
廣義線性混合模型與置中抉擇:當結果不是分數、效果分兩層的進階多層次分析
從 LMM 走進 GLMM:拉普拉斯近似與 AGHQ 的積分難題、條件式與邊際係數的落差、組內組間效果的分離,以及成長模型與奇異擬合的研究所級機制
當結果不是分數,而是「及格與否」,隨機效果還能直接寫進迴歸嗎?
入門篇我們用學生成績(一個連續的分數)示範了隨機截距與隨機斜率,整套估計建立在常態殘差與線性連結之上。但教育與心理研究裡,真正想預測的常常不是分數,而是二元結果:這名學生這題答對了沒?這位學生最後輟學了沒?這次互動是否觸發了高層次認知?把這種 0/1 結果硬塞進線性混合模型,等於假設機率可以超過 1、低於 0,顯然荒謬。
於是問題升級成:當結果變數是二元、計數或順序時,隨機效果該怎麼進場?看似只要「把 logistic 迴歸加上隨機截距」就好,但魔鬼藏在細節——一條看似無害的積分式,會讓整個估計演算法改頭換面,也會讓你對係數的解讀方式徹底改變。這一篇,我們離開連續結果的舒適區,進入廣義線性混合模型(Generalized Linear Mixed Model, GLMM),並把焦點放在三個入門篇刻意略過的進階機制:非線性連結下的積分難題、預測變數的置中(centering)抉擇,以及縱貫成長模型的結構。
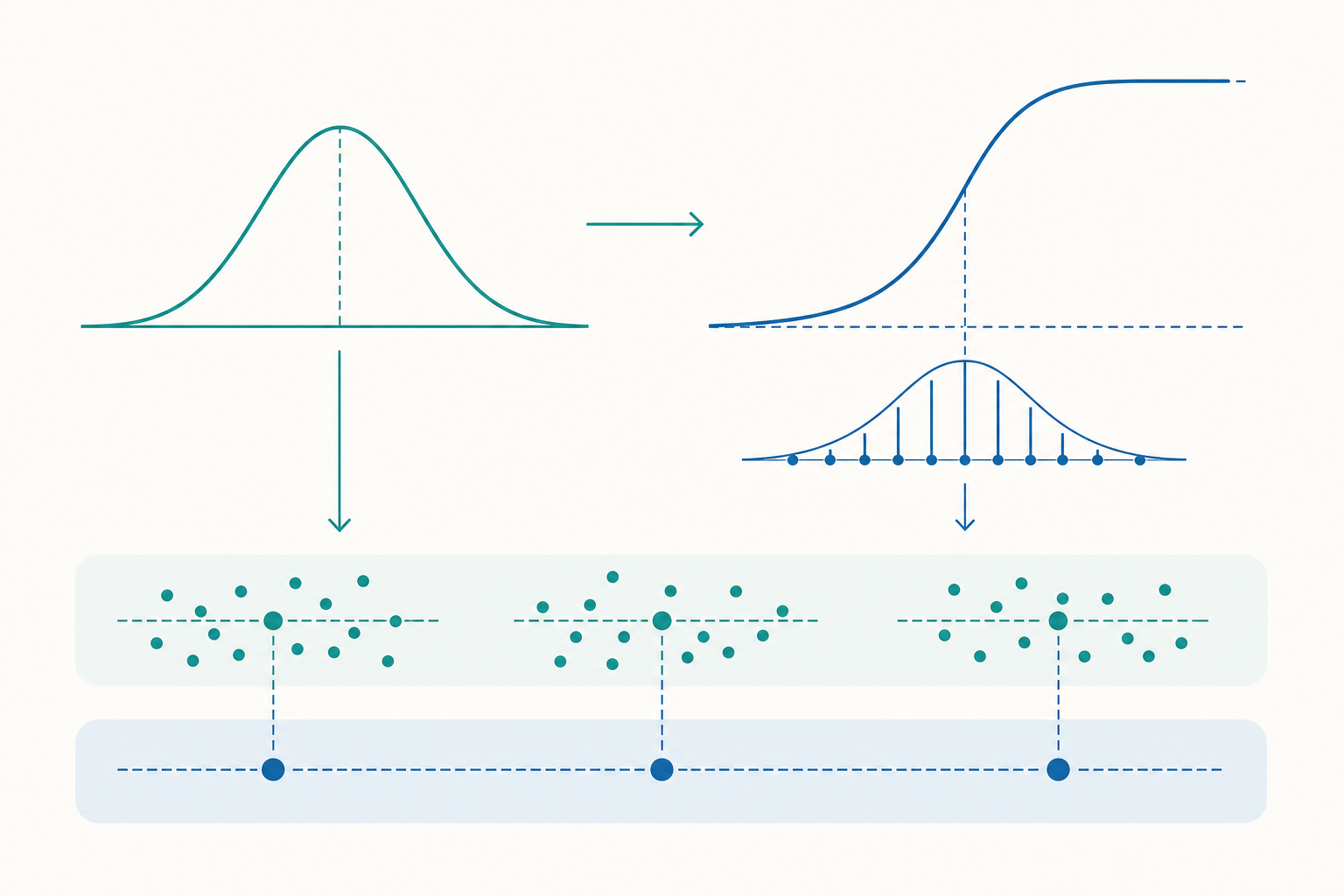
從 LMM 到 GLMM:一個積分改變了一切
線性混合模型(LMM)之所以好算,是因為「常態 + 線性」這對組合下,把隨機效果 $u_{0j}$ 積分掉後,邊際分布仍然是常態,封閉解存在。但換成 logistic 連結後,這個美好性質消失了。
考慮學生 $i$ 巢套於班級 $j$,結果 $y_{ij}\in\{0,1\}$(例如答對與否)。隨機截距 logistic 模型寫成:
$$\text{logit}\big(P(y_{ij}=1\mid u_{0j})\big) = \beta_0 + \beta_1 x_{ij} + u_{0j}, \qquad u_{0j}\sim N(0,\tau_0^2)$$
問題出在:要寫出觀測資料的概似,必須把不可觀測的 $u_{0j}$ 積分掉。對單一班級 $j$,其邊際概似是
$$L_j(\boldsymbol\beta,\tau_0^2) = \int_{-\infty}^{\infty} \left[\prod_{i=1}^{n_j} p_{ij}^{\,y_{ij}}(1-p_{ij})^{1-y_{ij}}\right] \frac{1}{\sqrt{2\pi}\,\tau_0}\exp\!\left(-\frac{u_{0j}^2}{2\tau_0^2}\right)\,du_{0j}$$
其中 $p_{ij}=\text{logit}^{-1}(\beta_0+\beta_1 x_{ij}+u_{0j})$。這個積分沒有封閉解。LMM 裡同樣的積分有解析答案,GLMM 裡卻只能近似。怎麼近似,就是 GLMM 估計的全部技術核心,也是不同軟體跑出不同結果的根源。
三種近似策略,可靠度天差地遠
(1) 罰函數準概似(PQL, Penalized Quasi-Likelihood):最早期、計算最快的方法,本質是把非線性模型在隨機效果的當前估計處做泰勒展開,再套用 LMM 的解法反覆迭代。它的致命傷是:當結果是二元、且每個群組內觀測數很少時,PQL 會系統性低估變異數成分,並讓固定效果產生偏誤。經驗法則是,二元結果加上小群組(如每班只有少數學生答同一題),避免使用 PQL。
