
自助法與重抽樣:用樣本模擬母體的推論引擎
從經驗分布、插入原則到 BCa 區間與漸近修正
為什麼可以「用樣本當母體」再抽一次
統計推論的核心困境是:我們只握有一組樣本,卻想知道估計量 $\hat{\theta}$ 在「無數次重複抽樣」下的抽樣分布。古典做法靠中央極限定理與 delta method 推出漸近常態,但這對中位數、相關係數、特徵值比、複雜比率等估計量往往很費力,甚至沒有乾淨的閉式變異數。
Efron(1979)提出的自助法(Bootstrap)用一個近乎魯莽卻深刻的想法繞過這個困境:既然真正的母體分布 $F$ 不可得,就用經驗分布函數 $\hat{F}_n$ 當作 $F$ 的替身,然後在 $\hat{F}_n$ 上重複抽樣,藉電腦模擬出 $\hat{\theta}$ 的抽樣分布。這就是所謂的「插入原則」(plug-in principle):把母體層次的運算,全部換成在 $\hat{F}_n$ 上的對應運算。
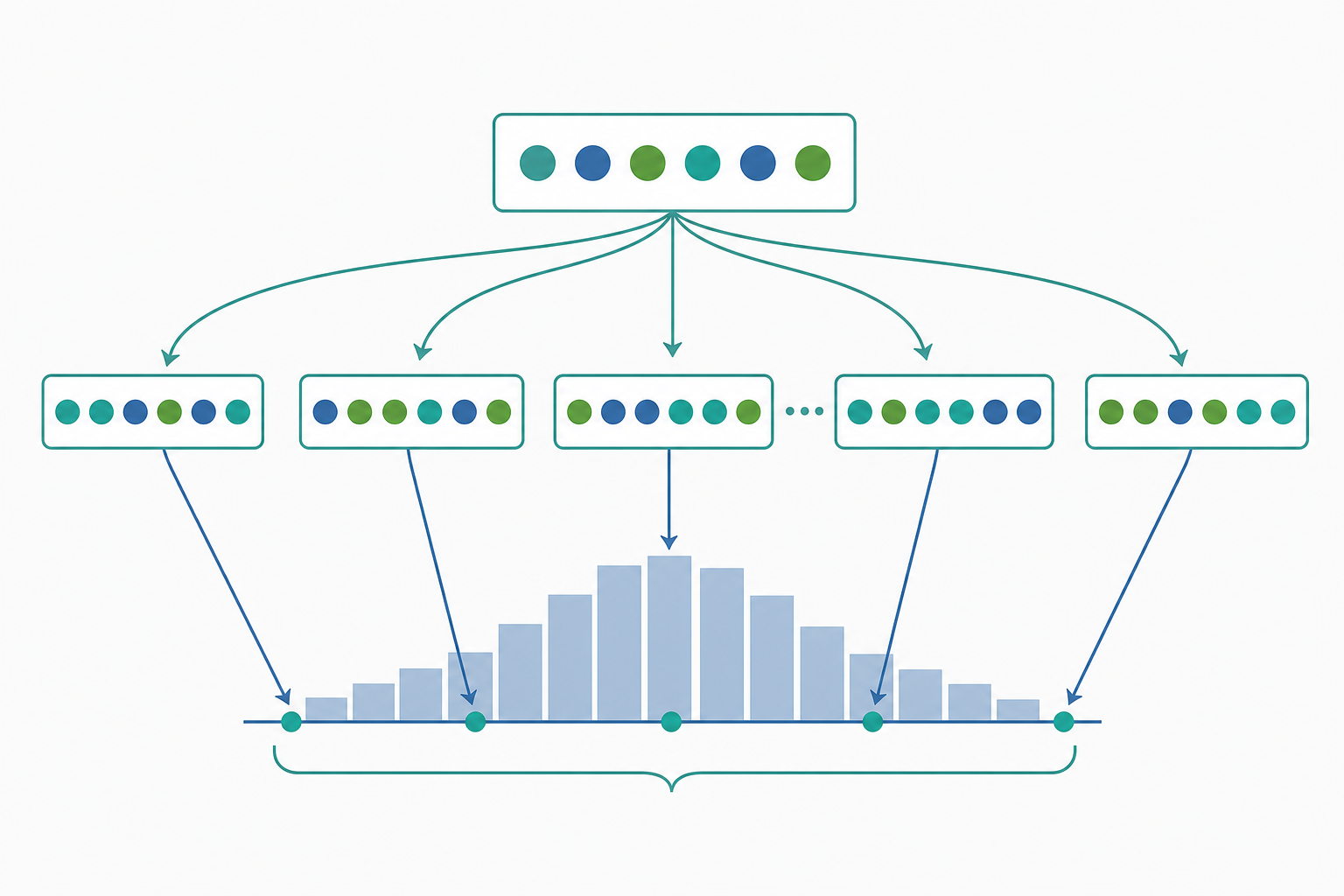
經驗分布與插入原則
設 $X_1,\dots,X_n \overset{\text{iid}}{\sim} F$,經驗分布函數定義為
$$\hat{F}_n(x) = \frac{1}{n}\sum_{i=1}^{n}\mathbf{1}\{X_i \le x\}.$$
由 Glivenko–Cantelli 定理,$\sup_x |\hat{F}_n(x) - F(x)| \xrightarrow{\text{a.s.}} 0$,亦即 $\hat{F}_n$ 一致地逼近 $F$。這是整個自助法的合法性基石:當 $\hat{F}_n \approx F$,在 $\hat{F}_n$ 上模擬出的抽樣行為,就近似真正在 $F$ 上的抽樣行為。
許多參數可寫成統計泛函 $\theta = T(F)$,例如平均數 $T(F)=\int x\,dF(x)$、變異數 $T(F)=\int (x-\mu)^2 dF(x)$。插入估計量即 $\hat{\theta} = T(\hat{F}_n)$。非參數 bootstrap 的精神是:以「從 $\hat{F}_n$ 抽樣」模擬「從 $F$ 抽樣」。從 $\hat{F}_n$ 抽出一個觀測值,等價於從原始資料 $\{X_1,\dots,X_n\}$ 中「有放回」隨機抽一個,每個被抽中的機率均為 $1/n$。
演算法與重抽樣機制
非參數 bootstrap 的步驟為:
- 從原始樣本 $\{X_1,\dots,X_n\}$ 有放回抽取 $n$ 個,得到自助樣本 $X^{*}_1,\dots,X^{*}_n$。
- 在此自助樣本上計算 $\hat{\theta}^{*} = T(\hat{F}_n^{*})$。
- 重複 $B$ 次(常取 $B = 1000 \sim 10000$),得到 $\hat{\theta}^{*}_1,\dots,\hat{\theta}^{*}_B$。
- 以這 $B$ 個值的經驗分布,近似 $\hat{\theta}$ 的抽樣分布。
標準誤的 bootstrap 估計即為這群副本的樣本標準差:
$$\widehat{\mathrm{se}}_{\text{boot}} = \sqrt{\frac{1}{B-1}\sum_{b=1}^{B}\left(\hat{\theta}^{*}_b - \bar{\hat{\theta}}^{*}\right)^2}, \quad \bar{\hat{\theta}}^{*} = \frac{1}{B}\sum_{b=1}^{B}\hat{\theta}^{*}_b.$$
一個值得記住的機率事實:原始第 $i$ 個觀測值「未」出現在某一份自助樣本中的機率為
$$\left(1 - \frac{1}{n}\right)^{n} \xrightarrow{n\to\infty} e^{-1} \approx 0.368.$$
