
少數幾個分布,描述大半個世界:二項、卜瓦松與常態
從數成敗、數稀有事件到鐘形曲線,看懂機率分布如何刻畫現實。
為什麼少數幾個分布就能描述大半的世界
世界看似雜亂無章,但統計學家很早就發現:許多看似不相干的現象,其實共用著同一套「形狀」。一間便利商店一天賣出幾杯咖啡、一條生產線出現幾件瑕疵品、一群學生的身高分布——它們背後往往可以用同一個機率分布來刻畫。所謂機率分布(probability distribution),就是描述「某個隨機變數會落在哪些值、各以多大機率出現」的數學規則。
本文要介紹三個最常用、也最有代表性的分布:二項分布(成敗的計次)、卜瓦松分布(稀有事件的計次)、常態分布(連續量的鐘形曲線)。理解它們,等於拿到了打開大半現實世界的鑰匙。
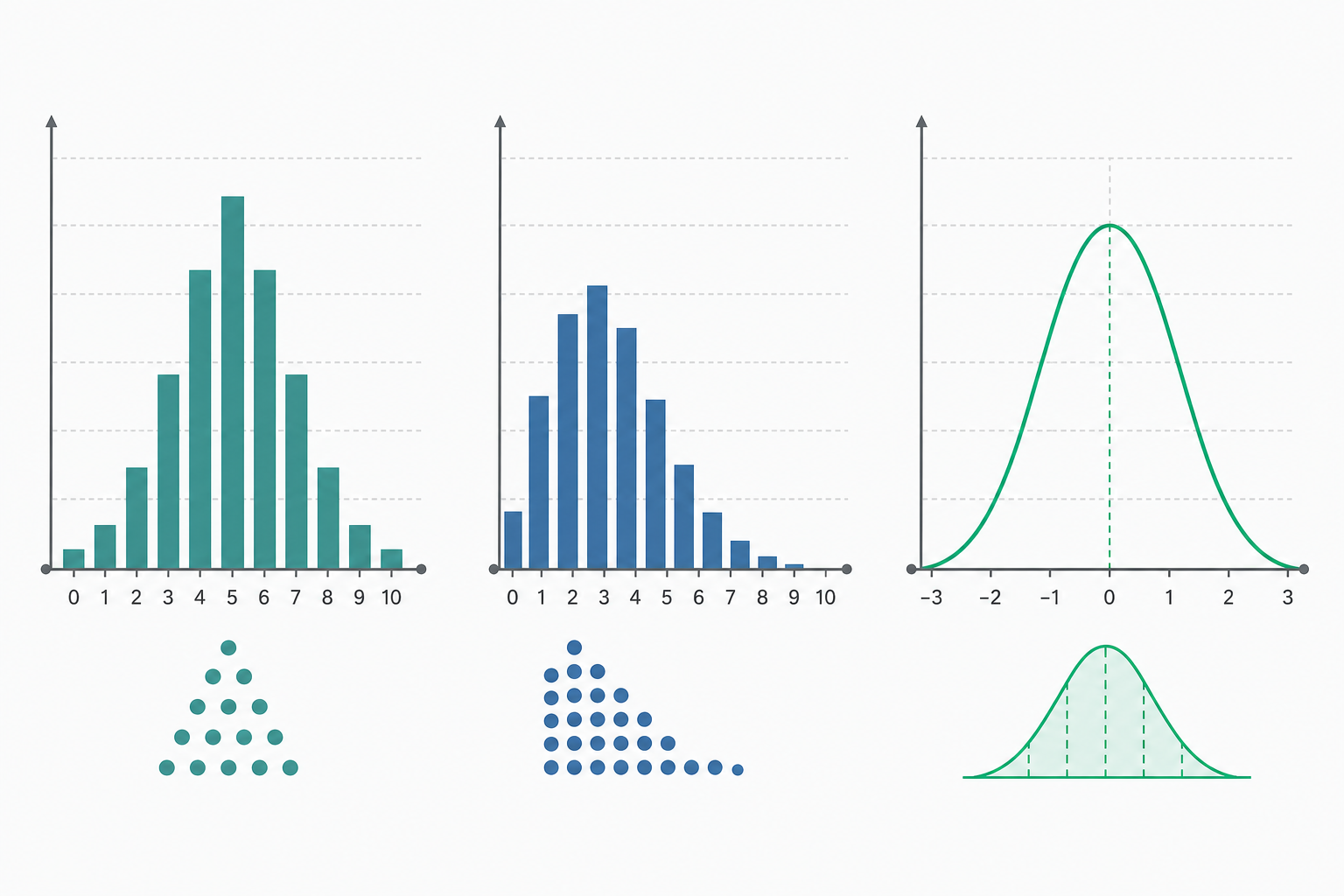
二項分布:數「成功了幾次」
想像你投一枚硬幣 $10$ 次,想知道「正好出現 $6$ 次正面」的機率。這類問題的共同特徵是:固定做 $n$ 次獨立試驗,每次只有「成功/失敗」兩種結果,每次成功機率都是同一個 $p$。符合這些條件,計次的隨機變數 $X$ 就服從二項分布,記為 $X \sim B(n, p)$。
它的機率質量函數是:
$$P(X=k)=\binom{n}{k}\,p^{k}(1-p)^{n-k}$$
其中 $\binom{n}{k}=\frac{n!}{k!(n-k)!}$ 是「從 $n$ 次中挑出哪 $k$ 次成功」的組合數。
帶數字的小範例:公平硬幣 $p=0.5$,丟 $10$ 次,求正好 $6$ 次正面。
$$P(X=6)=\binom{10}{6}(0.5)^{6}(0.5)^{4}=210\times(0.5)^{10}=\frac{210}{1024}\approx 0.205$$
也就是約 $20.5\%$。二項分布的平均數與標準差有簡潔的公式:
$$\mu = np = 10\times 0.5 = 5,\qquad \sigma=\sqrt{np(1-p)}=\sqrt{10\times0.5\times0.5}\approx 1.58$$
平均出現 $5$ 次正面、典型波動約 $1.58$ 次,正好對應我們的直覺。
卜瓦松分布:稀有事件的計數
如果試驗次數 $n$ 非常大、但每次成功機率 $p$ 非常小,逐次去算二項分布會很麻煩。此時更自然的描述是「在一段固定時間或空間內,平均發生 $\lambda$ 次的事件,實際發生幾次」。這就是卜瓦松分布,記為 $X \sim \text{Poisson}(\lambda)$:
$$P(X=k)=\frac{\lambda^{k}e^{-\lambda}}{k!}$$
它的一大特色是平均數與變異數相等,都等於 $\lambda$。常見情境包括:醫院急診室一小時的到院人數、一本書每頁的錯字數、某路口一週的事故件數。