(2) 拉普拉斯近似(Laplace approximation):把被積函數的對數在其眾數(mode)處做二階泰勒展開,相當於用一個常態密度去逼近整個被積函數。它等價於「每個群組只用一個積分節點」的高斯-厄米特積分,速度與精度的折衷不錯,是 lme4::glmer 的預設。
(3) 適應性高斯-厄米特積分(Adaptive Gauss-Hermite Quadrature, AGHQ):用 $Q$ 個節點來數值逼近積分:
$$\int g(u)\,\phi(u)\,du \approx \sum_{q=1}^{Q} w_q\, g(u_q)$$
節點 $u_q$ 與權重 $w_q$ 依高斯-厄米特法則決定,且「適應性」指節點會平移、縮放到被積函數的眾數附近,效率更高。$Q=1$ 就退化成拉普拉斯近似;$Q$ 越大越精確,但計算量隨隨機效果維度呈指數成長——這也是為什麼 AGHQ 在實務上幾乎只能用於單一隨機效果(隨機截距),一旦加上隨機斜率,維度上升,AGHQ 變得不可行,只能退回拉普拉斯。
一個常被忽略的事實:對連續常態結果的 LMM,這些近似都不需要,因為積分有解析解。近似只在非線性連結(logistic、Poisson 等)才登場。 這正是 GLMM 比 LMM 難算、難收斂的本質原因。
條件式 vs 邊際:GLMM 的係數不是你以為的那個
入門篇在 GEE 對照時提過 subject-specific 與 population-averaged 的差別。到了 GLMM,這個區別變成你必讀的解讀陷阱,因為它會改變係數的數值大小。
在 logistic GLMM 裡,固定效果 $\beta_1$ 是條件式(conditional / cluster-specific)係數:它的意思是「在同一個班級內(即固定 $u_{0j}$),$x$ 增加一單位,對數勝算(log-odds)的變化量」。它不等於「整個母體平均而言」的效果。
兩者的數值關係有一個常用的近似公式(針對 probit 連結最精確,logistic 近似亦可用):
$$\beta^{\text{marginal}} \approx \frac{\beta^{\text{conditional}}}{\sqrt{1 + 0.346\,\tau_0^2}}$$
也就是說,隨機效果變異 $\tau_0^2$ 越大,邊際係數會被「壓縮」得比條件式係數更接近 0(這稱為衰減 attenuation)。在線性模型裡這個問題不存在(條件式 = 邊際),但在非線性連結下兩者分道揚鑣。
這對你寫論文的意義:如果審稿人問「這個 AI 互動對及格率的整體影響多大」,他要的是邊際效果,你不能直接報 glmer 吐出的條件式 $\beta_1$;若你要談的是「同一班學生之間、多互動是否答對率較高」的機制,那條件式係數才是對的。報告時務必講清楚你報的是哪一種。
置中決策:一個 +/- 就能改變你的結論
這是多層次分析裡最隱晦、卻最常被做錯的環節。當你把一個學生層級預測變數(如讀書時數 $x_{ij}$)放進模型時,用原始值、減去總平均、還是減去各班平均,會得到不同的係數,甚至不同的科學結論。
三種常見做法:
- 原始尺度(raw / no centering):直接放 $x_{ij}$。截距變成「$x=0$ 時的期望」,若 $x=0$ 沒有實質意義(讀書 0 小時還算合理,但若是 IQ=0 就荒謬),截距無法解釋,且與隨機斜率的共變數 $\tau_{01}$ 會被尺度扭曲。
