
相關係數:兩變數同進退的密碼與陷阱
從一個數字看懂兩件事如何「一起變」,以及為何相關永遠不等於因果。
當兩件事「一起變」:相關說了什麼?
你大概聽過這些說法:「身高越高,體重越重」「讀書時間越長,成績越好」「冰淇淋賣得越多,溺水的人越多」。這些句子有一個共同點——它們都在描述「兩個變數一起變動」的傾向。統計學把這種傾向量化成一個數字,叫做相關係數(correlation coefficient)。
相關係數最常見的版本是皮爾森相關係數(Pearson's $r$),它是一個介於 $-1$ 到 $+1$ 之間的數字:
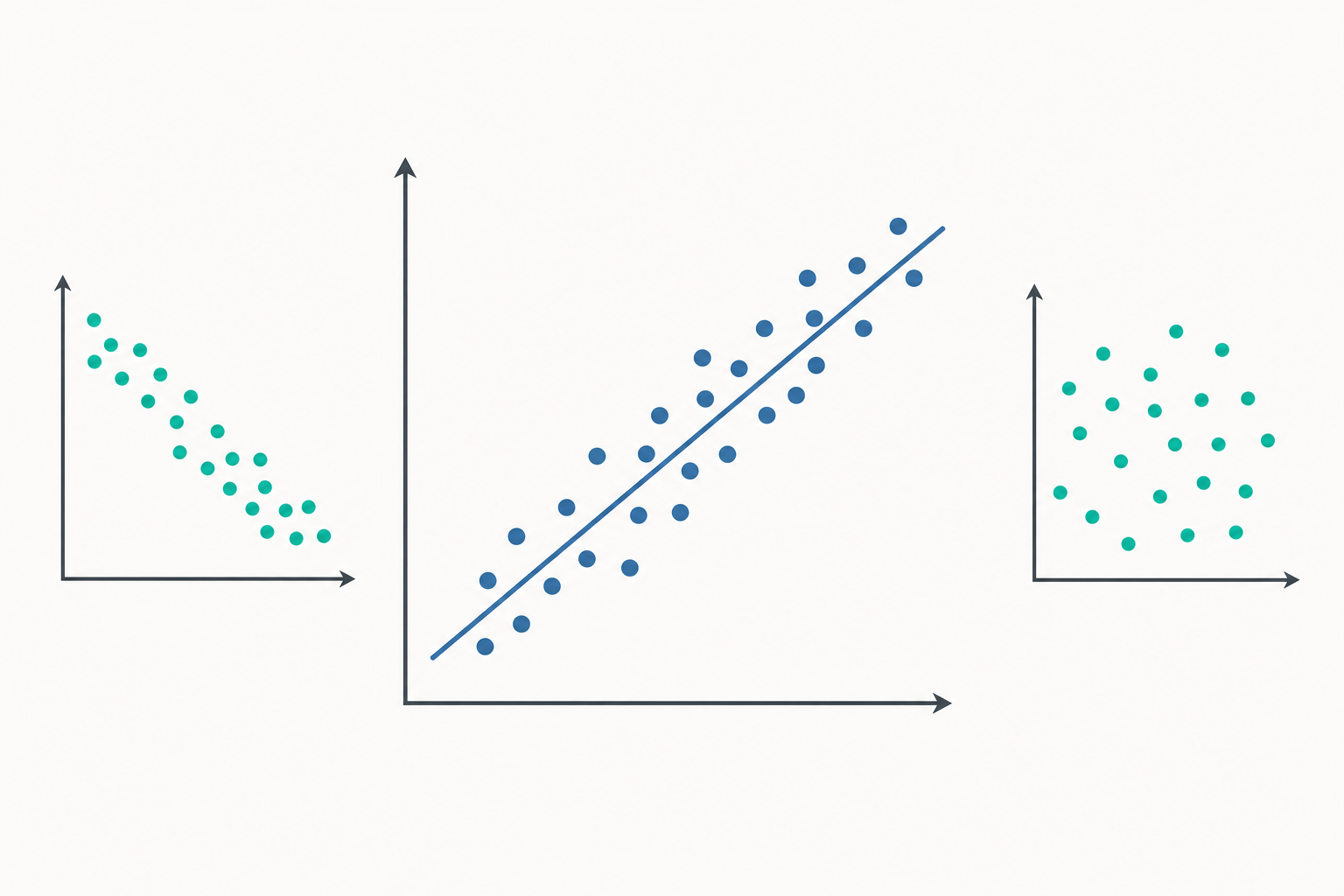
- $r$ 接近 $+1$:兩變數「同進退」,一個變大,另一個也傾向變大(正相關)。
- $r$ 接近 $-1$:兩變數「反著走」,一個變大,另一個傾向變小(負相關)。
- $r$ 接近 $0$:兩者之間沒有明顯的「直線」關係。
注意最後一句的關鍵字:直線。皮爾森相關只衡量「線性」關係的強弱,這個限制稍後會反咬我們一口。
相關係數怎麼算出來的?
