
邏輯斯迴歸與分類:從對數勝算到最大概似的嚴謹推導
深入 sigmoid 連結、score 方程式、MLE 漸近性質與分類決策,並延伸到貝氏正則化與因果推論
從線性到對數機率:為何分類需要邏輯斯迴歸
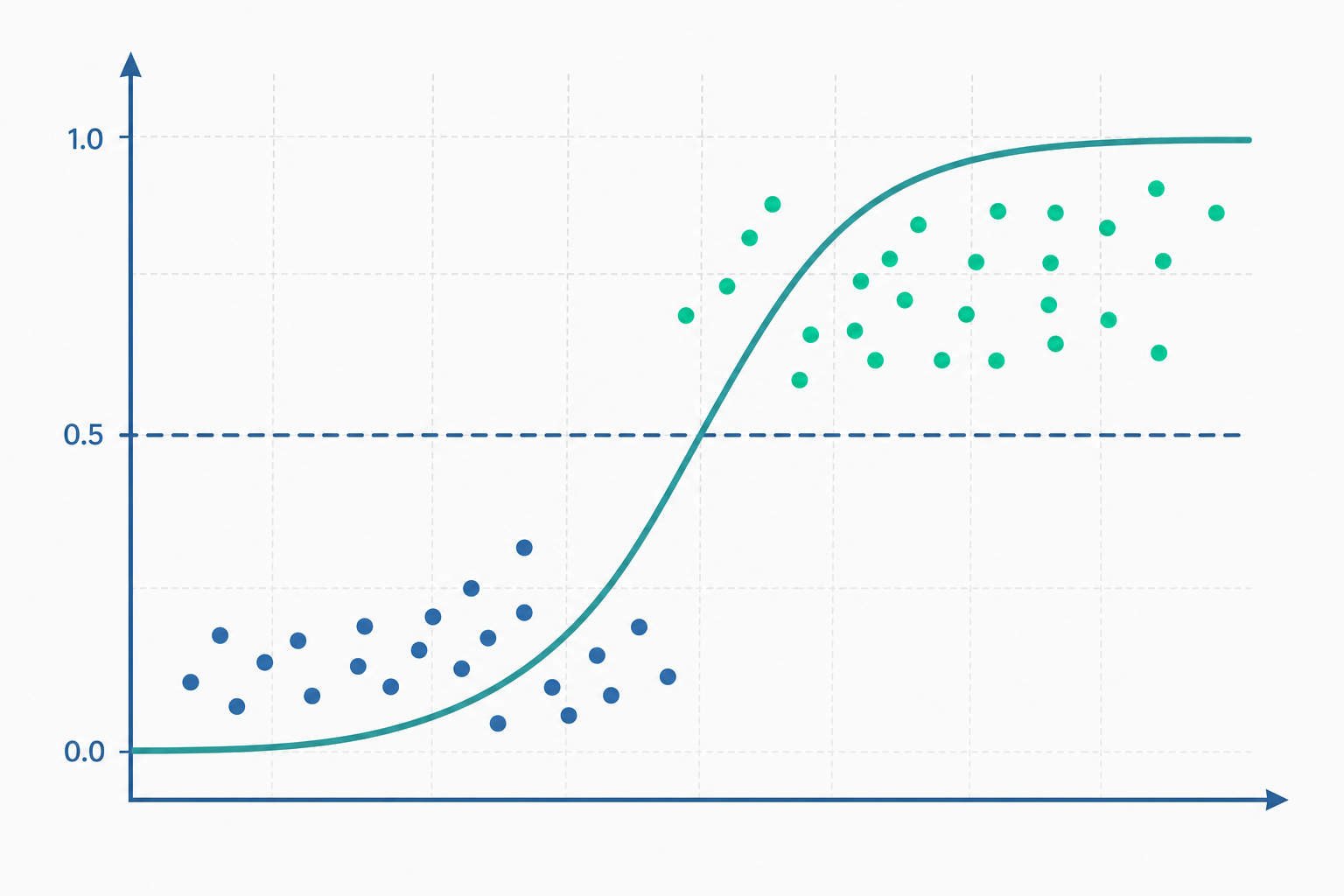
當反應變數 $Y$ 只取 $0$ 與 $1$ 兩個值時,若仍套用普通最小平方迴歸 $Y = \beta_0 + \beta_1 x + \varepsilon$,會立刻撞上三道牆:預測值可能落在 $[0,1]$ 之外、誤差項無法滿足同質變異、且條件分配本質上是伯努利而非常態。邏輯斯迴歸(logistic regression)的核心轉折,是不去模型化 $Y$ 本身,而是模型化「給定 $x$ 之下 $Y=1$ 的條件機率」$\pi(x) = P(Y=1 \mid x)$,並透過一個有界的連結函數把線性預測子映射到 $(0,1)$。
我們設定
$$\pi(x) = \frac{1}{1+e^{-(\beta_0 + \beta_1 x)}} = \frac{e^{\beta_0+\beta_1 x}}{1+e^{\beta_0+\beta_1 x}}.$$
這個 S 形(sigmoid)函數保證機率落在合法區間。將其反解,可得到邏輯斯迴歸的靈魂——對數勝算(log-odds, logit):
$$\operatorname{logit}\bigl(\pi(x)\bigr) = \ln\frac{\pi(x)}{1-\pi(x)} = \beta_0 + \beta_1 x.$$
也就是說,模型對「對數勝算」是線性的。$\beta_1$ 的意義隨之明確:$x$ 每增加一單位,對數勝算改變 $\beta_1$,勝算(odds)則乘以 $e^{\beta_1}$。$e^{\beta_1}$ 正是著名的勝算比(odds ratio),這是邏輯斯迴歸在流行病學與社會科學被廣泛採用的關鍵。
最大概似估計:為何不用最小平方
由於 $Y_i \mid x_i \sim \text{Bernoulli}(\pi_i)$,其機率質量函數可寫成緊緻形式 $P(y_i) = \pi_i^{y_i}(1-\pi_i)^{1-y_i}$。假設觀測獨立,概似函數為
$$L(\boldsymbol\beta) = \prod_{i=1}^{n} \pi_i^{y_i}(1-\pi_i)^{1-y_i},$$
取對數得對數概似(log-likelihood):
$$\ell(\boldsymbol\beta) = \sum_{i=1}^{n}\Bigl[\, y_i \ln \pi_i + (1-y_i)\ln(1-\pi_i)\,\Bigr].$$
代入 $\ln\frac{\pi_i}{1-\pi_i}=\mathbf{x}_i^\top\boldsymbol\beta$ 與 $\ln(1-\pi_i) = -\ln(1+e^{\mathbf{x}_i^\top\boldsymbol\beta})$,可化簡為
$$\ell(\boldsymbol\beta) = \sum_{i=1}^{n}\Bigl[\, y_i\,\mathbf{x}_i^\top\boldsymbol\beta - \ln\bigl(1+e^{\mathbf{x}_i^\top\boldsymbol\beta}\bigr)\Bigr].$$
對 $\boldsymbol\beta$ 求梯度,利用 $\frac{\partial \pi_i}{\partial \boldsymbol\beta}=\pi_i(1-\pi_i)\mathbf{x}_i$,得到優雅的分數方程式(score equation):
