
分類模型評估指標:混淆矩陣、Precision、Recall、F1 與 ROC-AUC
從混淆矩陣到調和平均與曲線下面積,建立一套依決策情境選對指標的分類評估語言
為什麼「準確率」會騙人
想像一個篩檢罕見疾病的模型:盛行率只有 1%,那麼一個「永遠預測沒病」的模型,準確率就有 99%——卻一個病人都抓不到。這說明準確率(accuracy)在類別不平衡時嚴重失真,我們需要更細緻的分類評估指標。這篇把分類模型評估的整套語言一次講清楚:混淆矩陣、Precision、Recall、F1、ROC 與 AUC。
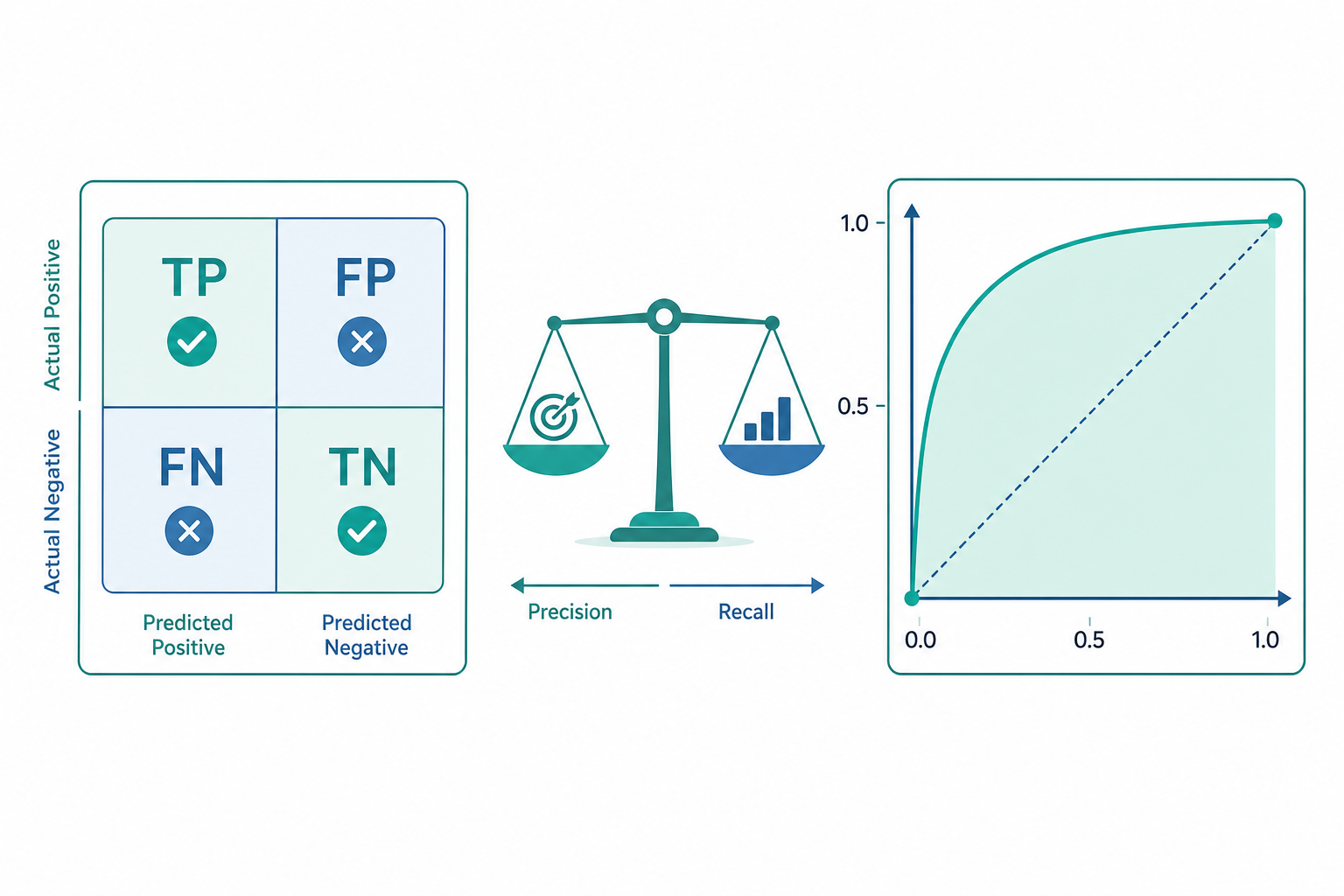
一切的起點:混淆矩陣
二元分類把每個預測歸入四格之一,組成混淆矩陣(confusion matrix):
| 實際為正 | 實際為負 | |
|---|---|---|
| 預測為正 | TP(真陽性) | FP(偽陽性,型一錯誤) |
| 預測為負 | FN(偽陰性,型二錯誤) | TN(真陰性) |
四個數字衍生出所有指標。準確率只是其中最粗的一個:
$$ \text{Accuracy} = \frac{TP+TN}{TP+TN+FP+FN} $$
Precision 與 Recall:兩種「抓對」
- 精確率(Precision,查準率):在「我預測為正」的當中,真的為正的比例。 $$ \text{Precision} = \frac{TP}{TP+FP} $$
- 召回率(Recall,查全率,= 敏感度 Sensitivity):在「實際為正」的當中,被我抓到的比例。 $$ \text{Recall} = \frac{TP}{TP+FN} $$
兩者刻畫不同的痛點:Precision 高代表「報警很少誤報」(適合垃圾郵件,誤殺正常信很惱人);Recall 高代表「漏掉的很少」(適合癌症篩檢,漏掉病人代價極高)。
還有對應負類的特異度(Specificity)= TN/(TN+FP),與 Recall 是「正反兩面」。
F1:當你同時在乎 Precision 與 Recall
Precision 與 Recall 常此消彼長:把判定門檻調鬆,Recall 上升但 Precision 下降。要用「一個數字」綜合兩者,F1 分數取兩者的調和平均(harmonic mean):
$$ F_1 = 2\cdot\frac{\text{Precision}\cdot\text{Recall}}{\text{Precision}+\text{Recall}} $$
為什麼用調和平均而非算術平均? 因為調和平均會被「較小的那個」拉低——只要 Precision 或 Recall 有一個很爛,F1 就很爛,逼模型兩者兼顧。例如 Precision = 1.0、Recall = 0.0 時,算術平均是 0.5(看似還行),但 F1 = 0(誠實地反映模型沒抓到任何正例)。
帶數字的小範例
某模型在 100 個實際病人 + 900 個健康人上:抓出 80 個真病人(TP=80)、漏掉 20 個(FN=20)、誤報 40 個健康人為病人(FP=40)。
- Precision = 80/(80+40) = 0.667
- Recall = 80/(80+20) = 0.80
- F1 = 2 × (0.667 × 0.80)/(0.667 + 0.80) ≈ 0.727
- 而 Accuracy = (80+860)/1000 = 0.94——看起來很高,卻掩蓋了「每 3 個陽性報告就有 1 個誤報」。
F$_\beta$ 一般化:若 Recall 比 Precision 重要 β 倍,用 $F_\beta = (1+\beta^2)\frac{PR}{\beta^2 P + R}$;β=2(F2)偏重 Recall,β=0.5 偏重 Precision。
