
用一條線預測未來:迴歸分析與最小平方法
從散布的資料點中找出最佳直線,學會用一個變數合理推估另一個變數。
從一條線開始:當我們想用一個變數猜另一個變數
想像你是一位健身教練,手上有一群學員的資料:每個人「每週運動時數」與「體脂率」。你直覺認為運動愈多、體脂愈低,但這個關係到底有多強?如果有位新學員每週運動 5 小時,你能不能給出一個合理的體脂率估計?
迴歸分析(regression)正是為了回答這類問題而生。它的核心精神很單純:用一條直線(或更複雜的曲線)來描述兩個變數之間的關係,並用這條線做預測。 我們把用來預測的變數叫做自變數(或解釋變數)$x$,把想預測的變數叫做依變數(或反應變數)$y$。
最常見的形式是簡單線性迴歸,假設兩者的關係可以寫成:
$$y = \beta_0 + \beta_1 x + \varepsilon$$
其中 $\beta_0$ 是截距($x=0$ 時的預測值),$\beta_1$ 是斜率($x$ 每增加一單位,$y$ 平均變化多少),而 $\varepsilon$ 是「誤差項」——代表現實世界中無法被這條直線解釋的隨機波動。
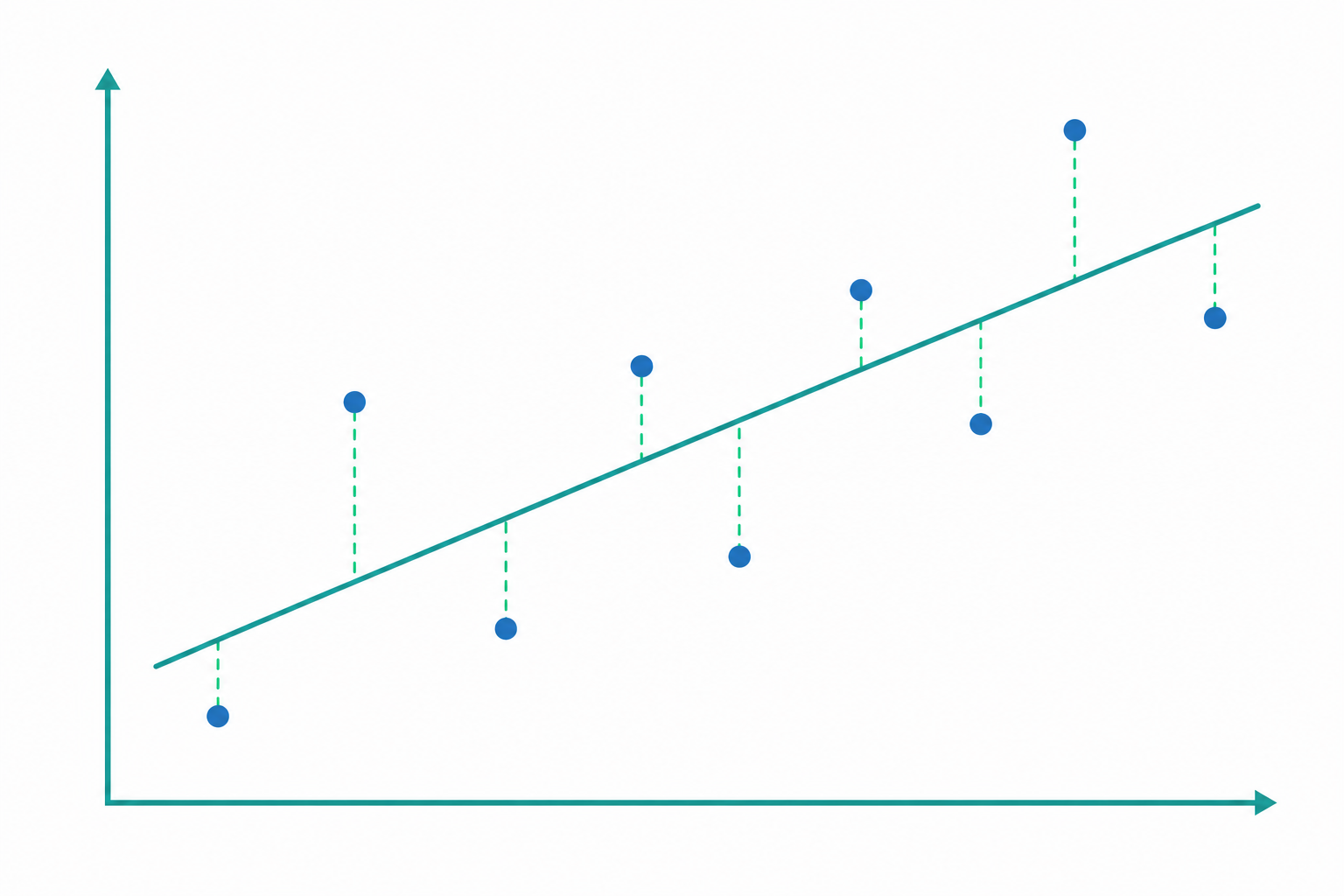
最小平方法:怎麼找出「最好」的那條線
能畫過一堆散布點的直線有無限多條,哪一條最好?迴歸給出的答案是最小平方法(Ordinary Least Squares, OLS)。
對每個資料點,直線給出的預測值是 $\hat{y}_i = \hat{\beta}_0 + \hat{\beta}_1 x_i$,而它與真實值 $y_i$ 的差距稱為殘差(residual)$e_i = y_i - \hat{y}_i$。最小平方法的目標,是讓所有殘差的平方和最小:
$$\min_{\beta_0,\beta_1} \sum_{i=1}^{n} \left( y_i - \beta_0 - \beta_1 x_i \right)^2$$
為什麼是平方而不是絕對值?平方會放大「離得遠」的點的懲罰,也讓數學上有漂亮的封閉解。透過微積分求極值,可以解出:
