
好資料始於好設計:隨機分派、對照組與盲法
在蒐集資料之前,先學會讓資料值得信任
為什麼「怎麼蒐集資料」比「怎麼分析資料」更重要
想像一間咖啡店老闆推出新口味拿鐵,他發現「喝新拿鐵的客人滿意度比較高」,於是斷定新口味成功了。但真相可能是:願意嘗鮮的客人本來就比較好相處、心情比較好。換句話說,「滿意度高」不一定來自「新口味」,而可能來自「客人本來就不一樣」。
統計分析再厲害,也救不了一開始就偏掉的資料。實驗設計(experimental design)研究的正是:在蒐集資料之前,如何安排觀察條件,讓我們能可信地把「結果差異」歸因到「我們操弄的原因」。它有三根支柱:隨機分派、對照組、盲法。好的資料,始於好的設計。
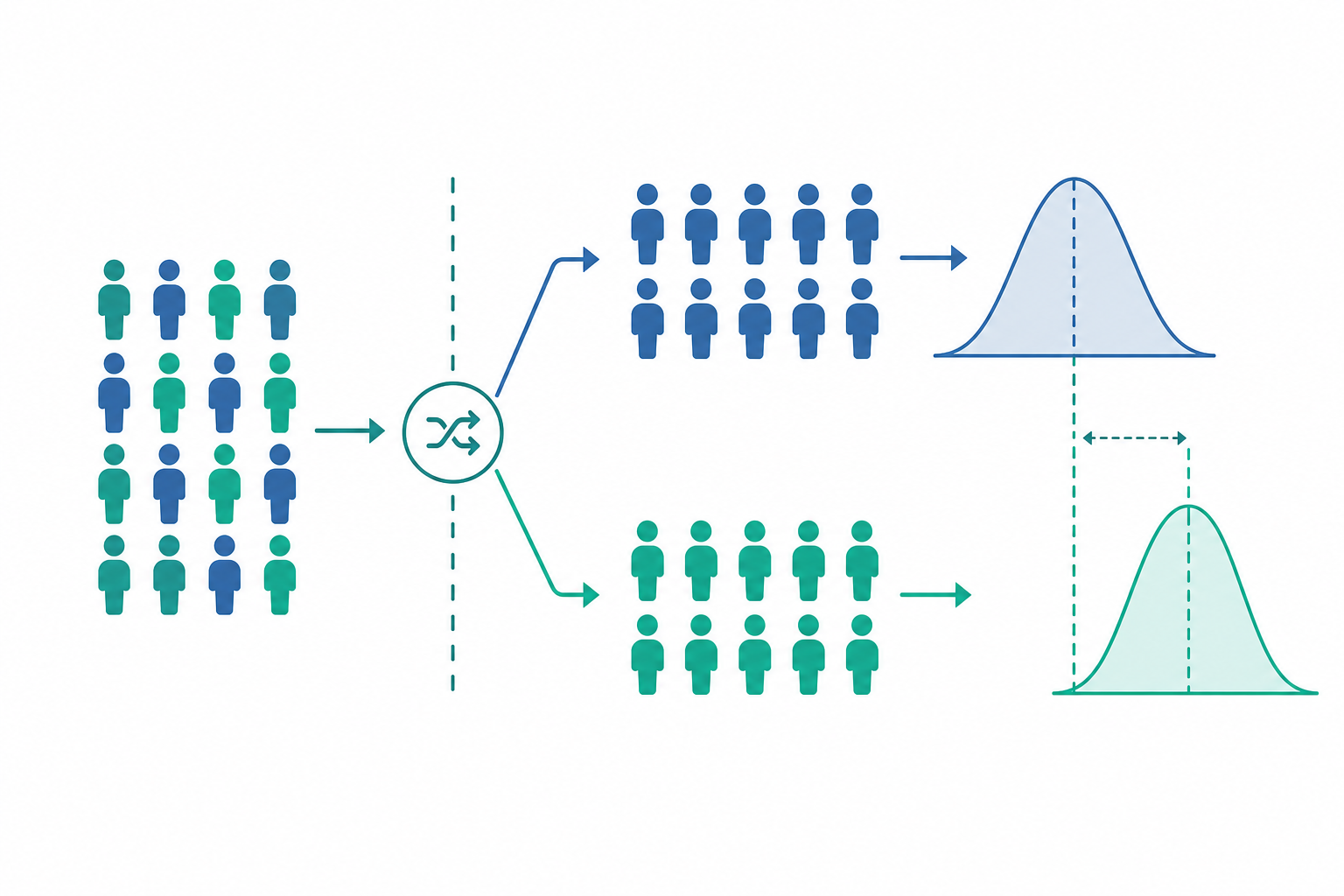
對照組:沒有比較,就沒有意義
我們想知道一種感冒藥有沒有效。如果只給一群人吃藥,發現「七天後 90% 的人好了」,這數字毫無說服力——因為感冒本來就會自己好。我們需要一個對照組(control group):一群條件相近、但沒有接受新處置的人,當作比較的基準。
- 實驗組(treatment group):接受新處置(吃新藥)。
- 對照組:不接受新處置(吃安慰劑,或維持現狀)。
有了對照,我們比較的是「兩組的差異」,而不是「一組的絕對數字」。這個差異,才是處置真正帶來的效果。
隨機分派:對抗看不見的干擾
光有對照組還不夠。如果讓「比較願意吃藥的人」進實驗組、「比較排斥的人」進對照組,兩組從一開始就不同,比較結果仍然不可信。
隨機分派(random assignment)的精神是:用擲硬幣、抽籤或亂數,把每個受試者隨機分到實驗組或對照組。它的威力在於——它連我們沒想到的干擾因素都一起平均掉了。年齡、性別、睡眠、心情、甚至我們根本不知道存在的變項,在大樣本下都會在兩組之間大致均勻分布。
這正是「隨機分派」和「隨機抽樣」常被混淆卻不同的地方: - 隨機抽樣(random sampling)決定「樣本能不能代表母體」——關乎外部效度(結論能否推廣)。 - 隨機分派決定「組別之間能不能公平比較」——關乎內部效度(因果推論是否成立)。
唯有隨機分派,才讓我們有底氣說:差異「是處置造成的」,而不只是「和處置有關」。這也是統計素養的核心警句:相關不等於因果。觀察到兩件事一起變動,不代表一個導致另一個;只有經過設計的實驗,才有資格談因果。
盲法:擋住期待造成的偏誤
人的期待會偷偷影響結果。受試者若知道自己吃了「真藥」,可能因為心理作用而覺得好轉(安慰劑效應);研究者若知道誰是實驗組,評分時可能不自覺偏心。
