
多元迴歸與模型診斷:從正規方程式到 BLUE 與假設檢驗
嚴謹推導 OLS 估計量的不偏性與變異數,並系統檢視四大假設、共線性與正確的統計解讀
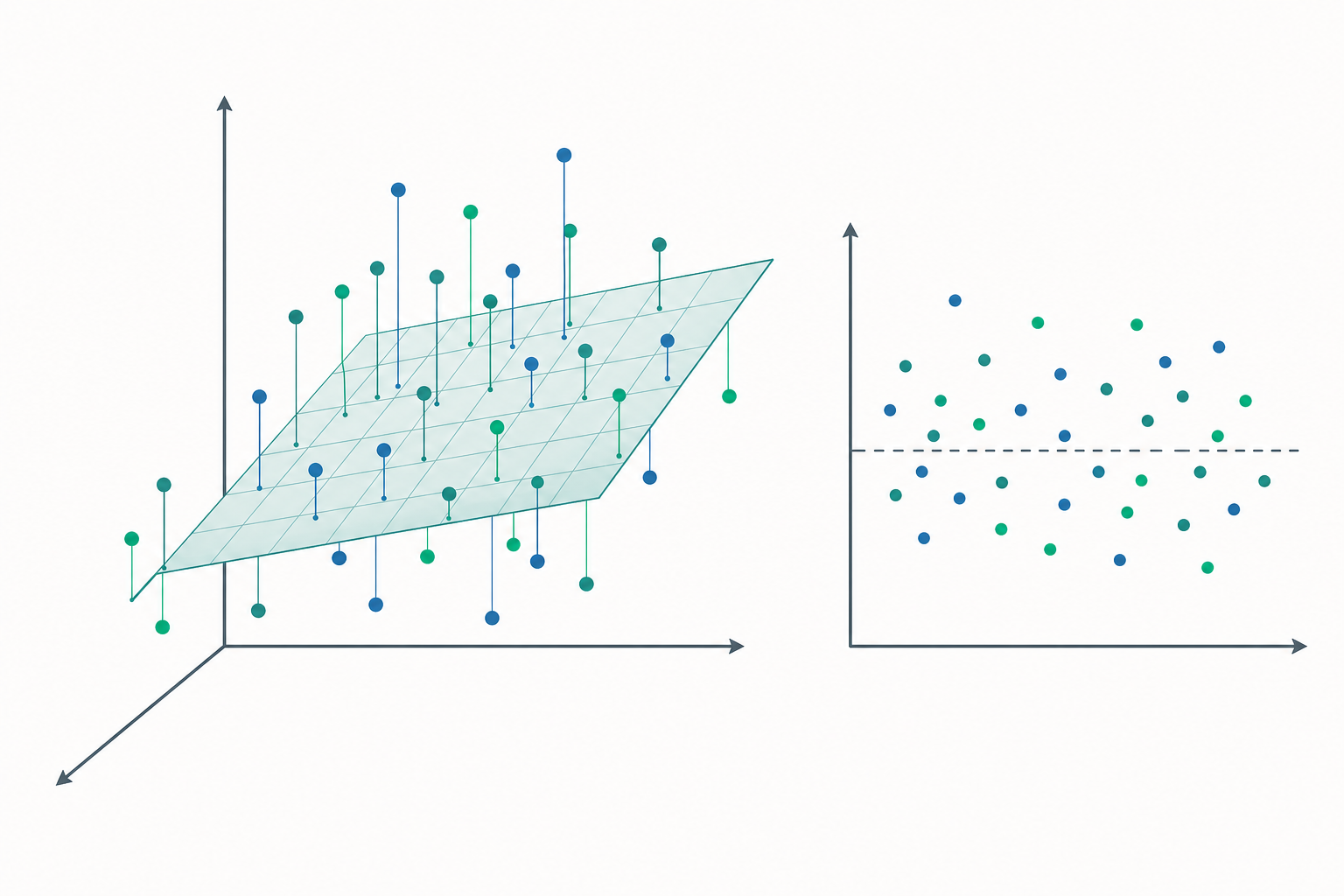
從一條線到一個超平面:多元迴歸在做什麼
當我們同時用學習時數、睡眠品質與課堂出席率預測考試成績時,直覺上是要找出「在控制其他變數後,每個因子各自的貢獻」。多元迴歸正是把這個直覺寫成數學:在 $p$ 維特徵空間中找一個超平面,使得觀測點到此超平面的垂直距離平方和最小。但真正的挑戰不在「擬合」,而在「擬合之後我們憑什麼相信它」——這就是模型診斷的核心。
設樣本量為 $n$、自變數(含截距)為 $k = p+1$ 個,模型寫成矩陣形式:
$$\mathbf{y} = \mathbf{X}\boldsymbol{\beta} + \boldsymbol{\varepsilon},\qquad \boldsymbol{\varepsilon}\sim(\mathbf{0},\,\sigma^2\mathbf{I}_n)$$
其中 $\mathbf{X}$ 是 $n\times k$ 的設計矩陣。最小平方法要最小化 $S(\boldsymbol{\beta}) = (\mathbf{y}-\mathbf{X}\boldsymbol{\beta})^\top(\mathbf{y}-\mathbf{X}\boldsymbol{\beta})$。
OLS 估計量的推導與性質
對 $S(\boldsymbol{\beta})$ 求梯度並令其為零:
$$\frac{\partial S}{\partial \boldsymbol{\beta}} = -2\mathbf{X}^\top(\mathbf{y}-\mathbf{X}\boldsymbol{\beta}) = \mathbf{0}\;\Longrightarrow\; \mathbf{X}^\top\mathbf{X}\,\hat{\boldsymbol{\beta}} = \mathbf{X}^\top\mathbf{y}$$
這組「正規方程式」(normal equations)在 $\mathbf{X}^\top\mathbf{X}$ 可逆(即 $\mathbf{X}$ 滿秩、無完全共線性)時有唯一解:
$$\hat{\boldsymbol{\beta}} = (\mathbf{X}^\top\mathbf{X})^{-1}\mathbf{X}^\top\mathbf{y}$$
由於 $\hat{\boldsymbol{\beta}}$ 是 $\mathbf{y}$ 的線性函數,其期望值與變異數可直接運算。代入 $\mathbf{y}=\mathbf{X}\boldsymbol{\beta}+\boldsymbol{\varepsilon}$:
$$E[\hat{\boldsymbol{\beta}}] = (\mathbf{X}^\top\mathbf{X})^{-1}\mathbf{X}^\top E[\mathbf{X}\boldsymbol{\beta}+\boldsymbol{\varepsilon}] = \boldsymbol{\beta}$$
故 OLS 為不偏估計量。變異數則為:
