「班級平均動機」的變異)。若你用一個普通的單層 MICE 去補學生層的缺漏,等於假設所有學生來自同一個母體、忽略了他們分屬不同班級。後果是補值把班級間的差異「拉平」——組內相關(intraclass correlation, ICC)被系統性低估,班級層的變異被吃掉,你會錯誤地下結論「班級之間沒什麼差別」。
反過來,若把「班級」當成一堆虛擬變數(fixed effects)硬塞進單層插補,當班級數很多時又會過度配適、高估組間差異。正確做法是用契合層級結構的插補模型:
- 對連續變數用 多層線性混合模型插補(如
mice的2l.norm、2l.pan方法,或jomo、mlmi套件),讓插補模型本身帶有隨機截距/隨機斜率。 - 區分第一層變數(學生層,如個人動機)與第二層變數(班級層,如班級規模)——第二層變數在同一班內所有缺漏應補成同一值。
- 一個鐵則與 congeniality 呼應:分析模型有隨機斜率,插補模型也要有對應的異質性,否則交互結構被抹平。
這個陷阱的危險在於它「不會報錯」——軟體照樣跑出漂亮結果,只是你的 ICC 和跨層交互效果被悄悄扭曲。處理巢狀資料時,務必確認插補引擎是「知道層級的」。
換個目標:預測任務裡的遺漏,規則完全不同
到目前為止的一切——Rubin 規則、congeniality、FMI——都服務於一個目標:對母體參數做無偏的統計推論。但如果你的目標是建一個機器學習預測模型(預測誰會輟學、誰需要學習介入),遊戲規則會改變。
第一個觀念翻轉:在預測情境,「遺漏本身」往往帶有資訊。「某學生從不填寫選修的反思日誌」這件事,可能正是預測其投入度的強訊號。統計推論裡我們想消除遺漏帶來的偏誤;但預測裡,我們反而想保留並利用這個訊號。實務做法是加一個 missingness indicator(遺漏指示變數):對每個有缺的特徵額外建一欄 $R_j\in\{0,1\}$,讓模型自己學「缺不缺」是否有預測力。(注意:這個技巧在統計推論裡通常是禁忌——它在 MAR 下會引入偏誤;但在純預測、只追求測試集表現時是正當的。目標不同,紅線不同。)
第二個、也更致命的陷阱是 資料洩漏(data leakage)。如果你用「整個資料集的均值」去補缺、然後才切訓練/測試集,你就把測試集的資訊偷渡進了補值——模型在驗證時會看起來好得不真實,上線後崩盤。正確流程必須把插補當成模型管線的一部分、納入交叉驗證迴圈:
- 切分訓練/測試(或在 $k$-fold 的每一折)。
- 只用訓練資料估計插補模型(學到的均值、迴歸係數、MICE 條件模型)。
- 用這個「凍結」的插補模型去補訓練集,訓練預測模型。
- 用同一個凍結的插補模型去補測試集(測試集的補值只能依賴它自己的觀測特徵 + 訓練集學到的參數)。
第三,有些模型原生處理遺漏,不需插補。像 XGBoost、LightGBM 這類梯度提升樹,在每個分裂節點會學一個「缺漏值往左還是往右走」的預設方向——這等於讓樹自己利用遺漏結構。但要小心:原生處理不等於免疫於 MNAR 偏誤,只是把處理方式交給了演算法。選 MI、選指示變數、還是選原生處理,取決於你要推論還是要預測——這是兩種不同的科學提問。
比遺漏更隱蔽的品質殺手:測量誤差
最後把鏡頭拉遠。遺漏值是「格子空著」——至少它誠實地告訴你「這裡沒有資料」。但資料品質還有一個更隱蔽的敵人:格子有填,但填的是錯的,這就是測量誤差(measurement error)。
兩者有深刻的數學連結:遺漏可視為測量誤差的極端情形——誤差大到把訊號完全淹沒。 而測量誤差對估計的影響方向,恰好與單一插補的問題相映成趣:
- 古典測量誤差(classical measurement error):觀測值 $X^* = X + \varepsilon$,誤差 $\varepsilon$ 與真值獨立。它的著名後果是衰減偏誤(attenuation bias)——自變數有測量誤差時,迴歸係數被系統性地往零拉。具體地,估計係數約為真係數乘上信度(reliability) $\frac{\sigma_X^2}{\sigma_X^2+\sigma_\varepsilon^2}$。若一份量表信度只有 0.7,真實效果 $\beta=0.5$ 會被低估成約 $0.35$。
- 均值插補的詭異對偶:回想入門篇,均值插補把補值疊在平均線上、壓縮變異、稀釋相關——這其實也是一種「人造的測量誤差」,同樣造成衰減。兩個看似無關的問題,在「削弱觀測到的關聯」這件事上殊途同歸。
更要命的是,遺漏與測量誤差常同時發生且交互放大。穿戴裝置的生理數據既會斷訊(遺漏),又會因運動雜訊而讀數失真(測量誤差);而「訊號品質差的時段」往往「同時容易缺漏又容易失真」——這讓 MAR 假設更難成立(缺漏與沒觀測到的真值,透過共同的品質因子相關)。負責任的資料品質審計,不能只數有多少格是空的,還要問:有填的格子,每一格有多可信?
