
平均數說了一半:全距、變異數與標準差的故事
同樣的平均分,背後可能是兩種完全不同的世界——資料有多分散,和中心在哪同樣重要。
平均數說了一半的故事
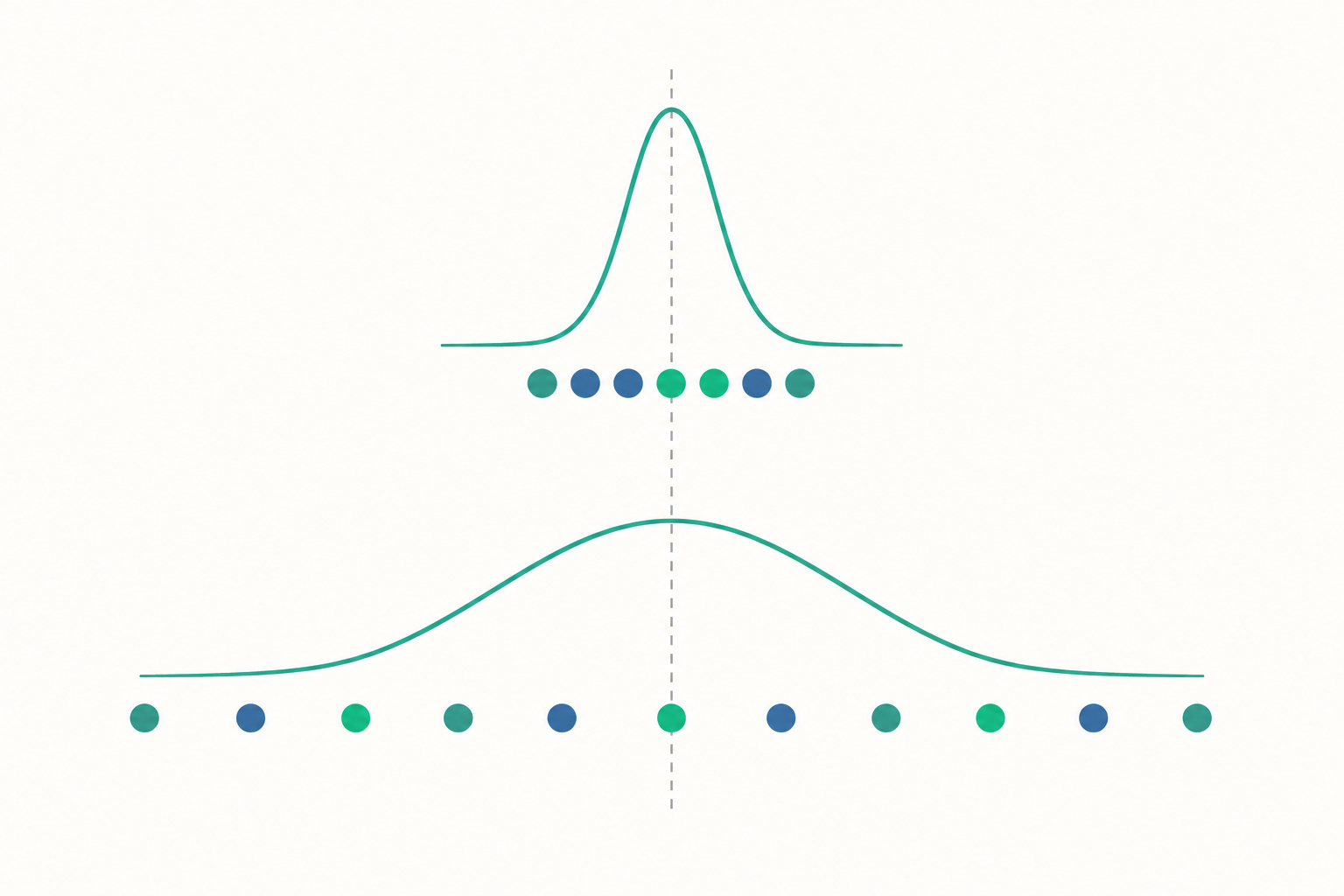
想像兩個班級的期中考都考了 70 分的平均。聽起來一模一樣,對吧?但走進教室你會發現天差地別。A 班每個人都落在 65 到 75 分之間,分數緊緊靠在一起;B 班卻是有人考 40 分、有人考 100 分,平均才被「拉」到 70。同樣的平均數,背後是兩種完全不同的學習現實。
這就是為什麼統計學除了關心「資料集中在哪裡」(集中趨勢,像平均數、中位數),同樣關心「資料分散得多開」——也就是這篇要談的離散程度(dispersion)。一句話總結:平均數告訴你故事的中心,離散程度告訴你故事有多曲折。
最直覺的指標:全距
最容易理解的離散指標是全距(range),就是最大值減最小值:
$$R = x_{\max} - x_{\min}$$
A 班的全距是 $75 - 65 = 10$ 分,B 班是 $100 - 40 = 60$ 分。一眼就看出 B 班分散多了。
全距的優點是「快」,缺點也很明顯:它只看頭尾兩個極端值,中間幾十筆資料長什麼樣完全不管。只要有一個離群的高分或低分,全距就會被誇大。這就像用「最高的人和最矮的人身高差」來描述一個社團——資訊太少了。我們需要一個能讓每一筆資料都發聲的指標。
變異數:把每個差距都算進來
更細緻的做法是看「每筆資料離平均數有多遠」。對每個觀測值 $x_i$,它與平均數 $\bar{x}$ 的差距叫做離差 $x_i - \bar{x}$。
但這裡有個小陷阱:如果直接把所有離差加起來,正負會互相抵消,結果永遠是 0(這正是平均數的定義性質)。為了不讓正負相消,我們把每個離差平方後再平均。這就是變異數(variance):
$$\sigma^2 = \frac{1}{n}\sum_{i=1}^{n}(x_i - \bar{x})^2$$
我們用一個小例子算一遍。假設某社團 5 位成員每週讀書時數為 $\{2, 4, 4, 6, 9\}$ 小時。
第一步,算平均數:
$$\bar{x} = \frac{2+4+4+6+9}{5} = \frac{25}{5} = 5 \text{ 小時}$$
第二步,算每筆的離差平方:
| $x_i$ | $x_i - \bar{x}$ | $(x_i-\bar{x})^2$ |
|---|---|---|
| 2 | $-3$ | 9 |
| 4 | $-1$ | 1 |
| 4 | $-1$ | 1 |
| 6 | $+1$ | 1 |
| 9 | $+4$ | 16 |
第三步,平方差加總再平均:
$$\sigma^2 = \frac{9+1+1+1+16}{5} = \frac{28}{5} = 5.6$$
於是這組資料的變異數是 $5.6$。
