
從「圖騙」到統計推論:誤導性圖表的形式化剖析
以 lie factor、心理物理冪定律與估計理論,量化視覺編碼如何在不竄改資料下扭曲判斷
從「圖騙」到統計推論:誤導性圖表的形式化剖析
我們常說「一圖勝千言」,但圖表的說服力恰恰是它的危險之處:人眼對長度、面積、角度、色階的知覺並非線性,而視覺編碼(visual encoding)一旦與被表徵的數值之間發生非保距(non-isometric)映射,圖表就會在「不竄改任何一筆資料」的前提下系統性地扭曲讀者的後驗判斷。本文不停留在「Y 軸別截斷」的清單式提醒,而是把視覺化原則放回估計理論與知覺心理物理學的框架中,說明誤導為何可被形式化、可被量化、可被檢定。
視覺編碼的保距性:lie factor 的數學定義
把資料值記為 $v$,圖形元件在畫面上呈現的視覺量(長度、面積、角度等)記為 $g(v)$。理想的「誠實編碼」要求兩者保持比例:對任意兩值 $v_1, v_2$,
$$ \frac{g(v_1)}{g(v_2)} = \frac{v_1}{v_2}. $$
Tufte 的 lie factor 即是對此比例破壞程度的度量:
$$ \text{LF} = \frac{\text{圖形上效果的相對變化}}{\text{資料的相對變化}} = \frac{\big(g(v_2)-g(v_1)\big)/g(v_1)}{\big(v_2-v_1\big)/v_1}. $$
誠實圖表 $\text{LF}=1$;$\text{LF}>1.05$ 視為誇大,$\text{LF}<0.95$ 視為弱化。最經典的破壞來自「以一維資料驅動二維面積」。設用圓盤直徑線性表示數值 $v$,即 $d(v)\propto v$,則面積 $A(v)\propto d^2 \propto v^2$。對 $v_1\to v_2$,面積相對變化為
$$ \frac{A_2-A_1}{A_1} = \left(\frac{v_2}{v_1}\right)^2 - 1, $$
故
$$ \text{LF} = \frac{(v_2/v_1)^2 - 1}{(v_2/v_1) - 1} = \frac{v_2}{v_1} + 1. $$
當 $v_2/v_1 = 2$ 時 $\text{LF}=3$:資料只翻倍,知覺面積卻像翻了三倍。這正是「面積比例謬誤」的閉式來源——它不是主觀印象,而是 $g(v)=cv^2$ 這個非保距映射的必然結果。修正之道是讓面積而非直徑正比於數值,即 $d\propto\sqrt{v}$。
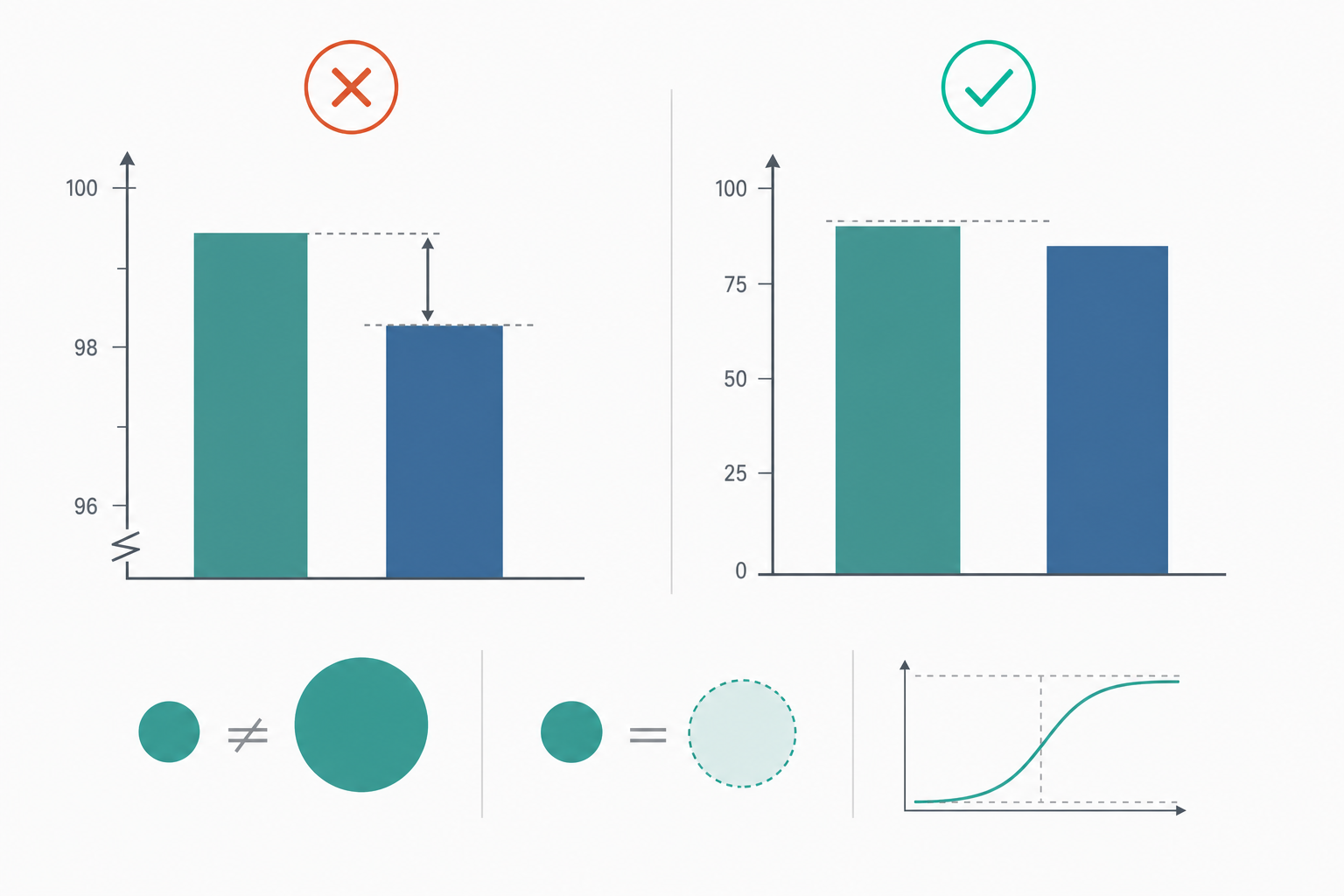
Y 軸截斷:把比例尺度偷換成區間尺度
長條圖以「長度自零起算」編碼數值,其知覺語意預設了比例尺度(ratio scale)——零點有意義、可談倍數。一旦把基線設為 $b>0$,畫面長度變成 $g(v)=v-b$,於是
$$ \frac{g(v_2)}{g(v_1)} = \frac{v_2-b}{v_1-b}\neq \frac{v_2}{v_1}. $$
對 $v_2>v_1>b$,可證 $\dfrac{v_2-b}{v_1-b}>\dfrac{v_2}{v_1}$,差異被放大。例如 $v_1=100,\;v_2=104$ 本只差 4%,若取 $b=98$,畫面長度比變成 $6/2=3$,視覺上像「三倍」。截斷基線等於偷偷把資料從比例尺度降格為區間尺度,卻仍用長度(比例語意)去呈現——量尺與編碼語意不匹配,正是誤導的根。折線圖因不靠「自零起算的長度」編碼絕對量,反而允許截斷以凸顯變異,這說明規則須隨幾何標記的知覺語意而定,不能一刀切。
知覺的冪定律:為什麼面積與色彩特別危險