重點回顧
- congeniality:插補模型應是分析模型的超集,包含所有交互項、非線性項、輔助變數,甚至依變數。不相容時 Rubin 變異公式不再保證保守,標準誤可能被高估或低估。
- MICE 要診斷收斂:它是迭代的吉布斯式抽樣,需看 trace plot 確認 $m$ 條鏈交織無趨勢;預設 5–10 輪對高遺漏資料常不夠。
- $m$ 不是越省越好:點估計或許 $m=5$ 就穩,但依賴組間變異 $B$ 的標準誤與 $p$ 值在小 $m$ 下蒙地卡羅誤差極大;建議 $m\approx 100\times\text{FMI}$,或直接用 20–50。
- 多層資料要用多層插補:單層插補會把班級結構拉平、低估 ICC 與跨層效果,而且不會報錯。
- 預測 ≠ 推論:預測任務可用遺漏指示變數利用缺漏訊號、可用原生處理模型,但必須把插補納入交叉驗證避免資料洩漏。遺漏與測量誤差是資料品質的一體兩面,常交互放大並一起威脅 MAR。
深入探討(研究所視角)
uncongeniality 下的變異效度——Meng 的「self-efficiency」框架。 Meng(1994)證明,當插補與分析模型不相容時,Rubin 合併變異 $T$ 對真實重複抽樣變異 $V$ 的關係取決於分析程序是否 self-efficient。一個程序若 self-efficient,意味著它不會因丟棄部分資料而提升效率;對 self-efficient 的分析,uncongenial 插補下 Rubin 變異保守($T\ge V$,信賴區間偏寬,型一誤差受控)。但對非 self-efficient 的分析(某些加權估計、特定 GMM 設定),$T$ 可能反過來低估 $V$,導致信賴區間過窄。這解釋了為何「插補比分析豐富」是安全的經驗法則卻非鐵律——嚴格保證需要分析端的 self-efficiency 條件。Robins 與 Wang(2000)進一步給出在 uncongeniality 下漸近有效的替代變異估計式,但其需要插補與分析雙方的額外資訊,在「插補者/分析者分離」的現實中往往不可得,這正是 MI 分工模式的理論代價。
自由度、FMI 與檢定的有限樣本修正。 入門篇給了 $\nu=(m-1)\lambda^{-2}$ 這個經典自由度,但它假設完整資料自由度 $\nu_{com}$ 無限大。Barnard–Rubin(1999)修正在小樣本下更準確:令 $\nu_{obs}=\frac{\nu_{com}+1}{\nu_{com}+3}\nu_{com}(1-\lambda)$,則調整後自由度 $\nu_{adj}=\left(\frac{1}{\nu}+\frac{1}{\nu_{obs}}\right)^{-1}$。當完整資料樣本本來就小,這個修正會把自由度往下拉、尾部加厚,避免在「樣本小 + 遺漏多」的雙重不確定下過度自信。對多參數的聯合檢定,還需用 $D_1$(Wald 型)、$D_2$(合併檢定統計量)或 $D_3$(概似比型)等多元 Rubin 規則,三者在 uncongeniality 與小 $m$ 下的行為不同,$D_3$ 通常最穩健但計算最重。
MNAR 的可識別性與遺漏與測量誤差的統一視角。 把遺漏指示 $R$ 與測量過程一起寫進測量模型,可得一個統一的「不完整資料」框架:觀測到的是 $(R, RY^*)$,其中 $Y^*=Y+\varepsilon$ 為帶誤差的測量,$R$ 為遺漏機制。MAR/可忽略性對應 $\varepsilon$ 為非微分(non-differential)誤差加上 $R\perp Y_{mis}\mid Y_{obs}$;MNAR 與微分誤差(differential measurement error,誤差大小依賴真值或結果)在識別性上同屬「無法由觀測資料區辨、需外部資訊」的同一類問題。實務上的外部資訊包括:(1) 驗證子樣本(validation sample)——對部分個案同時取得「易測但有誤」與「黃金標準」測量,用以校準衰減;(2) 工具變數——找一個只透過真值影響結果的外生變數,類似 Heckman 選擇模型用排除限制(exclusion restriction)識別 MNAR。兩者本質相同:對無法檢驗的假設,要嘛靠領域理論論證、要嘛靠額外資料釘住識別,沒有第三條路。這也呼應入門篇的結論——敏感度分析不是要「估出真相」,而是把「資料品質的不確定性」這個旋鈕誠實地攤開,讓讀者看見結論在合理擾動下究竟有多穩固。對 Uedu 這類整合問卷、學習歷程與穿戴生理訊號的多模態教育資料,遺漏與測量誤差幾乎必然共存,把兩者放進同一個品質框架審計,才是經得起檢驗的分析態度。