標準差:把單位變回來
變異數有個讓人困擾的地方:它的單位是「小時的平方」,這在現實裡沒有意義。為了讓離散程度回到原本的單位,我們把變異數開根號,得到標準差(standard deviation):
$$\sigma = \sqrt{\sigma^2} = \sqrt{5.6} \approx 2.37 \text{ 小時}$$
標準差可以理解成「資料點與平均數的典型距離」。這組資料平均每人讀 5 小時,而大家偏離平均的「典型幅度」大約是 2.37 小時。標準差越大,資料越分散;越小,越集中。
標準差是統計學最常用的離散指標,因為它和資料同單位、又把每筆資料都納入考量。許多後續工具——標準分數、信賴區間、假設檢定——全都建立在它之上。例如把原始分數轉成標準分數(z 分數):
$$z = \frac{x - \bar{x}}{\sigma}$$
讀書 9 小時的那位成員,$z = \frac{9-5}{2.37} \approx 1.69$,代表他比平均高出約 1.69 個標準差。z 分數讓不同單位、不同量尺的資料可以放在同一把尺上比較。
n 還是 n−1?一個重要的小細節
你可能在課本或試算表裡看過另一個版本的變異數,分母是 $n-1$ 而不是 $n$:
$$s^2 = \frac{1}{n-1}\sum_{i=1}^{n}(x_i - \bar{x})^2$$
差別在於:當我們手上只有樣本、想用它去估計背後整個母體的變異數時,用 $n$ 當分母會系統性地低估。改用 $n-1$(稱為自由度的修正)能讓估計「不偏」。簡單記法:
- 你的資料就是全部(整個母體)→ 用 $n$,記作 $\sigma^2$。
- 你的資料是抽樣的一部分,要推估母體 → 用 $n-1$,記作 $s^2$。
上面 5 人若是「全部成員」,用 $n=5$ 得 $5.6$;若只是從大社團「抽出的 5 人樣本」,則用 $n-1=4$,得 $s^2 = 28/4 = 7$。日常分析多半是後者,所以 Excel 的 STDEV 預設用 $n-1$。
離散程度為什麼這麼重要
離散程度不只是課本練習,它影響我們對世界的判斷。投資時,兩檔報酬率平均相同的基金,標準差大的那檔風險更高。品管時,產品尺寸的標準差越小,代表製程越穩定。做研究時,若兩組平均看似有差,但組內離散都很大、彼此重疊嚴重,那這個「差異」很可能只是隨機波動,談不上真正的效果。
這帶出一個統計素養的提醒:只報告平均數而不報告離散程度,是不完整甚至會誤導的。 看到「平均月薪 8 萬」時,務必追問分散程度——少數高薪者就能把平均拉高,多數人其實遠低於這個數字。集中趨勢與離散程度,永遠要成對地看。
深入探討(研究所視角)
從機率論的角度,變異數有更嚴謹的定義。對隨機變數 $X$,其變異數是「離差平方的期望值」:
