
用一個數字代表一整群人:平均數、中位數、眾數
三把測量「中心」的尺,為什麼常常給你不一樣的答案?
用一個數字代表一整群人
想像你是某高中的班導,校長走進辦公室問:「你們班數學考得怎麼樣?」你總不能把 35 個分數一個一個唸出來。你會說:「平均大概 72 分。」這一句話背後,藏著統計學最古老也最實用的想法——用一個數字,代表一整群資料。
這個「代表值」在統計學裡叫做集中趨勢(central tendency),意思是:資料雖然散落各處,但往往會圍繞某個中心點聚集。我們的任務,就是找出那個中心。最常見的三把尺,是平均數、中位數、眾數。它們看起來都在做同一件事,卻常常給出不一樣的答案——而理解「為什麼不一樣」,正是統計素養的起點。
平均數:把資源攤平分
最直覺的代表值是算術平均數(mean)。把所有數字加起來,再除以個數:
$$\bar{x}=\frac{1}{n}\sum_{i=1}^{n}x_i$$
其中 $\bar{x}$(讀作 x-bar)是平均數,$n$ 是資料筆數,$x_i$ 是第 $i$ 筆資料。
舉個具體例子。某小組六位同學的數學成績是:
$$50,\ 60,\ 70,\ 75,\ 80,\ 100$$
平均數是:
$$\bar{x}=\frac{50+60+70+75+80+100}{6}=\frac{435}{6}=72.5$$
平均數可以想像成「把所有人的分數倒進一個大桶子裡攪勻,再平均分回每個人手上」——每個人都拿到 72.5 分。它用到了每一筆資料的全部資訊,這是它最大的優點,也是它最大的弱點。
平均數的致命弱點:怕極端值
把上面那位考 100 分的同學換成一位轉學生考了 0 分,其他不變:
$$50,\ 60,\ 70,\ 75,\ 80,\ 0$$
新的平均數變成 $\frac{335}{6}\approx55.8$。一個人就把全組平均拉低了將近 17 分。這就是平均數對極端值(outlier)極度敏感的問題。
真實世界裡,這種情況非常常見。最經典的例子是「平均薪資」。如果一個社區裡住了 99 個月薪 3 萬的上班族,和 1 位月薪 3000 萬的企業主,那麼「平均月薪」會高達約 33 萬——但這個數字完全無法代表社區裡任何一個人的真實生活。媒體報導「國民平均薪資」時,常常就掉進這個陷阱。
當資料分布不對稱(偏態,skewed)時,平均數會被「長尾」那一側拉走,不再位於我們直覺認為的「中心」。這時候,我們需要另一把更穩健的尺。
