
旋轉、簡單結構與多分相關:因素分析為何解不唯一
深入旋轉不確定性、轉軸準則、平行分析與李克特資料的多分相關,解開「同份資料不同因素」之謎
當兩位研究者用同一份資料,卻萃取出完全不同的因素時
你已經知道因素分析(Factor Analysis)能把一堆題目縮成少數潛在構念(latent construct),也大致理解主成分分析(PCA)和共同因素模型(common factor model)的差別。但這裡有個讓許多研究生卡住的真實情境:兩個人拿同一份問卷資料跑探索性因素分析(Exploratory Factor Analysis, EFA),一個說「這是三因素結構」,另一個說「明明是四因素,而且第二個因素該轉軸成斜交(oblique)」,最後兩人的因素負荷矩陣(factor loading matrix)長得天差地遠——卻都通過了統計檢定。
這不是有人算錯,而是因素分析在萃取數目(number of factors)與轉軸(rotation)這兩個環節上存在「旋轉不確定性(rotational indeterminacy)」。入門篇告訴你「因素分析在做什麼」,這篇進階文章要回答的是:為什麼解不唯一?我們憑什麼選定一個解?以及當題目是李克特(Likert)類別資料時,皮爾森相關(Pearson correlation)為什麼會騙你?
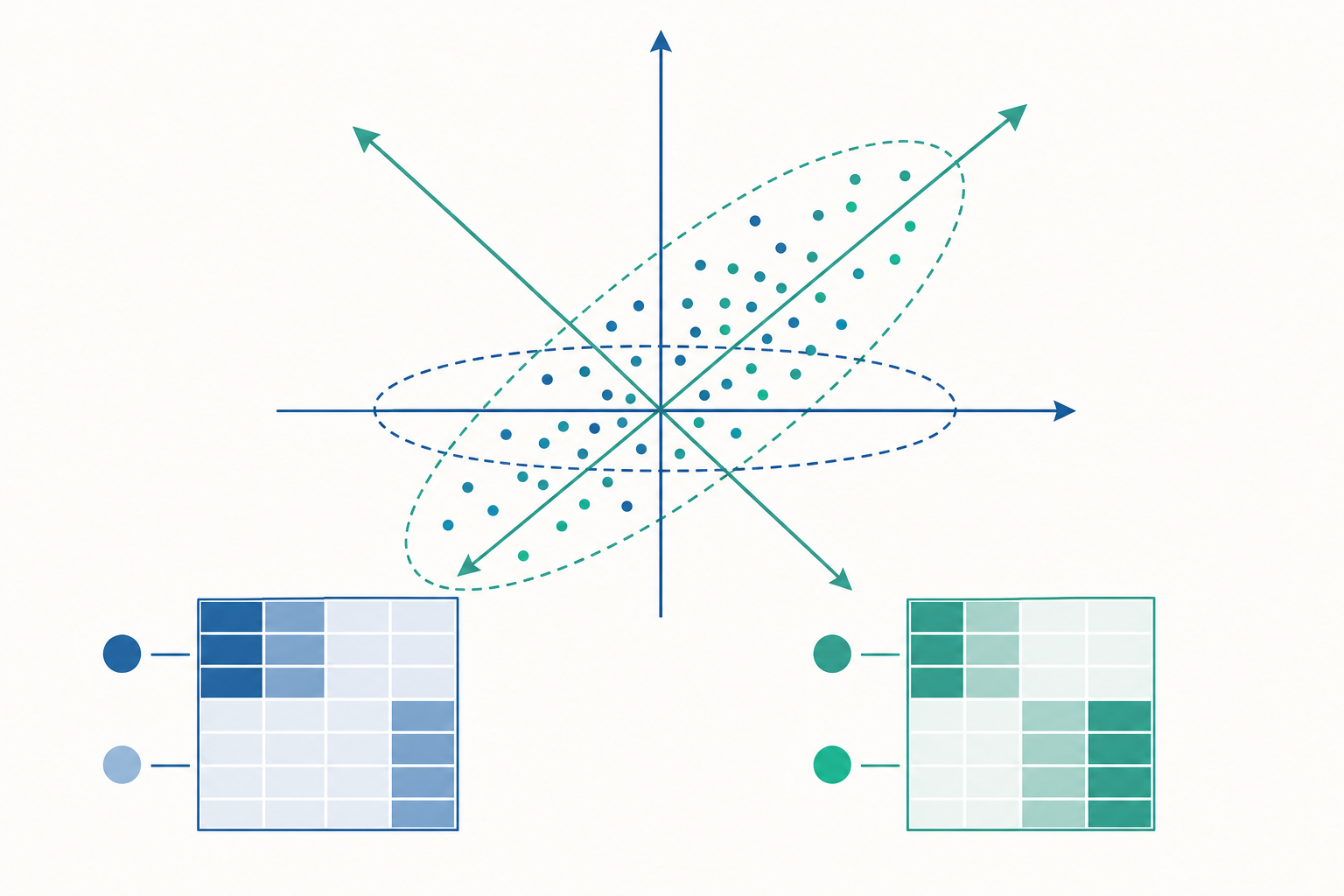
旋轉不確定性:解為何天生不唯一
共同因素模型把觀察變項的相關矩陣 $\mathbf{R}$ 拆解為:
$$ \mathbf{R} = \mathbf{\Lambda}\mathbf{\Phi}\mathbf{\Lambda}^{\top} + \mathbf{\Psi} $$
其中 $\mathbf{\Lambda}$ 是 $p \times m$ 的因素負荷矩陣($p$ 個題目、$m$ 個因素),$\mathbf{\Phi}$ 是因素之間的相關矩陣,$\mathbf{\Psi}$ 是對角的唯一性(uniqueness)矩陣。
關鍵問題在於:對任何一個 $m \times m$ 的可逆矩陣 $\mathbf{T}$,我們都可以寫出
$$ \mathbf{\Lambda}\mathbf{\Phi}\mathbf{\Lambda}^{\top} = (\mathbf{\Lambda}\mathbf{T})(\mathbf{T}^{-1}\mathbf{\Phi}\mathbf{T}^{-\top})(\mathbf{T}^{\top}\mathbf{\Lambda}^{\top}). $$
也就是說,把負荷矩陣換成 $\mathbf{\Lambda}\mathbf{T}$、把因素相關換成對應的形式,重建出來的 $\mathbf{R}$ 完全一樣。資料無法區分這無窮多組解,這就是旋轉不確定性。當 $\mathbf{T}$ 是正交矩陣($\mathbf{T}^{\top}\mathbf{T}=\mathbf{I}$)時,因素之間維持正交(orthogonal),稱為正交轉軸;當 $\mathbf{T}$ 不要求正交時,允許因素相關,稱為斜交轉軸(oblique rotation)。
換句話說,萃取(extraction)決定的是「因素張開的子空間」,而轉軸決定的是「在這個子空間裡選哪一組座標軸」。統計上這些解的配適度(fit)完全相同——選哪一個,靠的是可解釋性這個外部準則,而不是配適度本身。