- 總平均置中(CGM, Grand-Mean Centering):用 $x_{ij}-\bar{x}_{\cdot\cdot}$。它不改變 $x$ 的斜率估計值,只平移截距讓它可解釋成「整體平均學生」的期望。適合當預測變數是控制變數、你只在意它的整體效果時。
- 組平均置中(CWC, Centering Within Cluster,又稱 group-mean centering):用 $x_{ij}-\bar{x}_{\cdot j}$,減去該班自己的平均。這一步把變數拆成「純粹組內變異」,斜率變成乾淨的組內效果(within-group effect),完全不受組間差異污染。
為什麼 CWC 才能分離兩個層級的效果
關鍵洞見:原始的 $x_{ij}$ 同時混合了「組內成分」(這個學生比班上同學讀得多多少)與「組間成分」(這個班整體讀得比別班多多少)。一條只放 $x_{ij}$ 的迴歸,其斜率是兩者的某種加權混合,沒有單純的解釋。
正確的拆解是把組平均 $\bar{x}_{\cdot j}$ 當班級層級變數一起放進去:
$$y_{ij} = \beta_0 + \beta_{\text{within}}\,(x_{ij}-\bar{x}_{\cdot j}) + \beta_{\text{between}}\,\bar{x}_{\cdot j} + u_{0j} + \varepsilon_{ij}$$
- $\beta_{\text{within}}$:在同一班內,一個學生比同學多讀一小時,成績高多少(個人努力的回報)。
- $\beta_{\text{between}}$:一個班級平均多讀一小時,該班平均成績高多少(這混雜了班風、師資等脈絡因素)。
當 $\beta_{\text{within}}\neq\beta_{\text{between}}$,就出現了脈絡效果(contextual effect),其大小正是 $\beta_{\text{between}}-\beta_{\text{within}}$。這也是入門篇提過的生態謬誤的正面解方——把兩個層級的關係顯式分開估計,而不是讓它們糾纏。若你只做 CGM 而不放組平均,組內與組間效果會被強制假設相等(一種隱含的限制),可能完全錯失脈絡效果。
看一個例子:Mundlak 檢定揪出脈絡效果
某通識課想知道「課堂發言次數對期末表現的影響」。研究者跑了兩個模型。
模型 A(只放原始發言數 $x_{ij}$,CGM):得到斜率 $\hat\beta = 2.0$(每多發言一次,期末多 2 分)。
模型 B(CWC 拆解,同時放組內項與班級平均 $\bar{x}_{\cdot j}$):
$$\hat\beta_{\text{within}} = 1.2, \qquad \hat\beta_{\text{between}} = 4.5$$
解讀完全不同了:
- 組內效果 1.2 分:在同一班,一個學生比同學多發言一次,期末只高約 1.2 分——個人發言的「淨」回報其實不大。
- 組間效果 4.5 分:一個整體愛發言的班級,平均期末高 4.5 分——但這很可能反映的是班級氣氛、師生互動文化,而非發言本身的因果效益。
脈絡效果 = 4.5 − 1.2 = 3.3 分,而且顯著。這告訴我們:模型 A 看到的 2.0 是組內與組間的混合,會誤導人以為「鼓勵個別學生多發言能加 2 分」。真相是個人發言效益小(1.2),大部分表面關聯來自「會發言的班級本來就不一樣」這個脈絡。