中位數:站在隊伍正中間的人
中位數(median)的定義很簡單:把所有資料由小到大排好,正中間那一個就是中位數。它不看數值大小,只看「排名」。
回到剛剛那組含 0 分的資料,先排序:
$$0,\ 50,\ 60,\ 70,\ 75,\ 80$$
因為共有 6 筆(偶數),中間沒有單一一個,於是取中間兩筆的平均:
$$\text{中位數}=\frac{60+70}{2}=65$$
注意:不管那個 0 分換成 0 還是 100,中位數附近的 60 與 70 都不動,中位數依然穩穩落在 65 附近。這就是中位數抗極端值(robust)的特性。
一般而言,資料筆數為 $n$ 時:
- 若 $n$ 為奇數,中位數是第 $\frac{n+1}{2}$ 筆。
- 若 $n$ 為偶數,中位數是第 $\frac{n}{2}$ 與第 $\frac{n}{2}+1$ 筆的平均。
正因為這個穩健性,政府公布所得、房價時,越來越傾向用「中位數」而非平均數——中位數所得才真正代表「最中間那個家庭」的處境。
眾數:出現最多次的那個
第三把尺是眾數(mode),意思是「出現次數最多的數值」。它特別適合類別型資料——例如全班最喜歡的飲料、最多人選的社團、最暢銷的鞋碼。這些資料根本沒辦法算平均(「最喜歡的飲料平均是奶茶」毫無意義),但「最多人選奶茶」就很清楚。
例如某班鞋碼分布為:
$$23,\ 24,\ 24,\ 25,\ 25,\ 25,\ 26$$
出現最多次的是 25(三次),所以眾數是 25。一筆資料可能有一個眾數、多個眾數(雙峰),也可能沒有明顯眾數。鞋店進貨時,老闆在乎的是眾數,而不是平均腳長。
三者之間的關係:分布告訴你該用誰
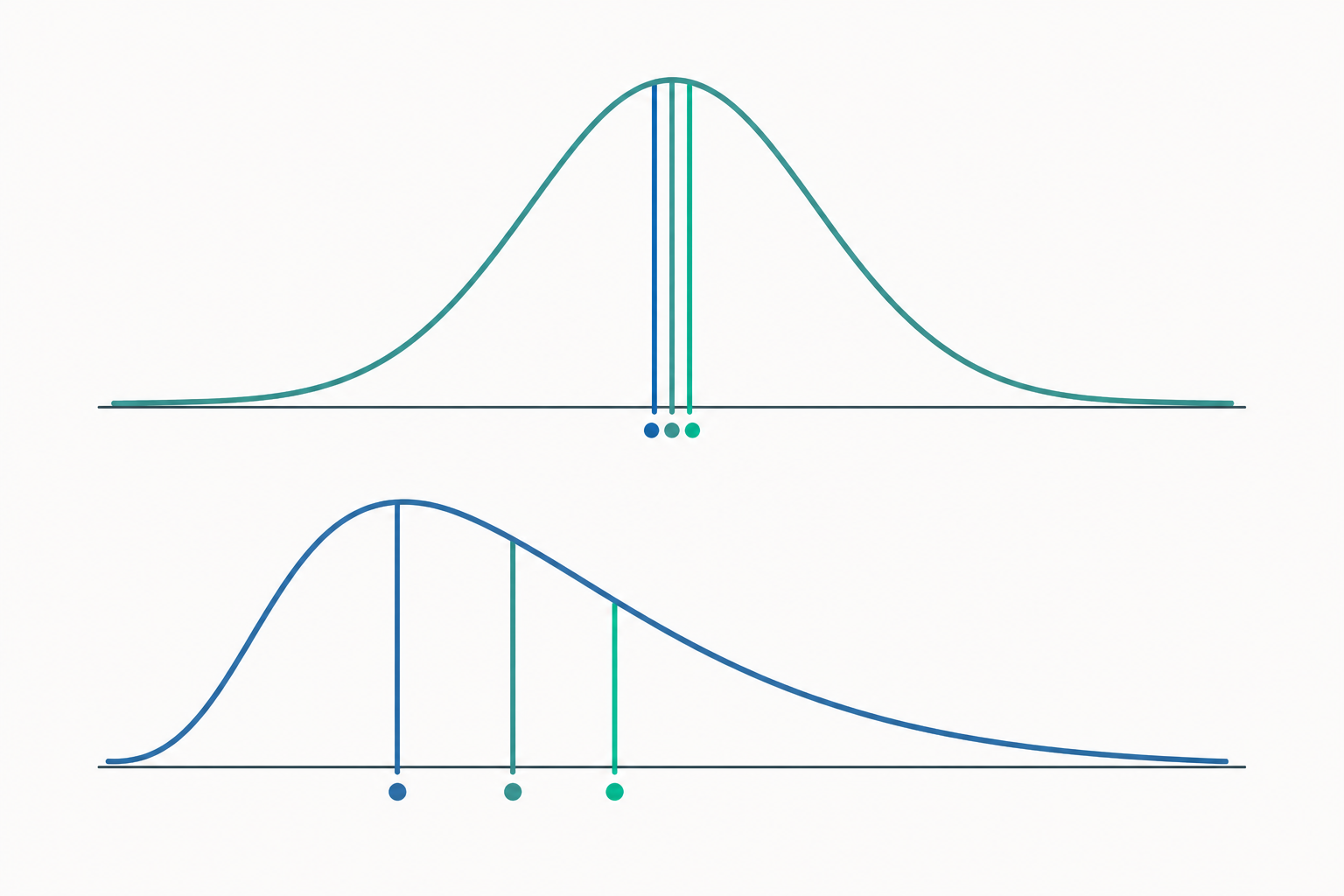
對於對稱的分布(例如理想的常態分布,那條漂亮的鐘形曲線),平均數、中位數、眾數三者會幾乎重合在中央。
但對於右偏(正偏)的分布——例如收入、房價、等待時間,少數極大值把右尾拉長,三者會排成:
$$\text{眾數} < \text{中位數} < \text{平均數}$$
平均數被右尾拉得最遠,眾數待在最高峰處,中位數則居中。左偏時順序則相反。記住這個順序,你光看「平均數和中位數差多少」,就能粗略判斷一筆資料偏不偏、偏哪邊。
一個常見的素養陷阱
統計素養的關鍵,不是會算,而是會問「這個數字適合嗎?」。看到「平均」兩個字,先問三件事:
- 這是哪一種平均? 是算術平均,還是中位數被誤稱為「平均」?
