
多測幾次就準了:大數法則與中央極限定理
為什麼樣本平均會趨近真值,又為什麼鐘形曲線無所不在
為什麼多測幾次就「準」了?
想像你在夜市玩套圈圈,老闆說每個攤位的平均成功率是三成。你套了五次,結果一個都沒中。你會說「老闆騙人」嗎?先別急。如果你套了五百次,命中率大概就會穩穩地落在三成附近。這個「多測幾次就會逼近真值」的直覺,正是統計學兩大支柱之一——大數法則——所描述的現象。
而它的孿生兄弟中央極限定理(Central Limit Theorem, CLT)則回答了另一個更神奇的問題:為什麼無論原始資料長什麼樣子,只要我們取「平均」,那個平均值的分布幾乎總是長成同一個鐘形?這兩個定理是整個推論統計(信賴區間、假設檢定)的地基。
大數法則:樣本平均會「定下來」
我們先把語言換成符號。假設有一群獨立、同分布的隨機變數 $X_1, X_2, \dots, X_n$,它們的真實平均(母體期望值)是 $\mu$。我們計算樣本平均:
$$\bar{x} = \frac{1}{n}\sum_{i=1}^{n} x_i$$
大數法則保證:當樣本數 $n$ 越來越大,$\bar{x}$ 會越來越靠近 $\mu$。換句話說,樣本平均是母體平均的好估計,而且資料越多越好。
這聽起來理所當然,卻常被誤用。最有名的就是「賭徒謬誤」:輪盤連開五次紅色,有人就覺得「接下來該開黑了」。但大數法則說的是「長期平均會趨於均衡」,不是「老天爺會記帳,刻意補一把黑色給你」。每一次旋轉都是獨立的,過去不會影響未來。理解這個差別,是統計素養的第一課。