$$\operatorname{Var}(\hat{\boldsymbol{\beta}}) = (\mathbf{X}^\top\mathbf{X})^{-1}\mathbf{X}^\top\,\sigma^2\mathbf{I}\,\mathbf{X}(\mathbf{X}^\top\mathbf{X})^{-1} = \sigma^2(\mathbf{X}^\top\mathbf{X})^{-1}$$
高斯—馬可夫定理進一步保證:在誤差零均值、同質變異、互不相關的假設下,OLS 是所有線性不偏估計量中變異數最小者(BLUE),這個結論不需要常態假設。常態假設只在做精確的 $t$ 檢定與 $F$ 檢定時才必要。
殘差向量 $\hat{\boldsymbol{\varepsilon}} = \mathbf{y}-\mathbf{X}\hat{\boldsymbol{\beta}} = (\mathbf{I}-\mathbf{H})\mathbf{y}$,其中 $\mathbf{H} = \mathbf{X}(\mathbf{X}^\top\mathbf{X})^{-1}\mathbf{X}^\top$ 是把 $\mathbf{y}$ 投影到 $\mathbf{X}$ 行空間的帽子矩陣(hat matrix),滿足 $\mathbf{H}^2=\mathbf{H}$、$\mathbf{H}^\top=\mathbf{H}$。對角元 $h_{ii}$ 稱為槓桿值(leverage),度量第 $i$ 個觀測在預測自身上的影響力,且 $\sum_i h_{ii} = \operatorname{tr}(\mathbf{H}) = k$。誤差變異數的不偏估計為 $\hat{\sigma}^2 = \hat{\boldsymbol{\varepsilon}}^\top\hat{\boldsymbol{\varepsilon}}/(n-k)$,分母的自由度損失正是因為估計了 $k$ 個係數。
為什麼要做診斷:四大假設與其後果
OLS 的良好性質建立在四個假設上,每個違反都有對應的診斷與後果:
- 線性與正確設定:若真實關係非線性卻硬套線性,估計係數本身就有偏誤。以殘差對配適值散佈圖檢查,若出現曲線型態即為警訊。
- 同質變異(homoscedasticity):若 $\operatorname{Var}(\varepsilon_i)=\sigma_i^2$ 隨觀測變動,係數仍不偏,但標準誤被低估,導致 $t$、$F$ 檢定失真。可用 Breusch–Pagan 或 White 檢定,並改用穩健標準誤(heteroscedasticity-consistent,HC)。
- 誤差獨立:時間序列資料常見自相關,Durbin–Watson 統計量可偵測一階自相關。
- 無嚴重多重共線性:當自變數高度相關,$\mathbf{X}^\top\mathbf{X}$ 接近奇異,$(\mathbf{X}^\top\mathbf{X})^{-1}$ 的對角元爆增,係數變異數膨脹。常用變異數膨脹因子(VIF):
$$\text{VIF}_j = \frac{1}{1-R_j^2}$$
其中 $R_j^2$ 是把第 $j$ 個自變數對其餘自變數迴歸所得的判定係數。VIF 超過 5 或 10 通常視為共線性需要處理。