- 單盲(single-blind):受試者不知道自己屬於哪一組。
- 雙盲(double-blind):連直接接觸受試者、進行評估的研究者也不知道。
雙盲隨機對照試驗(RCT)被視為驗證因果的黃金標準,原因正在於它同時關掉了「分組偏誤」和「期待偏誤」兩個漏洞。
一個帶數字的小範例:用 t 檢定判斷藥效
假設我們做了隨機對照實驗,測量兩組受試者七天後的「症狀分數」(越低越好):
- 實驗組:$n_1=30$,平均 $\bar{x}_1=4.0$,標準差 $s_1=1.5$
- 對照組:$n_2=30$,平均 $\bar{x}_2=5.0$,標準差 $s_2=1.6$
兩組平均差了 1 分。但這 1 分是「真的有效」,還是「隨機波動剛好」?我們用兩樣本 t 檢定來判斷。先算差異的標準誤:
$$SE=\sqrt{\frac{s_1^2}{n_1}+\frac{s_2^2}{n_2}}=\sqrt{\frac{1.5^2}{30}+\frac{1.6^2}{30}}=\sqrt{0.075+0.0853}\approx 0.40$$
再算 t 值:
$$t=\frac{\bar{x}_1-\bar{x}_2}{SE}=\frac{4.0-5.0}{0.40}=-2.5$$
自由度約為 $58$,雙尾 $\alpha=0.05$ 的臨界值約 $\pm 2.00$。由於 $|{-2.5}|=2.5>2.00$,我們拒絕「兩組平均相同」的虛無假設,對應的 $p$ 值約 $0.015$。
請務必正確解讀:$p\approx0.015$ 的意思是「假設藥真的無效,純靠運氣得到這麼大(或更大)差異的機率只有約 1.5%」。它不是「藥無效的機率是 1.5%」,也不是「藥有效的機率是 98.5%」。$p$ 值衡量的是資料與虛無假設的相容程度,不是假設為真的機率。
同理,若我們算出差異的 95% 信賴區間約為 $[-1.8,\,-0.2]$,正確說法是「用這個方法重複做很多次實驗,約 95% 的區間會涵蓋真正的差異」,而不是「真正的差異有 95% 機率落在這個區間內」——真正的差異是固定的,會變動的是區間。
設計沒做好,分析救不回來
回到開頭的咖啡店。如果老闆改成這樣做:在一段時間內,對每位上門客人擲硬幣決定送上舊口味或新口味(隨機分派),客人事先不知道自己喝到哪一款(盲法),最後比較兩組的滿意度(對照)——這時若新口味組分數顯著較高,他才有資格說「新口味讓人更滿意」。
實驗設計的價值,就在於把「資料的可信度」前置到蒐集之前。它提醒我們:再漂亮的圖表與檢定,都建立在一個樸素的問題上——這份資料,是怎麼來的?