Stevens 的心理物理冪定律指出,主觀知覺量 $\psi$ 與物理刺激強度 $\phi$ 服從
$$ \psi = k\,\phi^{\alpha}, $$
指數 $\alpha$ 隨知覺通道而異:長度 $\alpha\approx 1$(近線性,故最可靠)、面積 $\alpha\approx 0.7$、亮度 $\alpha\approx 0.33$。把這代入編碼分析:即使我們「正確」讓面積正比於數值($A\propto v$),讀者感知到的卻是 $\psi\propto A^{0.7}\propto v^{0.7}$,大值被系統性低估。Cleveland 與 McGill 的圖形知覺實驗據此把編碼依準確度排序:位置 > 長度 > 角度/斜率 > 面積 > 體積 > 色彩飽和度。誤導性圖表的常見手法,正是刻意選用 $\alpha$ 遠離 1、且讀者難以校準的低階通道(3D 立體柱、氣泡、漸層色階),讓「主觀印象」與「客觀數值」之間插入一道難以察覺的冪次扭曲。
定量小範例:一張被三重操弄的長條圖
某公司宣稱「營收暴增」,用立體圓柱的「高度」表示兩年營收 $v_1=120$、$v_2=132$(單位:百萬),且基線設於 $b=110$。
步驟一(真實相對變化):$\dfrac{v_2-v_1}{v_1}=\dfrac{12}{120}=10\%$。
步驟二(截斷基線造成的長度誇大):畫面高度 $g(v)=v-b$,故 $$ \frac{g(v_2)}{g(v_1)}=\frac{132-110}{120-110}=\frac{22}{10}=2.2, $$ 讀者由「高度」讀到的相對變化為 $2.2-1=120\%$。此步 lie factor 為 $\dfrac{1.20}{0.10}=12$。
步驟三(立體圓柱的面積冪次再加碼):若 3D 圓柱讓視覺量近似正比於高度平方(投影面積),知覺效果再經 $\psi\propto g^{0.7\times 2}=g^{1.4}$。以截斷後高度比 $2.2$ 計,知覺比約 $2.2^{1.4}\approx 3.0$,即「像漲了 200%」。
最終讀者腦中的 $\approx 200\%$ 對上真實的 $10\%$,總 lie factor $\approx 20$。三重操弄——截斷、降維、立體——各自貢獻一個乘法因子,正是「不改數據卻能撒謊」的定量解剖。
別把視覺差異當統計差異:估計不確定性的缺席
最隱微的誤導不是放大,而是把抽樣變異藏起來。設兩組樣本均值 $\bar{X}_1,\bar{X}_2$,其差的標準誤為
$$ \mathrm{SE}(\bar{X}_1-\bar{X}_2)=\sqrt{\frac{s_1^2}{n_1}+\frac{s_2^2}{n_2}}. $$
一張只畫兩根光禿長條、不畫誤差棒或信賴區間的圖,等於宣告 $\mathrm{SE}=0$。讀者把「畫面上的高度差」直接讀成「母體的真實差」,卻不知該差可能落在 $(\bar{X}_1-\bar{X}_2)\pm t_{\alpha/2}\,\mathrm{SE}$ 的區間裡、甚至跨過零。視覺顯著(visually salient)不等於統計顯著(statistically significant);負責任的圖表必須讓不確定性與點估計同框呈現。同理,相關散佈圖上一條陡峭的迴歸線只刻畫 $\widehat{\beta}$ 的方向,絕不能被讀成因果效應——除非設計上排除了混淆,否則 $\widehat{\beta}$ 估的是條件期望的斜率,不是 $\partial \mathbb{E}[Y\mid \mathrm{do}(X)]/\partial x$。
深入探討(研究所視角)