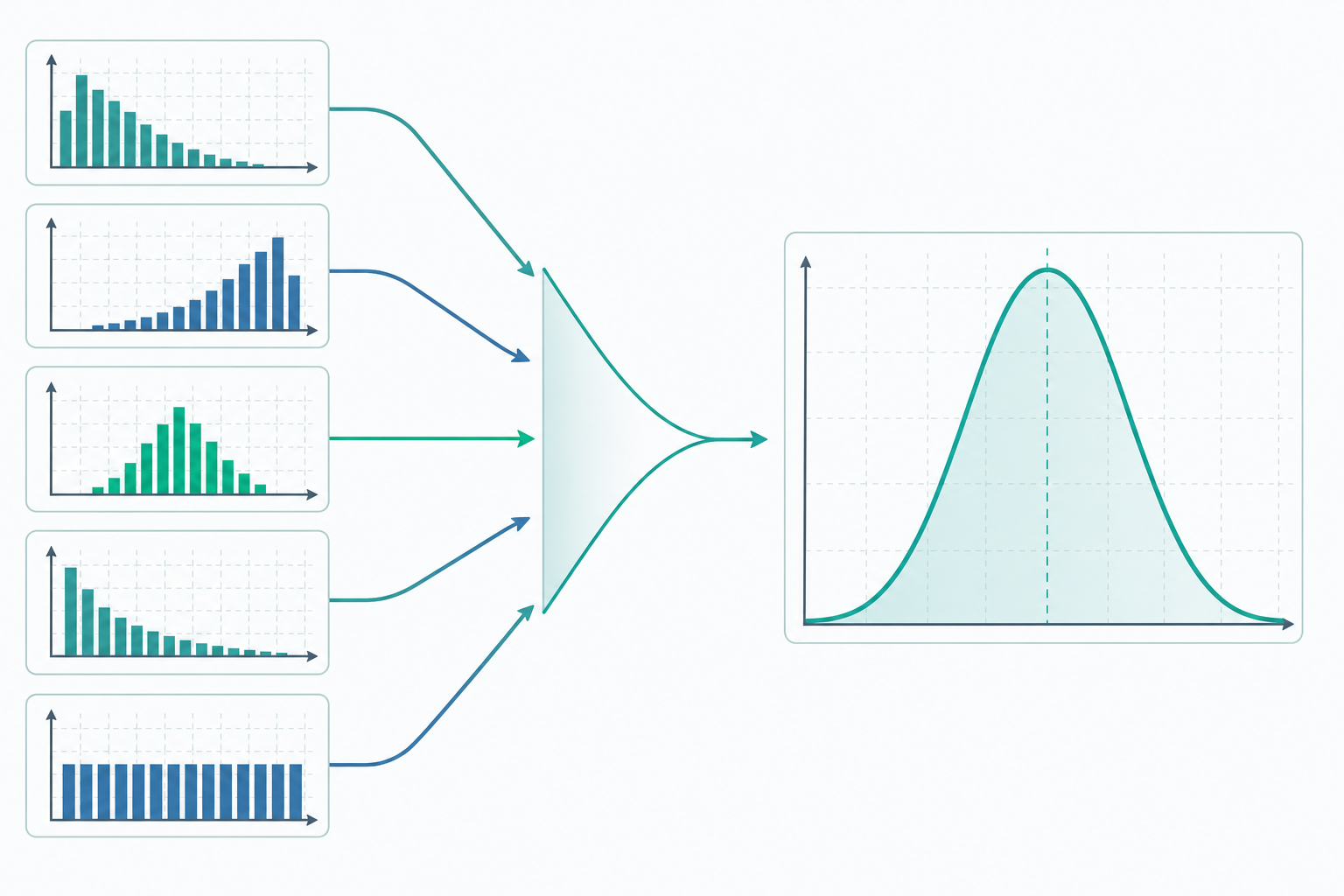
中央極限定理:鐘形曲線無所不在
大數法則告訴我們 $\bar{x}$ 會收斂到 $\mu$,但沒告訴我們「靠近的速度」與「靠近的方式」。中央極限定理補上了這塊。
它說:只要母體有有限的平均值 $\mu$ 與標準差 $\sigma$,那麼當 $n$ 夠大時,樣本平均 $\bar{x}$ 的分布會趨近一個常態分布(normal distribution,又稱高斯分布),其平均仍是 $\mu$,但標準差縮小成 $\sigma/\sqrt{n}$:
$$\bar{x} \;\sim\; \mathcal{N}\!\left(\mu,\; \frac{\sigma^2}{n}\right)$$
這裡有兩個關鍵洞見。第一,原始資料就算是歪七扭八的分布(例如收入、等待時間這種右偏資料),它的樣本平均仍然會變成漂亮的鐘形。第二,分母那個 $\sqrt{n}$ 解釋了為什麼民調要訪問上千人——要把誤差砍一半,樣本數得變成四倍。
這也說明了「為什麼常態分布無所不在」:自然界與社會中許多量(身高、測量誤差、考試總分)其實是大量微小因素相加的結果,而「相加再平均」正是 CLT 發威的地方,於是鐘形曲線就一再現身。
一個帶數字的小範例
假設某品牌洋芋片標示每包淨重 $\mu = 100$ 公克,母體標準差 $\sigma = 6$ 公克。品管員隨機抽 $n = 36$ 包,量得樣本平均 $\bar{x} = 98$ 公克。這批貨「明顯偏輕」嗎?