$$\hat{\beta}_1 = \frac{\sum (x_i - \bar{x})(y_i - \bar{y})}{\sum (x_i - \bar{x})^2}, \qquad \hat{\beta}_0 = \bar{y} - \hat{\beta}_1 \bar{x}$$
注意這條最佳直線必定通過點 $(\bar{x}, \bar{y})$,也就是資料的「重心」。
動手算一個小例子
假設我們收集了 5 位學員的資料:
| 學員 | 每週運動時數 $x$ | 體脂率 $y$ |
|---|---|---|
| A | 1 | 28 |
| B | 2 | 26 |
| C | 3 | 23 |
| D | 4 | 22 |
| E | 5 | 19 |
第一步:算平均數。
$$\bar{x} = \frac{1+2+3+4+5}{5} = 3, \qquad \bar{y} = \frac{28+26+23+22+19}{5} = 23.6$$
第二步:算斜率所需的分子與分母。
| $x_i-\bar{x}$ | $y_i-\bar{y}$ | 乘積 | $(x_i-\bar{x})^2$ |
|---|---|---|---|
| -2 | 4.4 | -8.8 | 4 |
| -1 | 2.4 | -2.4 | 1 |
| 0 | -0.6 | 0 | 0 |
| 1 | -1.6 | -1.6 | 1 |
| 2 | -4.6 | -9.2 | 4 |
分子 $\sum (x_i-\bar{x})(y_i-\bar{y}) = -8.8 - 2.4 + 0 - 1.6 - 9.2 = -22$,分母 $\sum (x_i-\bar{x})^2 = 10$。
第三步:得到斜率與截距。
$$\hat{\beta}_1 = \frac{-22}{10} = -2.2, \qquad \hat{\beta}_0 = 23.6 - (-2.2)(3) = 30.2$$
所以迴歸方程式是 $\hat{y} = 30.2 - 2.2x$。解讀:每週多運動 1 小時,體脂率平均下降約 2.2 個百分點。對那位每週運動 5 小時的新學員,預測體脂率為 $30.2 - 2.2 \times 5 = 19.2$。
這條線到底配得好不好?
