
大數法則的弱形式與強形式:兩種收斂的嚴謹分野
從依機率收斂到幾乎必然收斂,看 WLLN 與 SLLN 的推導、條件與漸近應用
從「平均會趨於真值」到兩種收斂
直覺上,我們相信擲硬幣愈多次,正面比例會愈靠近 $0.5$;抽樣愈多,樣本平均會愈靠近母體期望值。但「靠近」這件事,數學上其實有兩種截然不同的精確化方式。大數法則(Law of Large Numbers, LLN)正是把這個直覺嚴格化的定理,而它分裂為弱形式(Weak LLN, WLLN)與強形式(Strong LLN, SLLN)兩支,差別不在於結論「平均收斂到期望值」這句話本身,而在於「收斂」這個動詞所指的數學模式。理解這兩種收斂的差異,是統計推論、估計理論與漸近分析的基石。
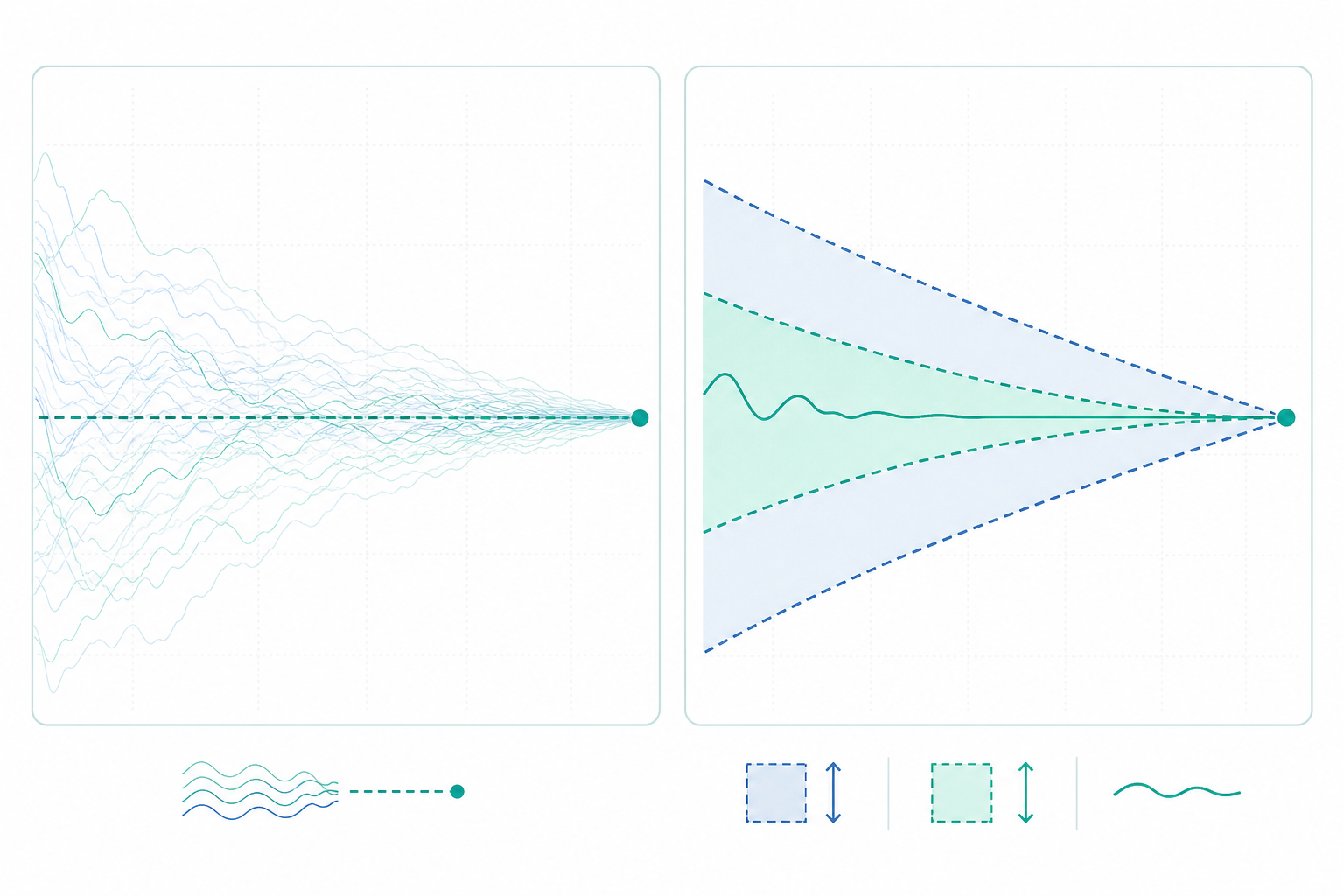
設定與兩種收斂的定義
令 $X_1, X_2, \dots$ 為一列隨機變數,期望值 $\mathbb{E}[X_i] = \mu$,並定義樣本平均
$$\bar{X}_n = \frac{1}{n}\sum_{i=1}^{n} X_i.$$
弱大數法則斷言 $\bar{X}_n$ 依機率收斂到 $\mu$,記作 $\bar{X}_n \xrightarrow{P} \mu$,意即對任意 $\varepsilon > 0$,
$$\lim_{n \to \infty} \mathbb{P}\big(|\bar{X}_n - \mu| > \varepsilon\big) = 0.$$
它說的是:對於「每個固定的大 $n$」,樣本平均偏離 $\mu$ 超過 $\varepsilon$ 的機率可以任意小。但它不保證某一條具體的樣本路徑 $(\bar{X}_1, \bar{X}_2, \dots)$ 最終會穩定下來——偏差事件可以無限次發生,只要它們愈來愈稀疏。
強大數法則則斷言 $\bar{X}_n$ 幾乎必然收斂到 $\mu$,記作 $\bar{X}_n \xrightarrow{a.s.} \mu$,意即
$$\mathbb{P}\Big(\lim_{n \to \infty} \bar{X}_n = \mu\Big) = 1.$$
這是對「整條路徑」的陳述:除了一個機率為零的例外集合,每一條樣本軌跡都收斂到 $\mu$。幾乎必然收斂蘊含依機率收斂,反之不然——這正是「強」與「弱」的層級關係。
弱形式的推導:Chebyshev 路線
WLLN 最透明的證明,是在有限變異數假設下走 Chebyshev 不等式。設 $X_i$ 獨立同分布(i.i.d.),$\operatorname{Var}(X_i) = \sigma^2 < \infty$。由獨立性,
$$\operatorname{Var}(\bar{X}_n) = \frac{1}{n^2}\sum_{i=1}^{n}\operatorname{Var}(X_i) = \frac{\sigma^2}{n}.$$