先算樣本平均的標準差(稱為標準誤):
$$\text{SE} = \frac{\sigma}{\sqrt{n}} = \frac{6}{\sqrt{36}} = \frac{6}{6} = 1 \text{ 公克}$$
再算 $z$ 分數,看 $\bar{x}$ 偏離 $\mu$ 多少個標準誤:
$$z = \frac{\bar{x} - \mu}{\sigma/\sqrt{n}} = \frac{98 - 100}{1} = -2.0$$
查標準常態表,$|z| = 2.0$ 對應的雙尾機率約為 $0.046$,小於常用門檻 $0.05$。也就是說,若這批貨真的平均 100 公克,純靠運氣抽到平均 98 公克(或更極端)的機率只有約 4.6%。在 $\alpha = 0.05$ 的標準下,我們會傾向認為「這批貨確實偏輕」。
我們也可以反過來給一個 95% 信賴區間:
$$\bar{x} \pm 1.96 \times \text{SE} = 98 \pm 1.96 \times 1 = (96.04,\; 99.96)$$
注意這個區間不包含 100,與上面的檢定結論一致。
這裡要特別澄清一個極常見的誤解:95% 信賴區間不是「真值有 95% 機率落在這個區間內」。真值 $\mu$ 是一個固定的數,它要嘛在區間裡、要嘛不在。正確的說法是:如果我們重複抽樣、每次都這樣造一個區間,長期下來會有約 95% 的區間蓋住真值。把信賴水準誤讀成「真值的機率」,是統計報告中最常見的錯誤之一。
別忘了它的前提
這兩個定理威力強大,但不是萬靈丹。它們的前提是觀測值獨立且來自有限變異數的分布。如果資料彼此高度相關(例如同一個人連續回答、或時間序列有趨勢),$\sqrt{n}$ 的魔法就會打折,實際誤差會比公式算出來的大。此外,CLT 是「漸近」結果——$n$ 要「夠大」才成立;對極度偏斜的資料,$n=30$ 可能還不夠。
最後提醒一句最重要的統計素養:樣本平均逼近真值,談的是估計的精準度,不是因果關係。觀察到「喝咖啡的人平均壽命較長」,再多的樣本也只能讓這個「相關」更穩定,不能讓它變成「咖啡延壽」的因果結論。資料量大,能讓你更確定看到了什麼;但「看到了什麼」與「為什麼」,永遠是兩件事。
深入探討(研究所視角)
嚴格來說,大數法則有兩個版本。弱大數法則(WLLN)斷言樣本平均依機率收斂到母體平均,即對任意 $\varepsilon > 0$,$\lim_{n\to\infty} P(|\bar{X}_n - \mu| > \varepsilon) = 0$,其證明可由 Chebyshev 不等式直接導出。強大數法則(SLLN, Kolmogorov)更強,斷言幾乎必然收斂,$P(\lim_{n\to\infty}\bar{X}_n = \mu) = 1$。兩者的差別在於收斂模式(convergence in probability 對 almost sure convergence),這是測度論機率的核心區辨。中央極限定理的標準(Lindeberg–Lévy)形式則為依分布收斂:$\sqrt{n}(\bar{X}_n - \mu)/\sigma \xrightarrow{d} \mathcal{N}(0,1)$。當變異數不存在(如 Cauchy 分布),CLT 失效,取而代之的是收斂到穩定分布(stable distribution)的廣義極限定理。
這套理論直接決定了估計量的好壞標準。一個估計量 $\hat{\theta}$ 若 $E[\hat{\theta}] = \theta$ 稱為不偏(unbiased);若 $\hat{\theta} \xrightarrow{p} \theta$ 稱為一致(consistent,正是 WLLN 在背後撐腰);在不偏估計量中變異數最小者稱為有效(efficient),其下界由 Cramér–Rao 不等式給出。這也是為什麼樣本變異數用 $n-1$ 而非 $n$ 當分母——除以自由度才能讓估計量不偏,因為樣本平均已用掉一個約束。
最大概似估計(MLE)是現代推論的主力:選取使概似函數 $L(\theta) = \prod_i f(x_i;\theta)$ 最大的 $\theta$。MLE 在正則條件下具備一致性與漸近常態性,且漸近達到 Cramér–Rao 下界(漸近有效),其漸近變異數由 Fisher 資訊量的倒數給出。實務上也別忽略效果量(如 Cohen's $d$):當 $n$ 極大時,CLT 使標準誤趨近 0,幾乎任何微小差異都會「統計顯著」,此時 $p$ 值會誤導,必須回報效果量與信賴區間來衡量「實質重要性」。
貝氏觀點提供了互補視角。頻率學派把 $\mu$ 視為固定未知數、把資料視為隨機;貝氏則給 $\mu$ 一個先驗分布,透過 $p(\theta\mid x) \propto p(x\mid\theta)\,p(\theta)$ 更新為後驗。在大樣本下,貝氏後驗也會被概似函數主導而趨於常態(Bernstein–von Mises 定理),使兩派結論在 $n$ 大時漸趨一致。最後,CLT 的精神也滲透到機器學習:交叉驗證誤差的平均、bootstrap 重抽樣的分布、隨機梯度下降中梯度估計的雜訊,乃至集成方法(bagging)藉由平均降低變異,背後都是同一個「平均使估計穩定、誤差以 $1/\sqrt{n}$ 收斂」的數學引擎。