$$\operatorname{Var}(X) = \mathbb{E}\big[(X - \mu)^2\big] = \mathbb{E}[X^2] - \big(\mathbb{E}[X]\big)^2$$
這個展開式(移動公式)是實務計算的利器。變異數還有重要的線性性質:對常數 $a,b$,$\operatorname{Var}(aX+b) = a^2\operatorname{Var}(X)$(平移不改變離散,縮放則按平方放大);而對獨立的 $X,Y$,$\operatorname{Var}(X+Y)=\operatorname{Var}(X)+\operatorname{Var}(Y)$。後者正是為何 $n$ 個獨立同分布觀測的樣本平均,其變異數會縮小為 $\sigma^2/n$——大數法則與中央極限定理的根基。
估計量的性質解釋了 $n-1$ 之謎。樣本變異數 $s^2$ 是母體變異數 $\sigma^2$ 的不偏估計量,即 $\mathbb{E}[s^2]=\sigma^2$。直覺是:用樣本平均 $\bar{x}$(而非未知的真實 $\mu$)計算離差時,會「用掉」一個自由度,因為 $\bar{x}$ 是從同一批資料估出來的、天生比 $\mu$ 更貼近樣本,導致平方和偏小,須以 $n-1$ 補償。值得注意的是,$s^2$ 雖不偏,標準差 $s$ 卻是 $\sigma$ 的有偏估計(因為平方根是凹函數,由 Jensen 不等式可知 $\mathbb{E}[s]\le\sigma$),這常被忽略。除了不偏性,好的估計量還追求一致性(樣本越大越收斂到真值)與有效性(在不偏估計中變異數最小)。
從最大概似估計(MLE)出發,若假設資料來自常態分布,對變異數求概似函數的最大值,得到的估計量分母恰是 $n$(即 $\sigma^2_{\text{MLE}}$ 是有偏的)。這說明 MLE 不保證不偏,但在大樣本下具漸近不偏與漸近有效性。
在應用層面,當我們比較兩組平均數的差異時,效果量 Cohen's $d$ 把差異用合併標準差標準化:
$$d = \frac{\bar{x}_1 - \bar{x}_2}{s_{\text{pooled}}}$$
它回答了 p 值無法回答的問題——差異「有多大」而非「是否存在」。這呼應一個常見誤解:p 值小不等於效果大,巨大樣本下即使微不足道的差異也能達到統計顯著。離散程度(透過 $s_{\text{pooled}}$)正是把「顯著」翻譯成「實質重要」的橋樑。
貝氏觀點則把變異數本身視為帶有不確定性的參數:常以逆伽瑪分布(Inverse-Gamma)作為其共軛先驗,觀測資料後更新為後驗分布,讓我們不僅得到變異數的點估計,更得到它的整個可信區間。最後,在機器學習中,離散程度化身為著名的偏差—變異數權衡(bias–variance tradeoff):模型的預測誤差可分解為偏差平方、變異數與不可約雜訊三項,過度複雜的模型變異數高(過擬合),過度簡單則偏差高(欠擬合),找到平衡正是泛化能力的核心。