我們用判定係數 $R^2$ 來衡量。它代表「$y$ 的變異中,有多少比例被這條直線解釋掉了」:
$$R^2 = 1 - \frac{\sum (y_i - \hat{y}_i)^2}{\sum (y_i - \bar{y})^2}$$
$R^2$ 介於 0 到 1 之間,愈接近 1 表示直線配得愈好。在上例中 $R^2$ 高達約 0.97,意味運動時數幾乎能解釋體脂率的全部變異——當然,這是因為我們刻意挑了乾淨的教學數據。
$R^2$ 也等於相關係數 $r$ 的平方。相關係數衡量兩變數線性關係的強度與方向,範圍從 $-1$ 到 $+1$。
最重要的警告:相關不等於因果
這是統計素養的核心。迴歸找出 $x$ 與 $y$ 的關聯,但絕不能單憑一條迴歸線就宣稱「運動導致體脂下降」。也許是某個第三變數(例如自律的生活習慣)同時推動了「多運動」與「低體脂」,造成兩者一起變動。經典的笑話是:冰淇淋銷量與溺水人數高度正相關,但吃冰淇淋不會讓人溺水——真正的推手是夏天的高溫。
要主張因果,需要隨機對照實驗或嚴謹的因果推論設計,而不是把一條迴歸線的斜率讀成「原因的力道」。
另一個常見誤解是外推(extrapolation)。我們的資料只涵蓋 1 到 5 小時,若把方程式硬套到每週運動 15 小時,算出體脂 $30.2 - 2.2 \times 15 = -2.8$,竟然是負值!這顯然荒謬。直線關係只在觀測範圍內可信,超出範圍的預測極不可靠。
迴歸分析是資料科學最基礎、也最被廣泛使用的工具之一。掌握它,你就握住了「用資料說話」的第一把鑰匙。
深入探討(研究所視角)
OLS 估計量之所以被偏愛,源自 Gauss–Markov 定理:在線性迴歸的古典假設下(誤差具零均值、同質變異 $\text{Var}(\varepsilon_i)=\sigma^2$、彼此不相關),OLS 是所有線性不偏估計量中變異數最小者,即 BLUE(Best Linear Unbiased Estimator)。值得強調的是,這個定理不要求誤差服從常態分配;常態性只在做精確的小樣本檢定與信賴區間時才需要。
從估計量性質看,$\hat{\beta}_1$ 是 $\beta_1$ 的不偏估計($E[\hat{\beta}_1]=\beta_1$),並在弱條件下具一致性(樣本增大時依機率收斂到真值)。誤差變異的不偏估計為 $\hat{\sigma}^2 = \frac{1}{n-2}\sum e_i^2$,分母用 $n-2$ 而非 $n$,正是因為估計 $\beta_0$ 與 $\beta_1$ 各消耗一個自由度。
當誤差為常態時,OLS 與最大概似估計(MLE)恰好重合:最大化常態概似函數等價於最小化殘差平方和。這把「平方損失」從一個直觀選擇提升為機率模型下的最優推論。
對係數做檢定時,$t = \hat{\beta}_1 / \text{SE}(\hat{\beta}_1)$ 服從自由度 $n-2$ 的 $t$ 分配。這裡要避免 p 值誤解:$p<0.05$ 不代表「$\beta_1$ 為真的機率」,也不代表效果「重要」;它只是「若虛無假設 $\beta_1=0$ 為真,觀察到如此極端統計量的機率」。大樣本下即使微不足道的斜率也可能「顯著」,因此應同時報告效果量(如 $R^2$、標準化係數)與信賴區間。同樣地,95% 信賴區間指的是「此類程序在長期重複下有 95% 會涵蓋真值」,而非「真值有 95% 機率落在這一個區間內」。
貝氏觀點則把 $\beta$ 視為隨機變數,給定先驗後以資料更新為後驗分配 $p(\beta\mid \text{data}) \propto p(\text{data}\mid \beta)\,p(\beta)$。有趣的是,加上常態先驗會自然導出 Ridge 迴歸(L2 正則化),而 Laplace 先驗對應 Lasso(L1 正則化)——這正是迴歸與機器學習的接點。在高維或共線性嚴重的情境,正則化以引入少量偏誤換取大幅降低變異,體現了偏誤—變異權衡(bias–variance tradeoff),也是現代預測模型避免過度配適的核心思想。