$$\frac{\partial \ell}{\partial \boldsymbol\beta} = \sum_{i=1}^{n}\bigl(y_i - \pi_i\bigr)\mathbf{x}_i = \mathbf{0}.$$
這組方程式對 $\boldsymbol\beta$ 是非線性的,沒有閉合解,必須用數值法迭代求解。實務上以 Newton–Raphson(等價於 iteratively reweighted least squares, IRLS)逼近。其更新式為
$$\boldsymbol\beta^{(t+1)} = \boldsymbol\beta^{(t)} + \bigl(\mathbf{X}^\top \mathbf{W}\mathbf{X}\bigr)^{-1}\mathbf{X}^\top(\mathbf{y}-\boldsymbol\pi),$$
其中 $\mathbf{W}=\operatorname{diag}\bigl(\pi_i(1-\pi_i)\bigr)$。值得一提的是,$\ell(\boldsymbol\beta)$ 是凹函數(其 Hessian $-\mathbf{X}^\top\mathbf{W}\mathbf{X}$ 為負半定),因此只要解存在便是全域最大,這是邏輯斯迴歸數值穩定的理論保證。
定量小範例:手算一步迭代直覺
設只有截距、無解釋變數的最簡模型,觀測為 $n=10$ 名學生是否通過某測驗,其中 $7$ 人通過($\sum y_i = 7$)。模型 $\operatorname{logit}(\pi)=\beta_0$,則 $\hat\pi$ 為樣本通過比例。
由分數方程式 $\sum (y_i - \pi)=0$,得 $\hat\pi = \bar y = 0.7$。對應的截距估計:
$$\hat\beta_0 = \ln\frac{0.7}{0.3} = \ln(2.333\ldots) \approx 0.847.$$
勝算比 $e^{\hat\beta_0}\approx 2.33$,意即通過的勝算約為不通過的 $2.33$ 倍。再算估計的標準誤:此模型 Fisher 資訊為 $I(\beta_0)=n\,\pi(1-\pi)=10\times0.7\times0.3=2.1$,故
$$\widehat{\operatorname{SE}}(\hat\beta_0) = \frac{1}{\sqrt{I}} = \frac{1}{\sqrt{2.1}}\approx 0.690.$$
$95\%$ Wald 信賴區間為 $0.847 \pm 1.96\times0.690 = (-0.505,\ 2.199)$。注意此區間包含 $0$,代表在此小樣本下無法宣稱通過率顯著異於 $0.5$。將端點轉回機率尺度 $\frac{1}{1+e^{-\cdot}}$,得 $\pi$ 的區間約 $(0.376,\ 0.900)$——這正確示範了:信賴區間要在線性預測子尺度建構、再轉換,而非直接對 $\hat\pi$ 加減,否則可能越界。
從機率到決策:分類的門檻與評估
模型輸出的是機率 $\hat\pi(x)$,要轉成類別預測需設定門檻 $c$:$\hat\pi(x) > c$ 則判為 $1$。預設 $c=0.5$ 對應「貝氏最適決策」僅在誤分類成本對稱、且兩類先驗相等時成立;當類別不平衡或偽陰性代價高昂時,應調整 $c$。
評估分類器不能只看準確率(accuracy),因為在 $95\%$ 為負例的資料上,全猜負例就有 $95\%$ 準確率卻毫無價值。更穩健的工具是 ROC 曲線與其下面積 AUC,它衡量的是「隨機抽一正一負樣本,模型給正樣本較高分」的機率,與門檻無關。搭配精確率(precision)、召回率(recall)與 $F_1$ 才能完整刻畫。統計素養提醒:$\beta_1$ 顯著只代表「在控制其他變數下,$x$ 與對數勝算有統計關聯」,絕不等於 $x$ 「導致」$Y$;觀察性資料中的勝算比仍受混淆變數威脅,相關不蘊含因果。