也就是說,每份自助樣本平均只用到約 63.2% 的原始觀測值,其餘約 36.8% 被遺漏——這正是「out-of-bag」誤差估計(如隨機森林)的理論來源。
信賴區間的建構
最樸素的是百分位法(percentile method):取 $\hat{\theta}^{*}$ 的第 $\alpha/2$ 與 $1-\alpha/2$ 分位數作為區間端點。它直觀,但在估計量有偏或分布偏斜時覆蓋率不佳。
更穩健的是 BCa(bias-corrected and accelerated)區間,對偏誤與偏態(透過 jackknife 估出的加速度 $\hat{a}$)做雙重校正,端點分位數調整為
$$\alpha_1 = \Phi\!\left(\hat{z}_0 + \frac{\hat{z}_0 + z_{\alpha/2}}{1 - \hat{a}(\hat{z}_0 + z_{\alpha/2})}\right),$$
其中 $\hat{z}_0 = \Phi^{-1}\!\big(\#\{\hat{\theta}^{*}_b < \hat{\theta}\}/B\big)$ 為偏誤校正項。BCa 具有變換不變性與較高階的覆蓋準確度。
另一支是 bootstrap-t(pivotal):對每份自助樣本計算樞紐量 $t^{*} = (\hat{\theta}^{*} - \hat{\theta})/\widehat{\mathrm{se}}^{*}$,再用其分位數反推區間。它在理論上可達二階準確(覆蓋誤差 $O(n^{-1})$ 而非 $O(n^{-1/2})$),代價是需要每份樣本內部的 $\widehat{\mathrm{se}}^{*}$。
定量小範例
假設我們有 $n=5$ 筆觀測:$\{2,\,4,\,4,\,6,\,9\}$,欲估計母體平均並求其 bootstrap 標準誤。原樣本平均 $\hat{\theta} = (2+4+4+6+9)/5 = 5$。
為示範,手算三份自助樣本(實務 $B$ 需上千):
- 第 1 份抽到 $\{4,4,6,9,2\}$:平均 $= 25/5 = 5$。
- 第 2 份抽到 $\{2,2,4,4,6\}$:平均 $= 18/5 = 3.6$。
- 第 3 份抽到 $\{6,9,9,4,4\}$:平均 $= 32/5 = 6.4$。
三個副本均值 $\bar{\hat{\theta}}^{*} = (5+3.6+6.4)/3 = 5$。bootstrap 標準誤
$$\widehat{\mathrm{se}}_{\text{boot}} = \sqrt{\frac{(5-5)^2+(3.6-5)^2+(6.4-5)^2}{3-1}} = \sqrt{\frac{0+1.96+1.96}{2}} = \sqrt{1.96} = 1.4.$$
作為理論對照,平均數的解析標準誤為 $s/\sqrt{n}$。樣本變異數 $s^2 = \frac{1}{4}\big[(2-5)^2+(4-5)^2+(4-5)^2+(6-5)^2+(9-5)^2\big] = 28/4 = 7$,故 $s/\sqrt{n} = \sqrt{7}/\sqrt{5} \approx 1.18$。三份樣本估出的 $1.4$ 因 $B$ 太小而偏高;當 $B \to \infty$,bootstrap 標準誤會收斂到接近 $\sqrt{(n-1)/n}\cdot s/\sqrt{n}$(bootstrap 用的是除以 $n$ 的變異數版本),與解析值高度一致。這正說明 bootstrap 並非魔法,而是在大 $B$ 下重現古典結果,並推廣到沒有閉式公式的統計量。
適用範圍與素養提醒
自助法強大,但不是萬靈丹。它的有效性建立在「觀測值近似 iid」與「估計量為 $F$ 的平滑泛函」之上。對極端值統計量(如樣本最大值)、重尾分布下的平均數、或強相關時間序列的樸素 bootstrap,覆蓋率可能嚴重失準;後者需改用 block bootstrap 以保留相依結構。
