
時間序列分析:自相關、定態與 ARIMA 入門
從成分分解到 Box–Jenkins 流程,理解為何時間相依的資料不能用一般迴歸,以及如何用 ARIMA 建模股市與環境時序
為什麼昨天的股價,藏著今天的祕密?
打開 Uedu Finance 的台積電日線圖,你會發現一件直覺但深刻的事:今天的收盤價,幾乎總是離昨天的收盤價不遠。氣溫也是如此——若你看 Uedu Environomics 蒐集的校園溫度時序,今天下午三點的溫度,和昨天同一時刻高度相似,而和半年前的某個午後則關係薄弱。
這種「現在依賴過去」的特性,正是時間序列分析的核心。它打破了我們在初等統計學裡熟悉的一個假設:觀測值彼此獨立。一旦資料點之間存在時間上的相依,傳統的迴歸、t 檢定、信賴區間都會悄悄失效。本文將帶你從成分分解出發,認識自相關、定態與差分,最後走進 Box–Jenkins 建模流程與 ARIMA 模型——這是分析股市、環境與一切「隨時間演進」資料的共同語言。
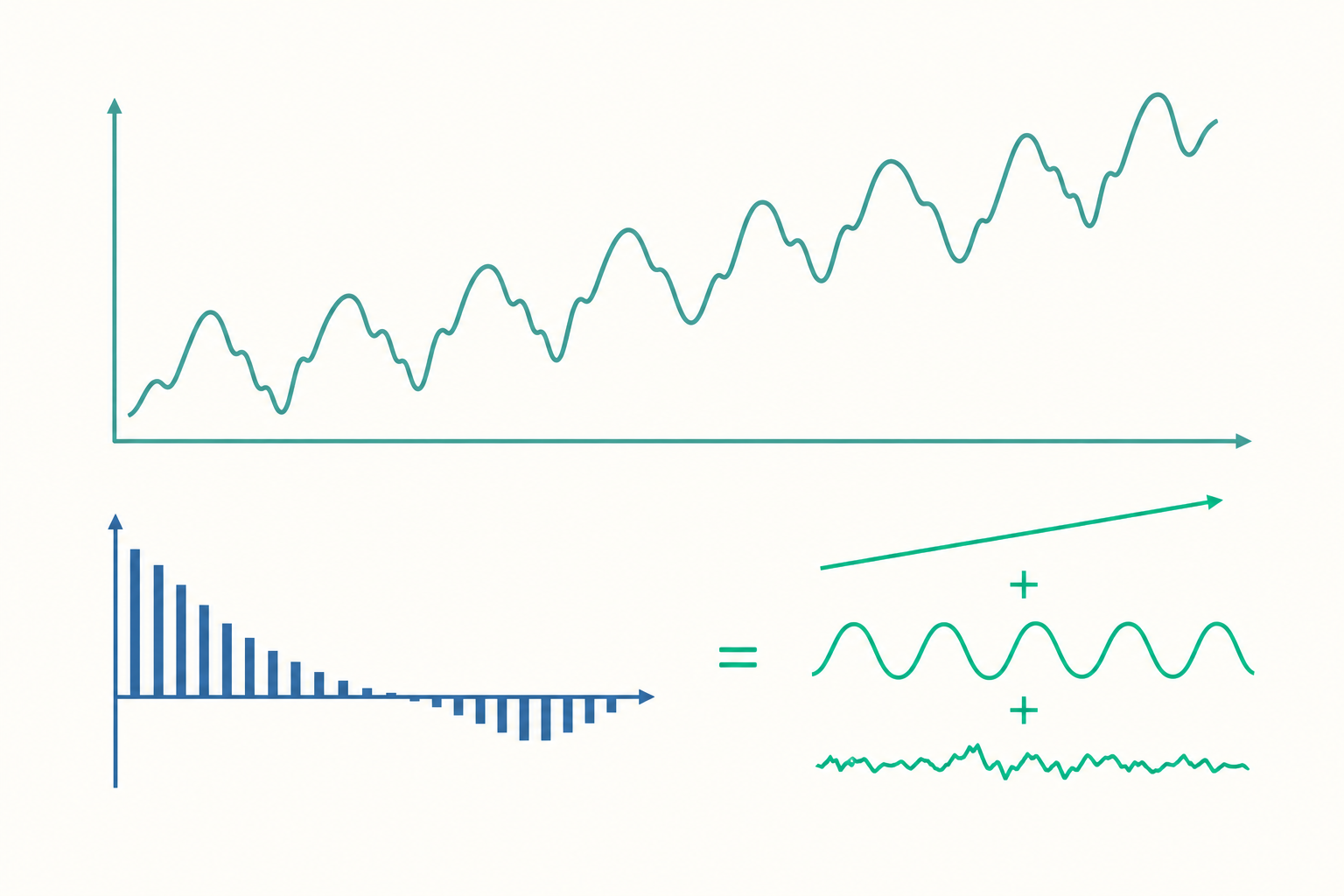
時間序列的四個成分
一條時間序列 $\{y_t\}$ 通常可以拆解成四種潛在來源的疊加。以加法模型為例:
$$ y_t = T_t + S_t + C_t + I_t $$
- 趨勢(Trend, $T_t$):長期、緩慢的方向性變化。例如某城市過去十年的平均氣溫逐步上升,或某公司營收長期成長。
- 季節(Seasonal, $S_t$):固定週期、可預測的規律波動。週期長度是已知且固定的,例如氣溫的年週期(夏熱冬冷)、零售業的每週或每年高峰。
- 循環(Cyclical, $C_t$):週期較長、長度不固定的起伏。最典型的是景氣循環——擴張與衰退會交替出現,但每一輪持續幾年並無定數。季節與循環的關鍵差異在於「週期是否固定」。
- 不規則(Irregular, $I_t$):扣除上述三者後剩下的隨機波動,又稱殘差或雜訊。理想上它應該是不可預測的白噪音。
當波動幅度隨水準放大時(例如營收越大、季節起伏的絕對金額也越大),則改用乘法模型 $y_t = T_t \times S_t \times C_t \times I_t$,或先取對數轉回加法結構。
自相關:時間序列的指紋
要量化「現在依賴過去」的程度,我們用自相關函數(Autocorrelation Function, ACF)。落後 $k$ 期的自相關係數定義為:
$$ \rho_k = \frac{\operatorname{Cov}(y_t, y_{t-k})}{\operatorname{Var}(y_t)} = \frac{\gamma_k}{\gamma_0} $$
其中 $\gamma_k = \operatorname{Cov}(y_t, y_{t-k})$ 是落後 $k$ 期的自共變異數。$\rho_k$ 介於 $-1$ 與 $1$ 之間,衡量 $y_t$ 與其 $k$ 期之前的數值之間的線性關聯。
但 ACF 有個盲點:若 $y_t$ 與 $y_{t-1}$ 相關,$y_{t-1}$ 又與 $y_{t-2}$ 相關,那麼 $y_t$ 與 $y_{t-2}$ 即使沒有「直接」關聯,也會因為這條傳遞鏈而顯示出相關。為了剝除中間項的間接影響,我們引入偏自相關函數(Partial Autocorrelation Function, PACF):$\phi_{kk}$ 衡量的是在控制了 $y_{t-1}, \dots, y_{t-k+1}$ 之後,$y_t$ 與 $y_{t-k}$ 之間的「淨」相關。