帶數字的小範例:某客服平均每小時接到 $\lambda=3$ 通客訴電話,問「下一小時正好接到 $5$ 通」的機率。
$$P(X=5)=\frac{3^{5}e^{-3}}{5!}=\frac{243\times 0.0498}{120}\approx 0.101$$
約 $10.1\%$。值得注意的是,卜瓦松假設事件彼此獨立且發生率穩定;若客訴會「一窩蜂」群聚出現,這個假設就被破壞,模型也會失準。
常態分布:自然界的鐘形曲線
前兩者數的是「次數」(離散值),但很多量是連續的:身高、體重、測量誤差、考試總分。這些量往往呈現對稱的鐘形分布,也就是常態分布,記為 $X \sim N(\mu, \sigma^2)$,密度函數為:
$$f(x)=\frac{1}{\sigma\sqrt{2\pi}}\exp\!\left(-\frac{(x-\mu)^2}{2\sigma^2}\right)$$
常態分布之所以無所不在,深層原因是中央極限定理:許多獨立小因素的加總,無論各自分布為何,總和都會趨近常態。身高受成千上萬個基因與環境因素共同影響,於是呈現鐘形,正是這個道理。
實務上最有用的是「$68$–$95$–$99.7$ 法則」:約 $68\%$ 的資料落在 $\mu\pm\sigma$、$95\%$ 落在 $\mu\pm 2\sigma$、$99.7\%$ 落在 $\mu\pm 3\sigma$。
帶數字的小範例:某次模考成績近似 $N(\mu=60,\ \sigma=10)$,問考超過 $75$ 分的機率。先把分數標準化為 $z$ 分數:
$$z=\frac{x-\mu}{\sigma}=\frac{75-60}{10}=1.5$$
查標準常態表,$P(Z>1.5)\approx 0.067$。也就是大約只有 $6.7\%$ 的學生考超過 $75$ 分。$z$ 分數的妙處在於:它把任何常態分布都換算到同一把尺上,方便彼此比較。
三者的關係與素養提醒
這三個分布並非各自獨立,而是彼此相連:當二項分布的 $n$ 很大、$p$ 很小時,會逼近卜瓦松分布;而當 $n$ 夠大時,二項與卜瓦松又都會逼近常態分布。它們像是同一棵樹上的三根枝幹。
最後提醒幾個容易踩的坑。第一,套用分布前要先檢查假設:二項要求每次試驗獨立且成功率固定,卜瓦松要求事件獨立且發生率穩定,硬套會得出漂亮卻錯誤的數字。第二,「看起來像鐘形」不等於就是常態;收入、城市人口這類資料常右偏(有長尾),用常態硬算會嚴重低估極端值。第三,也是統計素養的核心:分布只描述「在某些假設下會怎樣」,它不會告訴你因果——觀察到兩件事一起變動(相關),絕不代表一個導致了另一個。把分布當成描述世界的語言,而非預言世界的水晶球,才是正確的使用方式。
深入探討(研究所視角)