統計素養上要警惕三點。其一,bootstrap 估的是 $\hat{\theta}$ 環繞其自身期望的變異,並不會自動修正模型設定錯誤或選擇偏誤——抽樣若有偏,重抽一萬次仍有偏。其二,窄的 bootstrap 信賴區間不等於因果效果,相關仍不是因果。其三,信賴區間是「程序在重複抽樣下涵蓋真值的長期比例」,不是「真值落在此區間的機率」;p 值也不是「虛無為真的機率」。這些誤解在 bootstrap 結果報告時尤其容易發生,因為模擬的具體數字會給人虛假的精確感。
深入探討(研究所視角)
漸近合理性的形式化。 bootstrap 的嚴格根據來自 Bickel 與 Freedman(1981)以及 Singh(1981)的成果:對平滑統計量,bootstrap 分布在條件機率意義下幾乎必然弱收斂到與真實抽樣分布相同的極限。更精細地,透過 Edgeworth 展開可證 bootstrap 達成漸近修正(asymptotic refinement):對樞紐量,bootstrap-t 的覆蓋誤差為 $O(n^{-1})$,優於常態近似的 $O(n^{-1/2})$。直覺是 bootstrap 自動捕捉了 Edgeworth 展開中與偏態相關的 $n^{-1/2}$ 項,這是純常態近似無法做到的。但這套保證有先決條件——當統計量不可微(如最大值落在母體支撐邊界)或極限分布退化時,樸素 bootstrap 會失效,需改用 $m$-out-of-$n$ bootstrap 或 subsampling(Politis–Romano)。
與最大概似、動差法的關係。 參數 bootstrap 假設 $F = F_{\hat\theta}$ 屬已知參數族,先用 MLE 估出 $\hat\theta$,再從 $F_{\hat\theta}$ 模擬。當模型正確,它能逼近 MLE 抽樣分布並繼承其漸近效率 $\hat{\theta}_{\text{MLE}} \approx \mathcal{N}(\theta, I(\theta)^{-1})$,其中 $I(\theta)$ 為 Fisher 資訊。非參數 bootstrap 則對應「動差法/經驗概似」這條不設定分布族的路線;Owen 的經驗概似(empirical likelihood)可視為對 $\hat{F}_n$ 上的多項分布做 profile 概似,與 bootstrap 共享插入哲學,卻具備 Wilks 型卡方極限與內建的 Bartlett 可修正性。
貝氏對應:Bayesian bootstrap。 Rubin(1981)的 Bayesian bootstrap 不對每個觀測賦予等權 $1/n$,而是從 Dirichlet 分布 $\mathrm{Dir}(1,\dots,1)$ 抽出隨機權重 $(w_1,\dots,w_n)$,計算加權統計量。它可視為以 Dirichlet process 為先驗、在無資訊極限下的後驗模擬,其後驗分布與 Efron bootstrap 在一階上一致。這座橋揭示了 bootstrap 的「準貝氏」身分:頻率學派的重抽樣,其實對應到一個特定先驗下的後驗不確定性量化。
與機器學習、因果推論的連結。 bootstrap 是 bagging(bootstrap aggregating)的核心——隨機森林以自助樣本訓練多棵樹並平均,藉降低變異提升泛化;前述 $e^{-1}$ 的遺漏機率直接給出 out-of-bag 誤差這個免費的驗證估計。在因果推論中,bootstrap 廣泛用於對 IPW、AIPW、matching 等估計量量化不確定性;但須留意 matching 後的 bootstrap 在理論上並非總是合理(Abadie–Imbens),因配對引入的相依破壞了 iid 假設。前沿方向如 wild bootstrap(處理異質變異)、cluster bootstrap(處理群集相依)、以及與雙重機器學習(double/debiased ML)結合的推論程序,都是把這個 1979 年的古老想法,持續推向高維與複雜依賴結構的當代研究。