定量小範例:手算一個二元迴歸
設 5 筆資料,預測變數 $x$ 與反應變數 $y$(為簡化僅用單一斜率加截距,矩陣機制相同):
| $x$ | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| $y$ | 2 | 4 | 5 | 4 | 7 |
計算:$\bar{x}=3$、$\bar{y}=4.4$。離差乘積和
$$S_{xy}=\sum(x_i-\bar{x})(y_i-\bar{y}) = (-2)(-2.4)+(-1)(-0.4)+0+1(-0.4)+2(2.6)=10$$
$$S_{xx}=\sum(x_i-\bar{x})^2 = 4+1+0+1+4 = 10$$
故 $\hat{\beta}_1 = S_{xy}/S_{xx} = 10/10 = 1.0$,$\hat{\beta}_0 = \bar{y}-\hat{\beta}_1\bar{x} = 4.4-3 = 1.4$。配適值與殘差:
| $\hat{y}_i$ | 2.4 | 3.4 | 4.4 | 5.4 | 6.4 |
|---|---|---|---|---|---|
| $\hat{\varepsilon}_i$ | -0.4 | 0.6 | 0.6 | -1.4 | 0.6 |
殘差平方和 $\text{SSE}=0.16+0.36+0.36+1.96+0.36=3.2$,$\hat{\sigma}^2 = 3.2/(5-2)\approx 1.067$,斜率標準誤 $\widehat{\text{SE}}(\hat{\beta}_1)=\sqrt{\hat{\sigma}^2/S_{xx}}=\sqrt{0.1067}\approx 0.327$。檢定統計量 $t = 1.0/0.327\approx 3.06$,自由度 3,雙尾 $p\approx 0.055$——注意:即使點估計看似明確,樣本太小時仍未達 $\alpha=0.05$ 的常規門檻,這正提醒我們別把估計值的大小與證據的強度混為一談。
正確解讀:別把係數讀成因果
多元迴歸係數的標準詮釋是「在統計上控制其他納入變數後,該變數每變動一單位、反應變數的平均變化」。這有兩個常被誤用之處:其一,只控制了模型中的變數,遺漏變數(omitted variable)仍可能造成偏誤,故迴歸係數不等於因果效應;其二,$p$ 值衡量的是「若虛無假設為真、觀測到如此或更極端結果的機率」,並非「係數為零的機率」,也非效果大小。信賴區間同理:95% 信賴區間指的是該程序在重複抽樣下有 95% 機率涵蓋真值,而非「真值有 95% 機率落在此區間」。具備統計素養,意味著同時報告效果量、不確定性與診斷結果,而非只盯著星號。
深入探討(研究所視角)