把「誠實視覺化」形式化為估計問題,可看出更深的結構。視覺化本質是一個從資料到視覺刺激的映射 $T:\,v\mapsto g$,理想性質是保序且保距;而誤導圖表對應到 $T$ 的某種已知扭曲。若把讀者建模為一個從刺激回推數值的估計器 $\hat{v}=T^{-1}_{\text{perceived}}(\psi)$,Stevens 冪定律意味著讀者實際使用的反函數是 $\hat v \propto \psi^{1/\alpha}$,於是即便編碼無偏,知覺估計量仍帶有乘法偏誤 $\mathbb{E}[\hat v]\neq v$。良好的色階設計(如感知均勻的 CIELAB 或 viridis)正是在做一件統計的事:讓 $\Delta\psi$ 對 $\Delta v$ 近似常數,即把 Jacobian $\partial \psi/\partial v$ 拉平,等價於方差穩定變換(variance-stabilizing transformation)——同樣的數學也出現在 $\sqrt{\cdot}$ 對 Poisson、$\arcsin\sqrt{\cdot}$ 對二項的處理裡。
從估計量漸近性質看,圖上呈現的任何彙總統計都帶有抽樣分佈。以核密度估計(KDE)繪製分佈為例,估計量 $\hat f_h(x)=\frac{1}{nh}\sum_i K\!\big(\frac{x-X_i}{h}\big)$ 的偏誤與變異呈現經典 bias–variance 拉鋸:
$$ \mathrm{Bias}\approx \tfrac12 h^2 f''(x)\!\int u^2K(u)\,du,\qquad \mathrm{Var}\approx \frac{f(x)}{nh}\!\int K^2(u)\,du. $$
帶寬 $h$ 過小則曲線過度起伏(讀者誤以為有多峰結構),過大則抹平真實眾數。最小化均方積分誤差得 $h^\star\propto n^{-1/5}$,使收斂率為 $O(n^{-4/5})$,慢於參數估計的 $O(n^{-1})$——這提醒我們:直方圖與密度圖的「形狀」本身是一個有不確定性的估計物,bin 寬或帶寬的選擇即是一種編碼決策,可被濫用為視覺操弄。
最大概似與貝氏對應提供互補視角。若以分組直方圖近似概似,等距 bin 對應對母體密度的非參數 MLE 的階梯近似;改變 bin 起點與寬度,等於改變概似的粗粒化,因而可在不更動資料下挪移視覺眾數(著名的 Simpson 式分組悖論在連續情境的翻版)。貝氏框架下,密度的後驗(如 Dirichlet process mixture)會把帶寬不確定性整合進後驗信用帶(credible band),這正是「在圖上把估計不確定性視覺化」的原理性作法——可信區間帶取代了單一光滑曲線,讓讀者看見的是後驗分佈而非點估計。
最後是因果與機器學習的接口。Simpson 悖論在圖上表現為「分層斜率」與「合併斜率」反號:$\mathbb{E}[Y\mid X]$ 的邊際關聯與 $\mathbb{E}[Y\mid X,Z]$ 的條件關聯方向相反,視覺上即一條向上的合併趨勢線掩蓋了各組向下的趨勢。是否「該分層、該畫哪條線」並非美學問題,而需由因果圖(DAG)的後門準則決定——把 $Z$ 視為混淆而調整,或視為對撞子(collider)而避免調整,會給出截然不同卻同樣「不假」的圖。當代以 SHAP、部分依賴圖(PDP)解釋模型時也面臨相同陷阱:PDP 在特徵相關時會外推到資料稀疏區,畫出母體中根本不存在的「效果曲線」。可見從 Tufte 的 lie factor、Cleveland 的圖形知覺,到非參數估計的漸近率與因果識別,誤導性圖表的識別最終匯流為同一個統計命題:任何圖都是一個帶有偏誤與變異的估計量,唯有讓編碼保距、讓不確定性現形、讓因果結構明示,視覺化才稱得上是誠實的推論。