簡單結構:用什麼準則挑座標軸
既然數學上解不唯一,Thurstone 提出「簡單結構(simple structure)」作為挑選原則:好的轉軸應該讓每個題目只在少數因素上有高負荷、在其餘因素上接近零。這讓因素容易命名與詮釋。
現代轉軸法把「簡單結構」操作化為一個可最小化的複雜度準則。以 Varimax(正交轉軸的主流)為例,它最大化各因素內負荷平方的變異數:
$$ V = \sum_{j=1}^{m}\left[\frac{1}{p}\sum_{i=1}^{p}\lambda_{ij}^{4} - \left(\frac{1}{p}\sum_{i=1}^{p}\lambda_{ij}^{2}\right)^{2}\right]. $$
直覺上,最大化平方負荷的變異數,等於把負荷往「很大」或「很小」兩端推,避免中間模糊地帶。斜交轉軸常用的 Oblimin、Promax 則進一步放開因素正交的限制——因為在心理與教育構念裡,潛在因素本來就常彼此相關(例如「數學焦慮」與「考試焦慮」)。
該選正交還是斜交? 一個務實的準則是:先跑斜交,檢查因素相關矩陣 $\mathbf{\Phi}$。若因素間相關普遍低於約 $0.2$,正交解幾乎一樣、且更簡潔;若相關明顯($>0.3$),硬套正交會把真實的因素重疊「藏」進負荷裡,造成詮釋失真。斜交解要分清楚兩個矩陣:樣式矩陣(pattern matrix)是控制其他因素後的偏迴歸係數,用來命名因素;結構矩陣(structure matrix)是題目與因素的相關。兩者在斜交下不相等,報告負荷時務必註明用的是哪一個。
該萃取幾個因素:別只信 Kaiger 法則
入門篇大概提過「特徵值大於 1(Kaiser-Guttman 準則)」與陡坡圖(scree plot)。進階地說,這兩者都不可靠:Kaiser 法則在題目多時嚴重高估因素數,陡坡圖的「拐點」判讀又太主觀。現在方法學上的共識是改用平行分析(parallel analysis)。
平行分析的邏輯很乾淨:產生許多份與你資料「同樣大小、但變項間完全隨機無關」的模擬資料,計算它們相關矩陣的特徵值分布。只有當你真實資料的第 $k$ 個特徵值,超過隨機資料第 $k$ 個特徵值的第 95 百分位數時,才保留第 $k$ 個因素。這等於問:「這個維度解釋的變異,是否顯著超過純抽樣雜訊能製造出來的?」
更嚴謹的場景下,會搭配 EFA 的配適指標(如 RMSEA、TLI)與後續可重複性,而不是把因素數交給單一規則決定。
動手算一下:旋轉如何重新分配負荷
假設兩個題目、兩個因素,未轉軸的負荷矩陣是
$$ \mathbf{\Lambda} = \begin{bmatrix} 0.80 & 0.40 \\ 0.40 & 0.80 \end{bmatrix}. $$
兩個題目都「橫跨」兩個因素,難以命名。我們套一個 $20^{\circ}$ 的正交旋轉,$\mathbf{T}=\begin{bmatrix}\cos20^{\circ} & -\sin20^{\circ}\\ \sin20^{\circ} & \cos20^{\circ}\end{bmatrix}\approx\begin{bmatrix}0.940 & -0.342\\ 0.342 & 0.940\end{bmatrix}$。