當樣本量增大,OLS 的合理性可從更一般的框架理解。放寬常態假設後,只要誤差具有限二階動差且 $\frac{1}{n}\mathbf{X}^\top\mathbf{X}\to\mathbf{Q}$(正定),由 Lindeberg–Feller 中央極限定理可證 $\sqrt{n}(\hat{\boldsymbol{\beta}}-\boldsymbol{\beta})\xrightarrow{d}\mathcal{N}(\mathbf{0},\,\sigma^2\mathbf{Q}^{-1})$。這說明 $t$、$F$ 檢定即使在非常態下也漸近有效,是大樣本實務廣泛使用線性模型的理論基礎。OLS 本身也可視為以「矩條件」$E[\mathbf{x}_i\varepsilon_i]=\mathbf{0}$ 為基礎的動差法(method of moments)特例,將其推廣即得廣義動差法(GMM),在計量經濟學處理內生性與工具變數時居於核心地位。
從概似觀點看,若進一步假設 $\boldsymbol{\varepsilon}\sim\mathcal{N}(\mathbf{0},\sigma^2\mathbf{I})$,對數概似函數
$$\ell(\boldsymbol{\beta},\sigma^2) = -\frac{n}{2}\ln(2\pi\sigma^2) - \frac{1}{2\sigma^2}(\mathbf{y}-\mathbf{X}\boldsymbol{\beta})^\top(\mathbf{y}-\mathbf{X}\boldsymbol{\beta})$$
對 $\boldsymbol{\beta}$ 最大化,等價於最小化平方和——故在常態假設下 MLE 與 OLS 重合。MLE 的 Fisher 訊息矩陣為 $\mathcal{I}(\boldsymbol{\beta})=\mathbf{X}^\top\mathbf{X}/\sigma^2$,其逆恰為 $\operatorname{Var}(\hat{\boldsymbol{\beta}})$,達到 Cramér–Rao 下界,顯示 OLS 在常態下也是有效估計量。
貝氏對應提供另一層洞見:若給定共軛先驗 $\boldsymbol{\beta}\sim\mathcal{N}(\mathbf{0},\tau^2\mathbf{I})$,後驗眾數為
$$\hat{\boldsymbol{\beta}}_{\text{ridge}} = (\mathbf{X}^\top\mathbf{X}+\lambda\mathbf{I})^{-1}\mathbf{X}^\top\mathbf{y},\qquad \lambda=\sigma^2/\tau^2$$
這正是嶺迴歸(ridge regression)。換言之,正則化等價於施加先驗信念;$\lambda\mathbf{I}$ 改善了 $\mathbf{X}^\top\mathbf{X}$ 的條件數,以引入微小偏誤換取大幅降低變異數,直接呼應前述共線性問題。類似地,Laplace 先驗對應 LASSO,產生稀疏解。這條線索把古典迴歸接上現代機器學習的偏誤—變異數權衡:OLS 是 $\lambda=0$ 的無偏端點,而預測導向的建模往往刻意接受偏誤以最小化期望預測誤差。
最後,在因果推論框架下,迴歸係數要被解讀為因果效應,需滿足可忽略性(unconfoundedness)等識別假設;潛在結果模型(Rubin causal model)與有向無環圖(DAG)提供了判斷哪些變數該納入、哪些是不可控制的對撞因子(collider)的原則。盲目把所有變數丟進迴歸並非「控制」,反而可能因控制對撞因子而引入偏誤——這是診斷之外、研究設計層次的素養要求。