套用 Chebyshev 不等式 $\mathbb{P}(|Y - \mathbb{E}Y| > \varepsilon) \le \operatorname{Var}(Y)/\varepsilon^2$ 於 $Y = \bar{X}_n$(注意 $\mathbb{E}[\bar{X}_n] = \mu$):
$$\mathbb{P}\big(|\bar{X}_n - \mu| > \varepsilon\big) \le \frac{\operatorname{Var}(\bar{X}_n)}{\varepsilon^2} = \frac{\sigma^2}{n\varepsilon^2} \xrightarrow{n \to \infty} 0.$$
證畢。值得強調的是,這個界 $\sigma^2/(n\varepsilon^2)$ 不只證明了收斂,還給出有限樣本的偏差機率上界,是樣本量規劃的雛形。更精細的 Khinchin 定理進一步指出:i.i.d. 條件下,只要 $\mathbb{E}|X_i| < \infty$(不需有限變異數)WLLN 仍成立,這需動用特徵函數的論證,已超出 Chebyshev 的範圍。
強形式為何更難
SLLN 的證明遠比 WLLN 棘手,因為「整條路徑收斂」是對無窮多個 $n$ 同時下注。Kolmogorov 的強大數法則指出:i.i.d. 條件下,$\bar{X}_n \xrightarrow{a.s.} \mu$ 的充要條件就是 $\mathbb{E}|X_i| < \infty$。其證明核心工具是 Borel–Cantelli 引理與 Kolmogorov 不等式(一個對部分和的極大值不等式)。直覺上,要排除「偏差事件無限次發生」,必須控制的不是單一 $\mathbb{P}(|\bar{X}_n - \mu| > \varepsilon)$,而是其在 $n$ 上的累加可和性:若 $\sum_n \mathbb{P}(|\bar{X}_n - \mu| > \varepsilon) < \infty$,則由 Borel–Cantelli 第一引理,偏差事件僅有限次發生,路徑必收斂。WLLN 只要逐項趨零、SLLN 要求整列可和,這道可和性的門檻正是兩者難度的分水嶺。
定量小範例:擲公正硬幣
令 $X_i$ 為第 $i$ 次擲公正硬幣的指示變數,正面 $X_i = 1$、反面 $X_i = 0$,故 $X_i \sim \text{Bernoulli}(0.5)$,$\mu = 0.5$,$\sigma^2 = p(1-p) = 0.25$。問:要保證樣本比例 $\bar{X}_n$ 偏離 $0.5$ 不超過 $\varepsilon = 0.05$ 的機率至少 $95\%$,依 Chebyshev 界需要多少次投擲?