這個比較有個正式名字——Mundlak 檢定:把組平均 $\bar{x}_{\cdot j}$ 加進模型,檢定其係數(即脈絡效果 $\beta_{\text{between}}-\beta_{\text{within}}$)是否為 0。若顯著,代表組間與組內效果不同,不能用單一斜率混為一談。這同時也是判斷「該用隨機效果還是固定效果模型」的經典依據:脈絡效果不為 0,暗示班級層級存在與預測變數相關的遺漏變數。
縱貫資料也是巢套:成長模型
入門篇的巢套是「學生於班級」。但有一種巢套常被忽略:同一個人在不同時間點的多次測量,巢套於這個人。 時間點是第一層、個人是第二層。這把多層次模型直接變成分析縱貫(longitudinal)資料的利器,稱為潛在成長模型(latent growth / random coefficient growth model)。
設第 $i$ 個人在第 $t$ 次測量的成績為 $y_{ti}$,$\text{time}_{ti}$ 為時間(如第幾週):
$$y_{ti} = \pi_{0i} + \pi_{1i}\,\text{time}_{ti} + \varepsilon_{ti}$$
其中每個人有自己的起始水準 $\pi_{0i}$ 與成長速率 $\pi_{1i}$,這兩者再被建模成:
$$\pi_{0i} = \gamma_{00} + u_{0i}, \qquad \pi_{1i} = \gamma_{10} + u_{1i}$$
直覺非常漂亮:$\gamma_{00}$ 是全體平均起點、$\gamma_{10}$ 是全體平均成長斜率,而 $u_{0i}, u_{1i}$ 容許每個人有自己的成長軌跡。$u_{0i}$ 與 $u_{1i}$ 的共變數告訴你「起點高的人是否成長得更快(馬太效應)或更慢(天花板效應)」。
縱貫多層次模型還有兩個超越傳統重複測量變異數分析(repeated-measures ANOVA)的優勢:
- 不需要等距、不需要每人測量次數相同:有人測 5 次、有人因缺席只測 3 次,模型照常運作(只要遺漏是隨機的 MAR)。傳統 ANOVA 通常得把整個個案刪除。
- 可放隨時間變動的預測變數:例如每週的睡眠時數、HRV,直接當第一層變數放進去,研究「狀態的起伏如何即時影響表現」。
重點回顧
- 結果變數非連續(二元、計數、順序)時要用 GLMM;它的邊際概似含一個沒有封閉解的積分,必須用拉普拉斯近似或適應性高斯-厄米特積分(AGHQ)估計,二元小群組下避免 PQL。
- AGHQ 精度最高但只適用單一隨機效果;加了隨機斜率維度爆炸,實務上退回拉普拉斯近似。
- GLMM 的固定效果是條件式(cluster-specific)係數,與 GEE 的邊際係數數值不同,隨機效果變異越大、兩者差距越大;報告時務必聲明你報的是哪一種。
- 置中決策會改變結論:CWC(組平均置中)搭配把組平均放進模型,才能乾淨分離組內效果與組間效果,並量化脈絡效果;只放原始變數會得到無法解釋的混合斜率。
- 把「時間巢套於個人」就得到成長模型,能容忍不等距、不等次數的測量,並分析個別成長軌跡與起點-斜率的關聯。
深入探討(研究所視角)
奇異擬合與邊界估計:當變異數被估成 0