門檻與 ROC:把「一條曲線」當成模型
多數分類器其實輸出一個機率分數,再用門檻(threshold)切成正負。改變門檻,就在 Precision 與 Recall 之間移動。與其鎖死一個門檻,不如看模型在所有門檻下的表現——這就是 ROC 曲線(Receiver Operating Characteristic):
- 橫軸:偽陽性率 FPR = FP/(FP+TN) = 1 − 特異度
- 縱軸:真陽性率 TPR = Recall
門檻從嚴到鬆掃過,描出一條由 (0,0) 到 (1,1) 的曲線。對角線代表隨機猜測;曲線越往左上角凸,模型越好。
AUC(Area Under the Curve) 就是 ROC 曲線下面積,介於 0.5(亂猜)到 1(完美)。它有個漂亮的機率詮釋:
$$ \text{AUC} = P(\text{score}_{\text{正例}} > \text{score}_{\text{負例}}) $$
亦即「隨機抓一個正例和一個負例,模型給正例較高分的機率」。AUC 的優點是與門檻無關、與類別比例相對穩健,適合比較模型整體排序能力。
別只看 AUC:類別極度不平衡時改看 PR 曲線
當負類遠多於正類(如詐欺偵測),ROC-AUC 可能過度樂觀——因為 FPR 的分母 TN 很大,少量 FP 幾乎不動 FPR。此時改看 Precision–Recall 曲線更誠實,它直接盯著「抓到的正例品質」,不受巨量 TN 稀釋。
重點回顧
- 不平衡資料別信 Accuracy;先看混淆矩陣。
- Precision 管「誤報少」、Recall 管「漏抓少」,依代價取捨。
- F1 用調和平均綜合兩者,懲罰「一邊很爛」。
- ROC/AUC 看「跨所有門檻」的排序能力;極度不平衡時改看 PR 曲線。
深入探討(研究所視角)
各指標的選擇本質上對應不同的代價結構與決策理論。在貝氏決策框架下,最佳門檻由誤分類代價決定:若偽陰性代價 $c_{FN}$、偽陽性代價 $c_{FP}$,最適門檻滿足 $\frac{P(y{=}1\mid x)}{P(y{=}0\mid x)} > \frac{c_{FP}}{c_{FN}}$;F1 與 AUC 都只是「不指定明確代價」時的折衷代理。ROC 曲線的凸包(convex hull) 對應所有可由隨機化分類器達成的 (FPR, TPR) 組合,凸包外的點不可達——這把模型選擇連到等代價線(iso-cost line)與 ROC 的切點。
統計上,AUC 等價於 Mann–Whitney U 統計量正規化後的值($\text{AUC} = U/(n_1 n_0)$),因此它的標準誤與假設檢定可借用無母數秩檢定理論(Hanley–McNeil 法),讓「兩模型 AUC 是否顯著不同」成為可推論的問題;DeLong 檢定即據此處理相關 ROC 的共變異數。
機器學習實務還需處理多分類延伸:micro-average(彙總所有類別的 TP/FP/FN 再算,受多數類主導)與 macro-average(各類別先算再平均,平等對待每類)給出不同的 F1,選擇取決於你在意「整體樣本」還是「每個類別」。校準(calibration) 是另一條正交軸——AUC 只衡量排序好壞,不保證輸出機率「準」;一個 AUC=0.9 的模型仍可能系統性高估風險,需用可靠度圖(reliability diagram)與 Brier score、Platt scaling/isotonic regression 另行校準。這些都把分類評估從「單一數字」推向「依決策情境選對指標」的統計思維,也正是連接統計學與機器學習的核心橋樑(延伸閱讀可接「優智慧 AI」專區)。