ACF 與 PACF 的截尾(cut-off)與拖尾(tail-off)型態,正是 Box–Jenkins 建模辨識模型階數的關鍵指紋,稍後會說明。
定態性:一切推論的地基
時間序列建模幾乎都建立在一個假設上:弱定態(weakly stationary)。它要求三件事:
- 期望值不隨時間改變:$E[y_t] = \mu$(常數)。
- 變異數不隨時間改變:$\operatorname{Var}(y_t) = \sigma^2$(常數)。
- 自共變異數只取決於時間間隔 $k$,與起點 $t$ 無關:$\operatorname{Cov}(y_t, y_{t-k}) = \gamma_k$。
直覺上,定態序列「沒有趨勢、沒有季節、波動幅度穩定」,看起來在一條水平線上下隨機跳動。為什麼非要定態?因為唯有統計性質穩定,我們才能用「過去的樣本」估計出對「未來」仍然成立的參數——否則參數本身一直在變,估了也沒用。
單根(unit root)是非定態最常見的成因。考慮一階自迴歸:
$$ y_t = \phi y_{t-1} + \varepsilon_t $$
當 $|\phi| < 1$ 時序列定態;當 $\phi = 1$ 時,模型變成 $y_t = y_{t-1} + \varepsilon_t$,也就是隨機漫步(random walk)。此時衝擊永不消散、變異數隨時間發散,序列具有「單根」。股價常被視為近似隨機漫步,這也是為何「用歷史股價預測未來」如此困難。檢定單根的標準工具是 ADF 檢定(Augmented Dickey–Fuller),其虛無假設為「存在單根(非定態)」。
差分與白噪音
若序列非定態,最常用的補救是差分(differencing)。一階差分定義為:
$$ \Delta y_t = y_t - y_{t-1} $$
差分能有效移除趨勢與單根:一個帶趨勢的隨機漫步,差分一次後往往就成為定態。若一次不夠,可再做二階差分 $\Delta^2 y_t = \Delta y_t - \Delta y_{t-1}$。對季節成分,則用季節差分 $\Delta_s y_t = y_t - y_{t-s}$($s$ 為季節週期,如月資料 $s=12$)。差分的次數 $d$ 正是 ARIMA 模型中的「I」。
差分的終點是把序列轉成接近白噪音(white noise)的形式。白噪音 $\{\varepsilon_t\}$ 滿足:
$$ E[\varepsilon_t] = 0, \quad \operatorname{Var}(\varepsilon_t) = \sigma^2, \quad \operatorname{Cov}(\varepsilon_t, \varepsilon_{t-k}) = 0 \ (k \neq 0) $$
也就是零均值、固定變異、且彼此不相關。白噪音是定態的最純粹形式,所有的自相關都為零。一個成功的時間序列模型,目標就是「榨乾」資料中的可預測結構,使殘差退化為白噪音——殘差若還殘留自相關,代表模型尚未捕捉完所有資訊。
AR、MA、ARMA 與 ARIMA
定態序列的建模有兩塊基本積木。
自迴歸模型 AR(p):用過去的觀測值線性組合來解釋現在。
