
測量的信度與效度:從真分數模型到衰減校正
用古典測驗理論與潛在變數模型,嚴謹推導信度係數、Cronbach's α 與效度的數學結構
從「真分數」談起:測量為何需要被測量
任何一次測驗、問卷或生理量測,得到的觀測值都不是赤裸的真相。直覺上我們知道「同一個人量兩次體重會略有不同」,這個直覺正是整套測量理論的起點。信度(reliability)回答的是「重複測量有多一致」,效度(validity)回答的是「我們量到的,是不是我們想量的」。前者談精準(precision),後者談準確(accuracy)。一支瞄歪了的槍可以彈著點很集中(高信度、低效度);一把校準良好但手抖的尺可以平均無偏卻散布很大(高效度、低信度)。本文從古典測驗理論(Classical Test Theory, CTT)的真分數模型出發,嚴謹推導信度係數的數學結構,再延伸到效度的相關衰減校正,最後進入研究所視角的潛在變數與漸近理論。
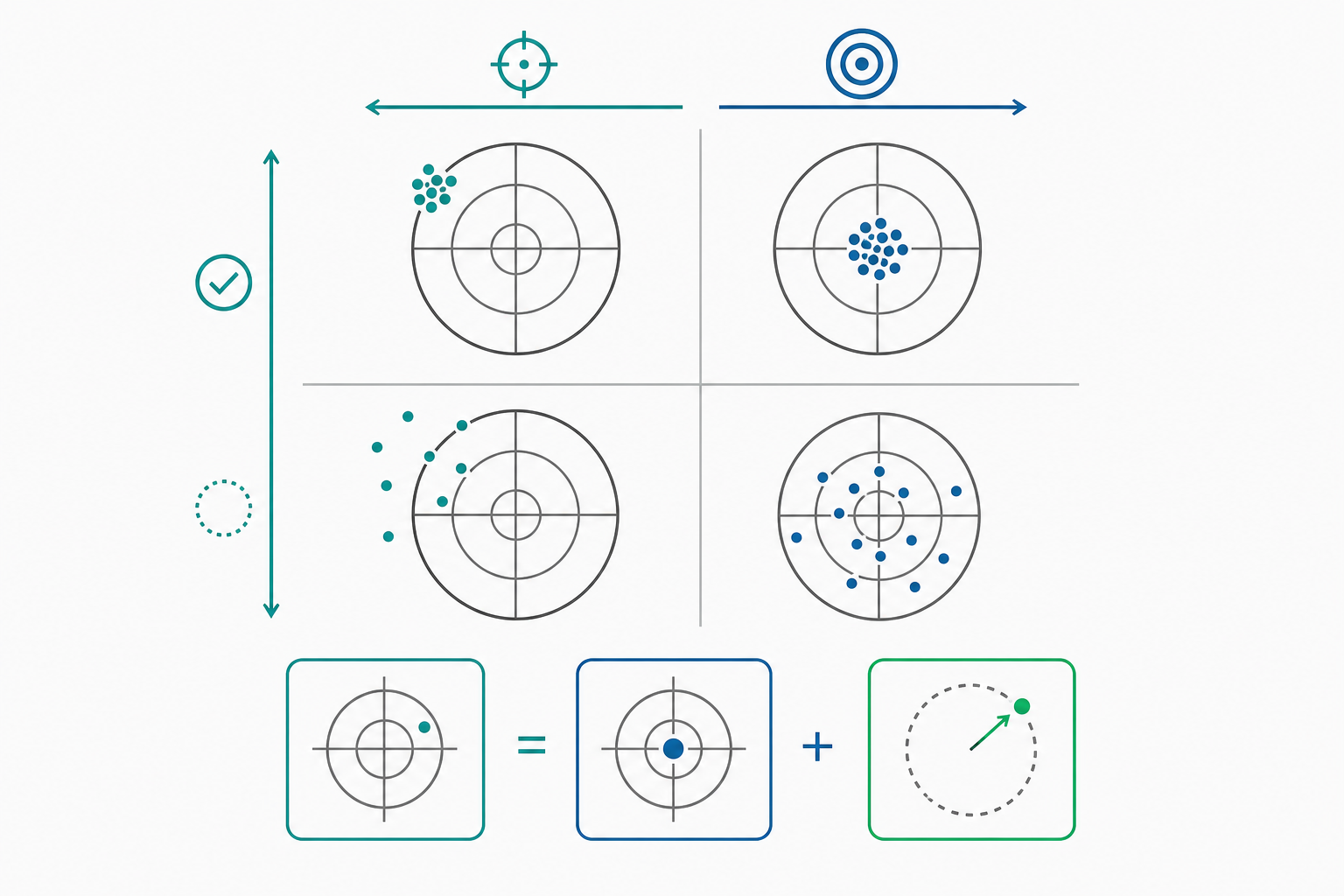
真分數模型與信度的定義
古典測驗理論把觀測分數 $X$ 拆解為真分數 $T$ 與誤差 $E$:
$$X = T + E.$$
模型的核心假設是:誤差的期望為零 $\mathbb{E}[E]=0$(故 $\mathbb{E}[X]=T$ 在個體層次成立,$T$ 定義為 $X$ 在無限次平行測量下的期望值),且誤差與真分數不相關 $\mathrm{Cov}(T,E)=0$,不同測量的誤差彼此不相關 $\mathrm{Cov}(E_1,E_2)=0$。由變異數的可加性:
$$\sigma_X^2 = \sigma_T^2 + \sigma_E^2.$$
信度 $\rho_{XX'}$ 定義為真分數變異佔總變異的比例:
$$\rho_{XX'} = \frac{\sigma_T^2}{\sigma_X^2} = \frac{\sigma_T^2}{\sigma_T^2 + \sigma_E^2}.$$
這個比例為何叫「再測相關」?考慮兩次平行測量 $X = T+E_1$、$X' = T+E_2$,兩者真分數相同、誤差變異相同。它們的共變異為
$$\mathrm{Cov}(X,X') = \mathrm{Cov}(T+E_1,\,T+E_2) = \sigma_T^2,$$
因為 $T$ 與兩誤差皆不相關、兩誤差互不相關。而 $\sigma_X = \sigma_{X'} = \sqrt{\sigma_T^2+\sigma_E^2}$,於是相關係數
$$\mathrm{Corr}(X,X') = \frac{\sigma_T^2}{\sigma_T^2+\sigma_E^2} = \rho_{XX'}.$$
信度因此可被「兩次平行測量的相關」直接估計,這正是 test–retest 與 parallel-form 信度的理論依據。同時可推得 $\mathrm{Corr}(X,T)=\sqrt{\rho_{XX'}}$:信度的平方根即觀測分數與真分數的相關。
內部一致性:從可加性到 Cronbach's α
再測法需要兩次施測,成本高。更常見的是用單次施測中多個題目(item)的內部一致性估計信度。設量表由 $k$ 題組成,總分 $X=\sum_{i=1}^k X_i$。Cronbach's α 為
$$\alpha = \frac{k}{k-1}\left(1 - \frac{\sum_{i=1}^k \sigma_i^2}{\sigma_X^2}\right),$$
其中 $\sigma_i^2$ 是第 $i$ 題的變異數、$\sigma_X^2$ 是總分變異數。其來龍去脈如下:總分變異可展開為
$$\sigma_X^2 = \sum_{i=1}^k \sigma_i^2 + \sum_{i\neq j}\sigma_{ij},$$