- 有沒有極端值在搞鬼? 如果分布偏態,平均數可能誤導。
- 資料是什麼型態? 類別資料只能用眾數,硬算平均毫無意義。
還有一個更深的陷阱:集中趨勢只描述「中心在哪」,完全不告訴你「資料散得多開」。兩個班平均都是 72 分,一班可能全部落在 70–74,另一班可能從 30 分到 100 分都有。代表值相同,故事卻天差地別。所以集中趨勢永遠要和離散程度(標準差、四分位距)一起看,才不會被單一數字騙了。
深入探討(研究所視角)
在數理統計的框架下,這三個代表值有更精準的身份。它們其實是不同損失函數下的最佳估計。中心 $c$ 的「代表性」可由與資料的偏離總量衡量:平均數最小化平方損失 $\sum (x_i-c)^2$,中位數最小化絕對損失 $\sum |x_i-c|$,而眾數最小化 0-1 損失(極限上對應機率密度的最高點)。這解釋了平均數為何對極端值敏感(平方放大了大偏差),而中位數為何穩健。
從估計理論看,平均數作為母體期望值 $\mu=E[X]$ 的估計量 $\bar{X}$,具有優良性質。它是不偏的(unbiased),因 $E[\bar{X}]=\mu$;由大數法則知它是一致的(consistent),$\bar{X}\xrightarrow{P}\mu$;在常態母體下,它還是有效的(efficient)——其變異數達到 Cramér–Rao 下界,且等同最大概似估計(MLE)。最大概似法選取使概似函數 $L(\theta)=\prod f(x_i;\theta)$ 最大的參數;對常態分布微分對數概似,恰好解得 $\hat{\mu}=\bar{x}$,這也是 $n-1$ 自由度(在估計變異數時,因已耗用一個自由度於 $\bar{x}$)概念的源頭。
但「有效」是有前提的。在重尾分布(如柯西分布,其期望值根本不存在)下,樣本平均數毫無用處——再多樣本也不收斂,此時中位數才是合理的位置估計。這正是穩健統計(robust statistics)的研究核心,並衍生出修剪平均數(trimmed mean)、M-估計量等折衷工具,以崩潰點(breakdown point)量化估計量能承受多少比例的污染(平均數崩潰點為 0,中位數高達 50%)。
從貝氏觀點,給定後驗分布 $p(\theta\mid \text{data})$,你選哪個代表值取決於你的損失函數:平方損失下的貝氏估計是後驗平均,絕對損失下是後驗中位數,0-1 損失下則是後驗眾數(即 MAP, maximum a posteriori)。可見「該用哪個中心」在貝氏架構裡是一個明確的決策論問題,而非任意選擇。
在機器學習裡,這組概念無所不在:迴歸最小化均方誤差(MSE)等於在估計條件平均數 $E[Y\mid X]$,而分位數迴歸(quantile regression)與 MAE 損失則估計條件中位數,對離群樣本更穩健;分類問題裡,常數基準模型直接預測眾數類別。理解集中趨勢與損失函數的對應,能讓你在面對偏態資料時,有意識地選擇優化目標,而不是反射性地套用 MSE。最後一個提醒:集中趨勢是邊際性質,辛普森悖論(Simpson's paradox)警告我們,分組後的趨勢可能整體反轉——任何代表值都不該脫離其條件結構被單獨解讀。