$$ y_t = c + \phi_1 y_{t-1} + \phi_2 y_{t-2} + \cdots + \phi_p y_{t-p} + \varepsilon_t $$
移動平均模型 MA(q):用過去的隨機衝擊(誤差項)來解釋現在。
$$ y_t = c + \varepsilon_t + \theta_1 \varepsilon_{t-1} + \cdots + \theta_q \varepsilon_{t-q} $$
兩者合併即 ARMA(p, q),同時納入自身落後項與誤差落後項。而當原始序列需先差分 $d$ 次才定態,便擴充為 ARIMA(p, d, q)——Integrated 的「I」就代表這層差分。完整寫法為:對 $w_t = \Delta^d y_t$ 配適 ARMA(p, q)。
辨識階數的經驗法則是 ACF/PACF 的型態對照:
| 模型 | ACF | PACF |
|---|---|---|
| AR(p) | 拖尾(指數或正弦衰減) | 在落後 $p$ 後截尾 |
| MA(q) | 在落後 $q$ 後截尾 | 拖尾 |
| ARMA(p,q) | 拖尾 | 拖尾 |
移動平均平滑與指數平滑
除了 ARIMA 這類參數模型,實務上也常用平滑法快速抓出趨勢或做短期預測。
簡單移動平均(SMA)取最近 $m$ 期的算術平均當作平滑值:
$$ \hat{y}_t = \frac{1}{m}\sum_{i=0}^{m-1} y_{t-i} $$
它把雜訊抹平,但對所有期一視同仁,且反應較慢。
指數平滑(Exponential Smoothing)則讓越近的觀測值權重越大:
$$ \hat{y}_t = \alpha y_t + (1-\alpha)\hat{y}_{t-1}, \quad 0 < \alpha < 1 $$
平滑係數 $\alpha$ 越大,模型對最新變化越敏感。展開後可看到歷史權重以 $(1-\alpha)$ 的幾何級數遞減,故名「指數」。進階版本(Holt 處理趨勢、Holt–Winters 處理季節)能同時建模趨勢與季節成分,是業界短期預測的主力工具之一。
帶數字的小範例:手算自相關
假設我們有一段去除趨勢後的氣溫殘差,共 6 個觀測值(單位:°C):
$$ y = [2,\ 4,\ 6,\ 4,\ 2,\ 0] $$
平均數 $\bar{y} = (2+4+6+4+2+0)/6 = 3$。先算各期離差 $y_t - \bar{y}$:$[-1,\ 1,\ 3,\ 1,\ -1,\ -3]$。
落後 0 期的自共變異數(即變異數的分子):
$$ \sum (y_t-\bar{y})^2 = 1+1+9+1+1+9 = 22 $$
落後 1 期的自共變異數(相鄰兩期離差相乘後加總):
$$ \sum_{t=2}^{6}(y_t-\bar{y})(y_{t-1}-\bar{y}) = (1)(-1)+(3)(1)+(1)(3)+(-1)(1)+(-3)(-1) $$ $$ = -1 + 3 + 3 - 1 + 3 = 7 $$
於是落後 1 期的自相關估計值為:
$$ \hat{\rho}_1 = \frac{7}{22} \approx 0.318 $$
這個正值告訴我們:相鄰兩期的殘差傾向同向變動,序列尚有可建模的結構,殘差並非純白噪音。若這是模型配適後的殘差,我們會懷疑模型還沒抓乾淨。