對角線是題目自身變異,非對角線是題目間共變異 $\sigma_{ij}$。在「題目本質 τ-等價」(每題的真分數只差一常數)的假設下,題間共變異全來自共同真分數,可證明 α 恰等於信度;當題目僅為同向但不等價時,α 為信度的下界——這是 α 重要的理論性質:它傾向低估而非高估。$k/(k-1)$ 的校正源於 $k$ 題共有 $k(k-1)$ 個非對角項,用以把「平均題間共變」放大回整體尺度。
由此也得到 Spearman–Brown 預言公式:把測驗加長為原來 $m$ 倍,新信度
$$\rho^{*} = \frac{m\,\rho_{XX'}}{1 + (m-1)\,\rho_{XX'}}.$$
加題可提升信度,但邊際遞減:因為加題同時放大 $\sigma_T^2$(以 $m^2$ 的共變項主導)與 $\sigma_E^2$(以 $m$ 的對角項主導),真分數成分增長較快,故信度上升。
效度與衰減校正
效度的證據種類繁多(內容效度、效標關聯效度、建構效度),但其中一個最能展現信度與效度數學連結的,是衰減校正(correction for attenuation)。設我們關心兩個構念真分數 $T_X$、$T_Y$ 的真實相關 $\rho_{T_X T_Y}$,但只能觀測到帶誤差的 $X$、$Y$。可證明觀測相關被信度「稀釋」:
$$\rho_{XY} = \rho_{T_X T_Y}\,\sqrt{\rho_{XX'}}\,\sqrt{\rho_{YY'}}.$$
推導要點:$\mathrm{Cov}(X,Y)=\mathrm{Cov}(T_X,T_Y)=\sigma_{T_X T_Y}$(誤差互不相關),而 $\sigma_X=\sigma_{T_X}/\sqrt{\rho_{XX'}}$,$\sigma_Y$ 同理,代入相關定義即得。反解得到去除測量誤差後的估計:
$$\hat{\rho}_{T_X T_Y} = \frac{\rho_{XY}}{\sqrt{\rho_{XX'}\,\rho_{YY'}}}.$$
這說明:低信度會系統性地壓低你能觀測到的效度上限。一個信度只有 0.5 的工具,再有意義的構念也測不出強相關。
定量小範例
某 5 題自評量表($k=5$),各題變異數為 $1.2,\,1.0,\,1.5,\,0.9,\,1.4$,總分變異數 $\sigma_X^2 = 12.0$。先算 Cronbach's α:
$$\sum \sigma_i^2 = 1.2+1.0+1.5+0.9+1.4 = 6.0.$$
$$\alpha = \frac{5}{5-1}\left(1 - \frac{6.0}{12.0}\right) = 1.25\times(1-0.5) = 1.25\times0.5 = 0.625.$$
信度 $0.625$ 偏低。若用 Spearman–Brown 估計:要把信度提到 $0.80$ 需多長的測驗?解
$$0.80 = \frac{m\times0.625}{1+(m-1)\times0.625}\ \Rightarrow\ 0.80(1+0.625m-0.625)=0.625m,$$
$$0.80(0.375+0.625m)=0.625m\ \Rightarrow\ 0.30+0.50m=0.625m\ \Rightarrow\ m=\frac{0.30}{0.125}=2.4.$$
即需約 $2.4$ 倍長度,約 $12$ 題。再看衰減校正:若此量表($\rho_{XX'}=0.625$)與另一信度 $0.80$ 的效標量表觀測相關 $\rho_{XY}=0.35$,則去誤差後的真相關估計為
$$\hat{\rho}_{T_X T_Y} = \frac{0.35}{\sqrt{0.625\times0.80}} = \frac{0.35}{\sqrt{0.50}} = \frac{0.35}{0.7071} \approx 0.495.$$