深入探討(研究所視角)
最大概似估計量的漸近性質是推論的理論基石。在正則條件下,$\hat{\boldsymbol\beta}_{MLE}$ 具有一致性、漸近常態與漸近有效性:
$$\sqrt{n}\,(\hat{\boldsymbol\beta} - \boldsymbol\beta) \xrightarrow{d} \mathcal{N}\bigl(\mathbf{0},\ \mathcal{I}(\boldsymbol\beta)^{-1}\bigr),$$
其中 $\mathcal{I}(\boldsymbol\beta)=\mathbb{E}\bigl[-\partial^2\ell/\partial\boldsymbol\beta\partial\boldsymbol\beta^\top\bigr]=\mathbf{X}^\top\mathbf{W}\mathbf{X}/n$(單位資訊)。其變異數下界達到 Cramér–Rao 界,這正是 Wald 檢定與信賴區間的根據。然而漸近性質在小樣本或完全分離(complete separation)時失效——當某線性組合能完美區分兩類時,MLE 會發散至無窮($\hat\beta\to\pm\infty$),此時 Firth 的懲罰概似(penalized likelihood,對 Jeffreys 先驗加權)可給出有限估計,是研究所必知的補救法。
除了 Wald 檢定,概似比檢定(LRT)通常更可靠:$-2\ln(L_0/L_1) \xrightarrow{d} \chi^2_q$,在虛無假設下漸近服從卡方分配,對小樣本與分離問題的行為優於 Wald。三大檢定(Wald、LRT、score/Lagrange multiplier)漸近等價,但有限樣本表現不同。
貝氏對應為同一模型提供另一視角。對 $\boldsymbol\beta$ 設先驗 $p(\boldsymbol\beta)$(如弱資訊的 $\mathcal{N}(0,\tau^2)$ 或 Gelman 提倡的 Cauchy 先驗),則後驗 $p(\boldsymbol\beta\mid \mathbf{y})\propto L(\boldsymbol\beta)\,p(\boldsymbol\beta)$ 無共軛閉式,須以 MCMC(如 Hamiltonian Monte Carlo)或變分推論逼近。有趣的是,頻率派的 L2 正則化(ridge logistic)等價於高斯先驗的最大後驗(MAP)估計,L1(lasso)則對應 Laplace 先驗——這座橋樑把懲罰估計與貝氏正則化統一起來,也說明了為何正則化能緩解完全分離。
與機器學習的連結:邏輯斯迴歸的對數概似損失,正是分類中的「交叉熵損失(cross-entropy)」;單層神經網路配 sigmoid 輸出與交叉熵,本質就是邏輯斯迴歸。它也是廣義線性模型(GLM)中以 logit 為典範連結(canonical link)的伯努利成員,可推廣到多類別的 softmax 迴歸。從機率校準角度,邏輯斯迴歸常作為其他分類器分數的事後校準器(Platt scaling)。
因果推論的橋接:勝算比常被誤當成風險比或因果效應。在傾向分數(propensity score)框架中,邏輯斯迴歸用來估計處置機率 $e(x)=P(T=1\mid x)$,再透過配對、加權(IPW)或雙重穩健估計逼近平均處置效應(ATE)。但須警惕——勝算比的不可塌縮性(non-collapsibility)意味著邊際與條件勝算比即使無混淆也可能不等,這與線性模型的可塌縮性截然不同,是高階使用者最易踩的雷。