計算 $\mathbf{\Lambda}\mathbf{T}$:
- 題目 1:$(0.80\times0.940 + 0.40\times0.342,\; 0.80\times(-0.342)+0.40\times0.940) = (0.889,\; 0.102)$
- 題目 2:$(0.40\times0.940 + 0.80\times0.342,\; 0.40\times(-0.342)+0.80\times0.940) = (0.650,\; 0.615)$
題目 1 的負荷從 $(0.80, 0.40)$ 變成 $(0.889, 0.102)$——更乾淨地落在因素 1。注意兩件事:第一,共同性(communality)不變。題目 1 旋轉前 $0.80^2+0.40^2=0.80$,旋轉後 $0.889^2+0.102^2\approx0.80$,完全相同。旋轉只是「轉動座標軸」,不改變題目被解釋的總變異。第二,旋轉是全域操作——讓題目 1 變乾淨的同時,題目 2 反而更橫跨。真正的轉軸演算法(如 Varimax)會在所有題目間找一個讓整體最接近簡單結構的角度,而非只顧一題。
別用皮爾森相關跑李克特資料
這是教育與心理計量裡最常被忽略、卻最致命的一點。標準 EFA/PCA 吃的是皮爾森相關矩陣,而皮爾森相關假設變項是連續且雙變量常態的。但問卷題目幾乎都是 5 點或 7 點李克特類別資料——有序而非連續。
直接對李克特資料算皮爾森相關,會產生兩個假象:
- 離散化衰減(attenuation):把連續的潛在態度切成幾格,相關會被系統性低估,使共同性偏低、像是「有更多測量誤差」。
- 難度因素(difficulty factor):當題目的反應分布偏態方向不同(有的偏易、有的偏難),皮爾森相關會憑空生出一個其實只反映「分布形狀差異」的假因素。許多論文裡那個「莫名其妙的第二因素」,根源就在這。
正解是改用多分相關(polychoric correlation):它假設每個有序題目背後有一個連續、常態的潛在反應變項 $y^{*}$,題目的類別只是 $y^{*}$ 跨過若干閾值(threshold)後的結果,再估計這些潛在變項兩兩之間的相關。把 EFA 建立在多分相關矩陣上,離散化衰減與難度因素大致就消失了。
看一個例子:多分相關救回真實結構
假設兩題的潛在態度本來相關 $\rho=0.60$。受試者填答時,潛在分數跨過閾值才會勾選較高選項。若你直接對勾選出來的 5 點分數算皮爾森相關,常會得到大約 $0.45 \sim 0.50$——被系統性低估。而多分相關會估回接近 $0.60$ 的值,因為它直接針對「潛在連續變項」建模,把離散化的影響還原回去。
實務啟示很直接:當你的 EFA 共同性偏低、或冒出一個難以命名的小因素時,先別急著刪題或加因素——先確認你用的是多分相關還是皮爾森相關。換對矩陣,問題往往自己消失。
重點回顧
- 旋轉不確定性是本質而非缺陷:對任意可逆矩陣 $\mathbf{T}$,$\mathbf{\Lambda}\mathbf{T}$ 重建出的相關矩陣相同,所以萃取只定出子空間,轉軸才定座標軸。
- 轉軸靠可解釋性挑解:Varimax(正交)最大化負荷平方的變異數以逼近簡單結構;因素間實際相關偏高時改用斜交(Oblimin / Promax),並分清樣式矩陣與結構矩陣。