觀測到的 $0.35$ 在校正測量誤差後其實接近 $0.50$——這正是低信度遮蔽真實關係的具體後果。
統計素養提醒
衰減校正是「假如沒有測量誤差會如何」的反事實估計,不能直接當成觀測效度回報,且校正值可能因信度估計不準而超過 1,需謹慎。α 高並不保證單一維度(unidimensionality)——它對維度結構不敏感,高 α 可能只是題多;要驗證構念結構應用因素分析。最後,效度本質上是關於分數解釋的論證,不是工具的固有屬性:同一份測驗用於不同母體、不同決策,效度需重新檢驗。信度高不蘊含效度高,別把一致當成正確。
深入探討(研究所視角)
把 CTT 嵌進潛在變數模型後,信度與效度獲得更一般的表述。同向但不等價(congeneric)的測量模型寫成 $X_i = \lambda_i \eta + \varepsilon_i$,其中 $\eta$ 是潛在構念、$\lambda_i$ 是因素負荷。此時 McDonald's $\omega = \frac{(\sum\lambda_i)^2}{(\sum\lambda_i)^2+\sum\theta_i}$($\theta_i$ 為誤差變異)才是正確的信度估計,而 Cronbach's α 僅在 τ-等價(所有 $\lambda_i$ 相等)下與 ω 一致,否則為下界。負荷與誤差變異通常以最大概似估計:在多元常態假設下,最小化觀測共變異矩陣 $S$ 與模型隱含矩陣 $\Sigma(\theta)$ 的差異,目標函數 $F_{ML}=\log|\Sigma(\theta)|+\mathrm{tr}(S\Sigma(\theta)^{-1})-\log|S|-p$。MLE 的漸近性質保證 $\hat\theta$ 一致、漸近常態、達 Cramér–Rao 下界,標準誤可由觀測 Fisher 資訊矩陣 $\mathcal{I}(\hat\theta)$ 的逆對角元開根號取得,使 ω 與校正相關都能附帶信賴區間。當常態假設可疑時,動差法 / 廣義動差法(GMM) 或 ADF(asymptotically distribution-free)加權最小平方提供穩健替代,代價是小樣本效率較差。
項目反應理論(IRT) 進一步把信度從「全量表單一數字」解放為測量精度隨能力而變的函數。在 2PL 模型 $P_i(\theta)=\dfrac{1}{1+e^{-a_i(\theta-b_i)}}$ 中,題目資訊 $I_i(\theta)=a_i^2 P_i(\theta)[1-P_i(\theta)]$,測驗資訊 $I(\theta)=\sum_i I_i(\theta)$,而能力估計的漸近標準誤為 $\mathrm{SE}(\hat\theta)=1/\sqrt{I(\theta)}$。這解釋了為何同一份測驗對中等能力者很可靠、對極端者卻誤差大——信度在 CTT 中被假設為常數,在 IRT 中則是 $\theta$ 的函數。
貝氏對應把參數視為隨機:對 $\lambda,\theta,\eta$ 賦予先驗,透過 MCMC 取得後驗,信度(如 ω)的後驗分布自然給出可信區間,且能納入小樣本與階層結構(如跨班級、跨學校的多層信度分解)。在因果推論脈絡下,測量誤差是回歸係數偏誤的經典來源:自變數含古典誤差會使 OLS 係數向零衰減(regression dilution),衰減因子恰為該變數信度 $\rho_{XX'}$;這與工具變數、SIMEX、errors-in-variables 回歸的校正策略直接相扣。與機器學習的連結則體現在:測量誤差設定 Bayes 誤差的不可化約下界,再強的模型也無法突破被噪音遮蔽的可學習訊號;而 split-half 信度與交叉驗證的折疊穩定性、表徵層的 test–retest 一致性,已成為評估神經影像與行為標記是否可作為個體化預測特徵的前置門檻。信效度因此不只是心理計量學的內務,而是貫穿估計理論、因果識別與可預測性的共同語言。