深入探討(研究所視角)
從統計理論看,隨機分派之所以成立,可用 潛在結果框架(Rubin causal model) 嚴格刻畫。每個個體 $i$ 同時有兩個潛在結果 $Y_i(1)$(受處置)與 $Y_i(0)$(未受處置),但現實只能觀察到其中之一,此即「因果推論的根本難題」。我們關心的平均處置效果(ATE)為 $\tau=\mathbb{E}[Y_i(1)-Y_i(0)]$。隨機分派使處置指派 $T_i$ 獨立於潛在結果,即 $\{Y_i(1),Y_i(0)\}\perp T_i$,於是 $\mathbb{E}[Y\mid T=1]-\mathbb{E}[Y\mid T=0]$ 成為 $\tau$ 的不偏估計量——這正是隨機化消除混淆(confounding)的數學本質。
估計量的品質可用三個性質衡量。不偏性(unbiasedness):$\mathbb{E}[\hat{\theta}]=\theta$。一致性(consistency):當 $n\to\infty$ 時 $\hat{\theta}\xrightarrow{p}\theta$。有效性(efficiency):在不偏估計量中變異數最小,其下界由 Cramér–Rao 不等式 $\operatorname{Var}(\hat{\theta})\ge 1/I(\theta)$ 給出,其中 $I(\theta)$ 為 Fisher 資訊量。t 檢定中的自由度本質上是「獨立資訊量扣除估計參數後所剩」,例如以樣本平均估計後,離差受 $\sum(x_i-\bar{x})=0$ 約束,故樣本變異數除以 $n-1$ 而非 $n$(Bessel 校正),方為 $\sigma^2$ 的不偏估計。
實務上不應只看 $p$ 值,而要報告效果量(effect size)。如 Cohen's $d=\frac{\bar{x}_1-\bar{x}_2}{s_p}$,以合併標準差 $s_p$ 標準化差異,回答「差多少」而非僅「有沒有差」。$p$ 值會隨樣本數膨脹而趨小,效果量則相對穩定,這也是當代避免「統計顯著但實務無意義」的關鍵。
最大概似估計(MLE)提供更一般的估計哲學:選取使概似函數 $L(\theta)=\prod_i f(x_i;\theta)$ 最大的 $\hat{\theta}$。MLE 在正則條件下具一致性與漸近有效性,並達到 Cramér–Rao 下界,是諸多檢定(含 likelihood ratio test)的基礎。
貝氏觀點則把參數視為隨機變數,依 $P(\theta\mid D)\propto P(D\mid\theta)P(\theta)$ 更新信念,輸出的「可信區間(credible interval)」可直接說成「參數有 95% 機率落於此」——這恰恰是頻率派信賴區間不能這樣解讀的對比。
最後,實驗設計與機器學習深度相連:A/B 測試是線上隨機實驗的工業化版本;因果推論中的 uplift modeling、雙重穩健估計(doubly robust) 與 causal forests,皆在觀察資料中模擬隨機分派的精神,試圖在無法做 RCT 時逼近因果效果。