為什麼不能直接套一般迴歸?
一個常見的誤解是:「時間是自變數,y 是依變數,那我跑個 $y_t = \beta_0 + \beta_1 t + \varepsilon_t$ 不就好了?」問題出在普通最小平方法(OLS)的核心假設——殘差彼此獨立。
時間序列的殘差幾乎總是自相關的:今天被高估,明天往往也被高估。當殘差存在正自相關時,會發生兩個嚴重後果:
- 係數的標準誤被低估,使 t 值膨脹,讓你誤以為某個變數「顯著」,實則不然——這就是計量經濟學中惡名昭彰的假性迴歸(spurious regression)。兩條各自走隨機漫步、毫無因果關係的序列,迴歸後常得到極高的 $R^2$ 與顯著的 t 值。
- 預測區間失準,因為模型沒有利用「殘差本身也可預測」這項資訊。
因此正確做法不是把相依性當麻煩丟掉,而是主動建模它——這正是 AR、MA 項存在的理由。
Box–Jenkins 建模流程(深入段)
Box 與 Jenkins 在 1970 年代提出一套系統化的 ARIMA 建模迭代流程,至今仍是時間序列實務的骨幹,分為四個階段:
-
辨識(Identification):先檢查定態性。畫出序列圖、ACF/PACF,必要時用 ADF 檢定。若非定態則差分(決定 $d$),再依差分後序列的 ACF/PACF 型態初步猜測 $p$ 與 $q$。
-
估計(Estimation):對候選的 ARIMA(p, d, q) 估計參數。AR 模型可用 Yule–Walker 方程或條件最小平方,含 MA 項時則須用最大概似估計(MLE),因為誤差項不可直接觀測,需透過遞迴或狀態空間表示來計算概似函數。模型選擇常以 AIC($\text{AIC} = -2\ln L + 2k$)或 BIC 比較,在配適度與參數簡約之間取捨。
-
診斷(Diagnostic Checking):檢查殘差是否為白噪音。若殘差仍有自相關,回到步驟一重新辨識。
-
預測(Forecasting):通過診斷後才用於預測,並給出預測區間。
Ljung–Box 檢定(深入段)
診斷階段的核心工具是 Ljung–Box 檢定,它一次檢驗「前 $h$ 個落後的自相關是否整體皆為零」,統計量為:
$$ Q = n(n+2)\sum_{k=1}^{h}\frac{\hat{\rho}_k^2}{n-k} $$
其中 $n$ 為樣本數,$\hat{\rho}_k$ 為殘差的落後 $k$ 期樣本自相關。在虛無假設「殘差為白噪音」下,$Q$ 近似服從自由度為 $h - m$ 的卡方分布($m$ 為估計的模型參數個數)。
判讀邏輯與一般檢定相反,需要特別小心:我們希望 $p$ 值大(不顯著)。若 $p$ 值小於 0.05,表示殘差仍存在顯著自相關,模型不合格,必須回頭增補階數;若 $p$ 值夠大,才代表殘差已退化為白噪音,模型可接受。
與其他方法的連結
ARIMA 假設線性與固定變異,但金融時序常有波動叢聚(volatility clustering)——大波動後接大波動。此時變異數本身隨時間變化,需用 ARCH/GARCH 模型對條件變異數建模,這也是恩格爾(Engle)獲頒諾貝爾經濟學獎的貢獻。另一條延伸是當多條序列雖各自有單根、卻存在長期均衡關係時,可用共整合(cointegration)與誤差修正模型(ECM)。近年機器學習的 LSTM、Transformer 也被用於時序預測,能捕捉非線性與長程依賴,但須留意它們犧牲了 ARIMA 的可解釋性與統計推論基礎。