從測度論的角度,一個隨機變數是從機率空間 $(\Omega,\mathcal{F},\mathbb{P})$ 到 $\mathbb{R}$ 的可測函數,其分布由分布函數 $F(x)=\mathbb{P}(X\le x)$ 唯一決定。三個分布可被統一納入指數族(exponential family),其密度可寫成 $f(x\mid\theta)=h(x)\exp\!\big(\eta(\theta)T(x)-A(\theta)\big)$ 的形式。這個結構並非形式遊戲:它保證了充分統計量 $T(x)$ 的存在(Fisher–Neyman 分解定理),並使最大概似估計具備良好性質。
以最大概似估計(MLE)為例,給定樣本,對數概似 $\ell(\theta)=\sum_i \log f(x_i\mid\theta)$。對常態分布,解 $\partial\ell/\partial\mu=0$ 得 $\hat\mu=\bar x$,是不偏的;但 $\hat\sigma^2=\frac{1}{n}\sum(x_i-\bar x)^2$ 卻是有偏的,期望值為 $\frac{n-1}{n}\sigma^2$。這正是樣本變異數要除以 $n-1$(自由度)的原因——我們用掉一個自由度去估計 $\mu$。所謂自由度,本質是參數空間在估計後殘餘的維度。
估計量的好壞有三個經典判準:不偏性($\mathbb{E}[\hat\theta]=\theta$)、一致性($\hat\theta\xrightarrow{P}\theta$,由大數法則保證)、有效性(變異數達到 Cramér–Rao 下界 $1/I(\theta)$,其中 $I(\theta)$ 是 Fisher 訊息量)。在正則條件下,MLE 是漸近常態且漸近有效的:$\sqrt{n}(\hat\theta-\theta)\xrightarrow{d} N\big(0,\,I(\theta)^{-1}\big)$。這也說明了為何常態分布在推論統計裡無所不在——它是大樣本下抽樣分布的極限形態。
貝氏觀點則把參數本身視為隨機變數,藉由 $p(\theta\mid x)\propto p(x\mid\theta)\,p(\theta)$ 更新信念。指數族的美妙之處在於存在共軛先驗:二項配 Beta、卜瓦松配 Gamma、常態(已知變異數)配常態,後驗仍屬同族,計算因此封閉可解。值得強調的是,貝氏的「可信區間」(credible interval)與頻率學派的「信賴區間」意義不同——前者可直接說「參數有 $95\%$ 機率落在此區間」,後者則是指「重複抽樣下,$95\%$ 的區間會涵蓋真值」,對單一區間談機率是常見的誤解。
最後是與機器學習的連結。邏輯斯回歸本質是對伯努利(二項的單次版本)做最大概似;卜瓦松回歸是廣義線性模型(GLM)對計數資料的標準工具;而以高斯(常態)為雜訊假設的最小平方法,等價於在常態概似下做 MLE。效果量(如 Cohen's $d=\frac{\bar x_1-\bar x_2}{s_p}$)則提醒我們:在大樣本時 p 值極易顯著,唯有效果量能回答「差異是否大到值得在意」。從古典推論到現代學習演算法,這幾個分布始終是骨架。