- 萃取因素數要用平行分析,別只信特徵值大於 1 或主觀讀陡坡圖。
- 旋轉不改變共同性:它只重新分配負荷,題目被解釋的總變異固定。
- 李克特資料要用多分相關,否則離散化衰減與難度因素會誤導因素結構。
深入探討(研究所視角)
把上面的脈絡推到研究所程度,有三個值得追下去的方向。
第一,從 EFA 到驗證性因素分析(CFA)與 ESEM。 EFA 的旋轉不確定性,本質上是因為它對負荷矩陣不施加任何結構限制。驗證性因素分析(Confirmatory Factor Analysis, CFA)反過來:研究者事先指定哪些題目只負荷哪個因素(其餘固定為 0),這些限制讓模型可被識別(identified)、解唯一,並能用 $\chi^2$、RMSEA、CFI 等指標檢定。代價是 CFA 的「零負荷」假設往往太嚴苛——真實題目常有微小的交叉負荷(cross-loading),硬壓成 0 會讓因素相關被高估。探索性結構方程模型(Exploratory Structural Equation Modeling, ESEM)正是折衷:在 SEM 框架內保留 EFA 的轉軸彈性,允許交叉負荷自由估計,同時享有完整的配適檢定與標準誤。對量表發展的研究者,ESEM 已逐漸成為比「先 EFA 再 CFA」更受推薦的流程。
第二,類別資料的估計法。 在多分相關的基礎上做因素分析,通常不用一般最大概似(ML),而改用對角加權最小平方法(diagonally weighted least squares, WLSMV)。它把多分相關矩陣當作被配適的對象,並用其漸近共變異數矩陣(asymptotic covariance matrix)做加權與修正標準誤。值得理解的是,WLSMV 是有限資訊(limited-information)估計——它只用到兩兩邊際的二維列聯表,而非完整的高維反應組型機率。這在維度高時計算可行、且對閾值估計穩健,但代價是不像全資訊 ML 那樣使用所有資訊。這條線也直通項目反應理論(Item Response Theory, IRT):單因素的有序 probit 因素模型,與 IRT 的分級反應模型(graded response model)在數學上等價,因素負荷 $\lambda$ 與 IRT 的鑑別度參數 $a$ 之間有 $a = \lambda/\sqrt{1-\lambda^2}$ 這類確定的換算關係。換句話說,「類別資料的因素分析」與「IRT」是同一座山的兩個登山口。
第三,因素分數的不確定性(factor score indeterminacy)。 即使你選定了負荷與轉軸,要把每個受試者的因素分數算出來,仍然不唯一。常見的迴歸法(Thomson / regression scores)與 Bartlett 法會給出不同的分數,且兩者都無法完美還原潛在因素——因為共同因素模型裡,觀察變項的數目永遠不足以唯一決定因素分數。這在拿因素分數去做後續迴歸或分組時尤其要小心:把帶有不確定性的因素分數當成「真實測得的變項」,會低估標準誤、膨脹顯著性。較嚴謹的做法是用 SEM 把測量模型與結構模型一起估計,讓潛在變項保持潛在,而不是先壓成一個點估計再丟進下一個分析。這也呼應一個更廣的統計素養:降維從來不是免費的——每一步把高維壓成低維,都在用「可解釋性」交換「資訊」與「確定性」,研究者的責任是把這筆交易講清楚。