需要強調的是:所有預測都建立在「未來的統計結構與過去相似」這個假設上。一旦發生結構性斷裂(如政策劇變、市場黑天鵝、環境異常事件),歷史外推就會失效。在 Uedu Finance 的股市時序與 Environomics 的環境時序分析中,我們始終將模型輸出視為「在既有假設下的條件性推估」,而非確定性的未來,並同步呈現預測區間與假設限制。
重點回顧
- 時間序列由趨勢、季節、循環、不規則四成分構成;季節週期固定、循環週期不固定,是兩者的關鍵分野。
- ACF 衡量含間接傳遞的整體自相關,PACF 剝除中間項只留淨相關;兩者的截尾與拖尾型態是辨識 AR/MA 階數的指紋。
- 建模前須確保定態:用 ADF 檢定診斷單根,用差分(次數即 ARIMA 的 $d$)移除趨勢與單根,目標是把序列推向白噪音。
- ARIMA(p, d, q) 結合自迴歸、差分與移動平均;Box–Jenkins 以「辨識→估計→診斷→預測」迭代建模,並用 Ljung–Box 檢定確認殘差為白噪音。
- 時間序列殘差自相關會讓一般迴歸標準誤失真、產生假性迴歸,因此必須主動建模相依性而非忽略它。
深入探討(研究所視角)
從更嚴謹的視角看,ARMA 的存在與唯一性建立在多項式根的條件上。將模型寫成落後算子 $L$($Ly_t = y_{t-1}$)形式:
$$ \phi(L)\,y_t = \theta(L)\,\varepsilon_t $$
其中 $\phi(L) = 1 - \phi_1 L - \cdots - \phi_p L^p$、$\theta(L) = 1 + \theta_1 L + \cdots + \theta_q L^q$。定態的充要條件是 $\phi(L)=0$ 的所有根都落在單位圓外($|z|>1$);可逆性(invertibility)則要求 $\theta(L)=0$ 的根同樣落在單位圓外。可逆性保證 MA 過程能唯一地反寫成 $\text{AR}(\infty)$,這正是 PACF 對 MA 拖尾、ACF 對 AR 拖尾的數學根源——任一有限階模型都能展成另一型的無限階表示。當 $\phi(L)$ 恰有一個根等於 1(落在單位圓上),便對應前述的單根與隨機漫步,須以差分將該根「約掉」。
估計理論上,含 MA 項的概似函數沒有封閉解,實務多以狀態空間表示(state-space representation)搭配 Kalman 濾波器遞迴計算精確概似,再以數值最佳化求 MLE。在適當正則條件下,ARMA 的 MLE 具有一致性與漸近常態性,標準誤可由資訊矩陣(Hessian 的負逆)得到。模型選擇的 AIC/BIC 之別在於罰項:BIC 的 $\ln(n)\cdot k$ 隨樣本數增長而懲罰更重,在大樣本下傾向選出更簡約且一致的模型,AIC 則偏向預測最優但可能略為過度配適。
最後,務必區分樣本內配適與樣本外預測。Ljung–Box 通過、AIC 最低,都只說明模型在已知資料上表現良好;真正的檢驗是時間序列交叉驗證(如滾動原點預測),在從未見過的未來資料上評估誤差。這條原則——以及對結構斷裂、定態假設、預測區間的誠實揭露——是把時間序列方法負責任地應用於 Uedu Finance 與 Environomics 真實資料的前提。