依 WLLN 推導,
$$\mathbb{P}\big(|\bar{X}_n - 0.5| > 0.05\big) \le \frac{\sigma^2}{n\varepsilon^2} = \frac{0.25}{n \times 0.0025} = \frac{100}{n}.$$
要使此上界 $\le 0.05$(即落在範圍內的機率 $\ge 0.95$),解
$$\frac{100}{n} \le 0.05 \;\Longrightarrow\; n \ge 2000.$$
故 Chebyshev 保守地要求 $n \ge 2000$ 次。值得對照的是,若改用中央極限定理的常態近似,$\bar{X}_n$ 的標準誤為 $\sigma/\sqrt{n} = 0.5/\sqrt{n}$,要 $1.96 \times 0.5/\sqrt{n} \le 0.05$ 只需 $n \ge 384$。兩者的落差正說明 Chebyshev 界雖普適卻寬鬆——它不需分布形狀的假設,代價是樣本量估計的過度保守。這是統計素養的一課:收斂保證的「速度」與「所需假設」是一組權衡。
統計素養提醒
大數法則保證的是樣本平均作為點估計的一致性,而非任何因果結論:再多的觀測樣本平均,若抽樣機制本身有系統性偏誤(如選擇偏誤),收斂到的是「有偏的母體量」而非真正的因果效應。LLN 也常被誤用為「賭徒謬誤」的反面——它說的是長期比例趨穩,不是短期會有「補償」機制。此外,LLN 描述的是估計量隨 $n$ 的行為,與單次信賴區間的覆蓋率、與 $p$ 值的解讀都是不同層次的概念,切勿混為一談。
深入探討(研究所視角)
在研究所層次,LLN 不再只是「平均會收斂」,而是一整套漸近統計學的入口。給定估計量序列 $\hat{\theta}_n$,一致性(consistency)$\hat{\theta}_n \xrightarrow{P} \theta_0$ 正是 LLN 的直接應用:對於最大概似估計(MLE),對數概似的樣本平均 $\frac{1}{n}\sum_i \log f(X_i;\theta)$ 依 LLN 收斂到母體期望 $\mathbb{E}_{\theta_0}[\log f(X;\theta)]$,後者在 $\theta_0$ 取極大(由 Jensen 不等式與 Kullback–Leibler 散度的非負性保證),這構成 Wald 一致性論證的骨架。動差法(Method of Moments)的一致性更直接:樣本動差 $\frac{1}{n}\sum_i X_i^k \xrightarrow{a.s.} \mathbb{E}[X^k]$ 由 SLLN 給出,再經連續映射定理傳遞到參數估計。
LLN 之上是 CLT 與更細的收斂率理論。MLE 在正則條件下滿足 $\sqrt{n}(\hat{\theta}_n - \theta_0) \xrightarrow{d} \mathcal{N}(0, I(\theta_0)^{-1})$,其中 $I(\theta_0)$ 為 Fisher 資訊量,且此漸近變異數達到 Cramér–Rao 下界——這是 MLE「漸近有效」的精確意涵。Delta 方法則把這套漸近常態性傳遞到參數的可微函數上。更前沿的非漸近分析(Hoeffding、Bernstein 不等式)把 Chebyshev 的多項式尾界升級為指數尾界,是高維統計與經驗風險最小化中泛化界(generalization bound)的核心工具:機器學習中「訓練誤差收斂到測試誤差」本質上就是對損失函數套用 LLN 與其集中不等式版本。
貝氏對應方面,Bernstein–von Mises 定理是 LLN/CLT 的貝氏鏡像:在正則模型下,當 $n \to \infty$,後驗分布漸近趨於以 MLE 為中心、變異數為 $I(\theta_0)^{-1}/n$ 的常態,且先驗的影響被資料淹沒。這解釋了為何大樣本下貝氏可信區間與頻率派信賴區間數值趨於一致——但須警惕:在非正則(如參數在邊界、模型誤設)情形下此漸近等價會破裂,貝氏與頻率派的詮釋差異重新浮現。
在因果推論中,LLN 是識別策略的隱形地基。逆機率加權(IPW)、雙重穩健估計等的一致性,都依賴某個樣本平均依機率收斂到對應的母體泛函;但 LLN 只保證收斂到「估計式所定義的目標量」,該目標量是否等於因果效應,取決於可忽略性與正定性等識別假設,與 LLN 本身無關。這正是把「相關」誤當「因果」的最深陷阱:收斂性是統計性質,識別性是因果假設,兩者必須分開檢視。半參數效率理論(影響函數、切空間投影)則進一步刻畫了在這些假設下估計量所能達到的最小漸近變異數,是當代因果機器學習(如 TMLE、double machine learning)的理論底盤。