跑 lme4 時常見的警告 boundary (singular) fit 不是 bug,而是一個深刻的統計現象。隨機效果共變數矩陣 $G$ 必須半正定,但最大概似的最佳解有時落在參數空間的邊界上——某個變異數估計為 $\hat\tau^2=0$,或某個隨機效果相關估計為 $\pm 1$。
這帶來兩個層面的麻煩。其一是數值層面:優化器在邊界附近梯度行為惡劣,容易回報假收斂。其二更根本,是推論層面:檢定「$H_0:\tau_1^2=0$」(要不要保留隨機斜率)時,虛無假設恰好落在參數空間邊界上,標準的概似比檢定統計量不再服從卡方分布。正確的參考分布是兩個卡方分布的混合 $\tfrac{1}{2}\chi^2_{(p)}+\tfrac{1}{2}\chi^2_{(p+1)}$(檢定單一變異數時為 $\tfrac{1}{2}\chi^2_0+\tfrac{1}{2}\chi^2_1$)。若你直接用一般 $\chi^2_1$ 的 p 值,會過度保守,傾向錯誤地把該保留的隨機斜率丟掉。實務補救包括:用 mixture 校正後的 p 值、用參數化拔靴(parametric bootstrap)模擬虛無分布,或在貝氏框架下對 $G$ 設弱資訊先驗,自然避開邊界退化。
隨機效果分布錯設的代價與穩健化
GLMM 與 LMM 都假設隨機效果服從多元常態 $u\sim N(0,G)$。一個值得追問的問題是:這個假設錯了會怎樣?
對 LMM,由於高斯模型的穩健性,固定效果估計對隨機效果分布的偏離相對不敏感(一致性大致仍成立),但變異數成分與 BLUP 預測會受影響。對 GLMM,情況更微妙:非線性連結讓邊際概似對隨機效果分布形狀更敏感,特別是當真實分布是多峰或重尾(例如母體其實由幾個潛在次群組混合而成)時,強加單一常態會扭曲固定效果。
幾條前沿路線值得知道:(1) 非參數最大概似(NPML) 把隨機效果分布留作未知,用離散質點(mass points)逼近,等價於潛在類別與連續隨機效果的融合;(2) $t$-分布或偏斜常態隨機效果用以吸收重尾與不對稱;(3) 完全的貝氏階層模型配 MCMC(如 Stan 的 brms),不僅能放更靈活的隨機效果分布,還能對小群組的收縮量做更誠實的不確定性傳遞——這延續了入門篇 BLUP「向母體借力」的精神,但把點預測升級為完整後驗分布。
結構的進一步推廣:交叉分類與三層
最後指出一條入門篇未展開、但 Uedu 教育資料極可能遇到的結構推廣。前述巢套都是嚴格階層(每個學生屬於唯一一個班),但真實教育情境常是交叉分類(cross-classified):一名學生同時巢套於「班級」與「就讀的高中」,而同一高中的畢業生會散落到大學的不同班級——班級與高中互不巢套、彼此交叉。此時隨機效果要寫成兩組各自獨立的交叉項 $u_{\text{class}(j)} + u_{\text{school}(k)}$,而非層層相套。
更一般地,當資料是「學生於班級、班級於學校」的三層巢套,變異數要拆成三塊 $\sigma^2 + \tau^2_{\text{class}} + \tau^2_{\text{school}}$,ICC 也分裂成兩種定義:同校同班兩生的相關、與同校不同班兩生的相關。對 Uedu 的子網域架構(學校)—ClassroomGPT 教室(班級)—學生三層而言,這正是正確的分析骨架。需提醒的是,交叉分類與三層模型的隨機效果維度高,幾乎只能用拉普拉斯近似或貝氏 MCMC,AGHQ 在此無用武之地——這也回扣到本文開頭那個核心訊息:一旦離開「常態 + 線性」,估計的可行性本身就成了必須認真對待的研究設計問題。