直覺上,相關係數在問一個問題:「當 $x$ 比它的平均高時,$y$ 是不是也傾向比它的平均高?」
我們先看共變異數(covariance),它把每個資料點與平均的偏差相乘再平均:
$$\text{Cov}(x,y)=\frac{1}{n}\sum_{i=1}^{n}(x_i-\bar{x})(y_i-\bar{y})$$
如果 $x$ 高於平均時 $y$ 也常高於平均(兩個偏差同號),乘積為正,共變異數就偏正;若一高一低(偏差異號),乘積為負。
但共變異數有個麻煩:它帶單位。用公分算和用公尺算,數字差很多,無法跨情境比較。於是皮爾森把它「標準化」,除以兩個變數的標準差:
$$r=\frac{\sum (x_i-\bar{x})(y_i-\bar{y})}{\sqrt{\sum (x_i-\bar{x})^2}\;\sqrt{\sum (y_i-\bar{y})^2}}$$
除以標準差後,單位消掉了,$r$ 就被「鎖」在 $-1$ 到 $1$ 之間,成為一個純粹比較強弱的指標。
一個帶數字的小範例
假設我們記錄了 5 位同學「每週讀書時數 $x$」與「小考分數 $y$」:
| 同學 | $x$(時數) | $y$(分數) |
|---|---|---|
| A | 2 | 50 |
| B | 4 | 60 |
| C | 6 | 70 |
| D | 8 | 75 |
| E | 10 | 95 |
步驟一:算平均。
$$\bar{x}=\frac{2+4+6+8+10}{5}=6,\qquad \bar{y}=\frac{50+60+70+75+95}{5}=70$$
步驟二:算各點偏差與乘積。
| $x_i-\bar{x}$ | $y_i-\bar{y}$ | 乘積 | $(x_i-\bar{x})^2$ | $(y_i-\bar{y})^2$ |
|---|---|---|---|---|
| $-4$ | $-20$ | $80$ | $16$ | $400$ |
| $-2$ | $-10$ | $20$ | $4$ | $100$ |
| $0$ | $0$ | $0$ | $0$ | $0$ |
| $2$ | $5$ | $10$ | $4$ | $25$ |
| $4$ | $25$ | $100$ | $16$ | $625$ |
步驟三:加總。
$$\sum(x_i-\bar{x})(y_i-\bar{y})=80+20+0+10+100=210$$ $$\sum(x_i-\bar{x})^2=40,\qquad \sum(y_i-\bar{y})^2=1150$$
步驟四:代入公式。
$$r=\frac{210}{\sqrt{40}\times\sqrt{1150}}=\frac{210}{6.32\times33.91}\approx\frac{210}{214.4}\approx 0.98$$
$r\approx 0.98$ 是很強的正相關,符合直覺:讀書時間越長,分數確實傾向越高。但請忍住——還不能說「讀書讓分數變高」。
相關不等於因果
這是統計素養裡最重要、也最常被違反的一條。回到開頭那個經典例子:冰淇淋銷量與溺水人數高度正相關。難道吃冰淇淋會害人溺水嗎?
真正的解釋是第三變數——氣溫。天氣熱,大家既買更多冰淇淋,也更常去玩水,於是溺水意外增加。冰淇淋和溺水之間的相關,是被「氣溫」這個共同原因偷偷牽起來的。這種變數稱為干擾變數(confounder)。
要從相關走到因果,通常需要隨機對照實驗,或在觀察資料中用統計方法控制干擾變數。光看一個 $r$ 值,永遠無法回答「誰造成誰」。
相關係數的三個陷阱
陷阱一:只抓得到直線。 想像 $y=x^2$ 這種完美的拋物線關係,左半邊往下、右半邊往上,整體算下來 $r$ 可能接近 $0$。資料明明有強烈規律,皮爾森卻說「沒關係」,因為它不是直線。
陷阱二:離群值的暴力。 一兩個極端的點,就能把 $r$ 從 $0$ 拉到 $0.8$,或反過來摧毀一個真實的相關。畫散布圖(scatter plot)永遠是第一步,別只信數字。
陷阱三:相關強不代表斜率大。 $r=0.9$ 只說「點很貼近一條直線」,不說那條線「斜得多陡」。「關係多緊密」和「影響多大」是兩回事。
著名的「安斯庫姆四重奏(Anscombe's quartet)」就是用四組統計量幾乎相同、長相卻天差地遠的資料,提醒我們:先畫圖,再下結論。
深入探討(研究所視角)
在母體層次,皮爾森相關係數定義為標準化的共變異數:$\rho=\dfrac{\text{Cov}(X,Y)}{\sigma_X\sigma_Y}$,樣本 $r$ 是它的估計量。$r$ 對 $\rho$ 一致(consistent),但並非不偏:$E[r]\neq\rho$,在小樣本與 $\rho$ 偏離 0 時偏誤尤其明顯,存在約 $-\rho(1-\rho^2)/(2n)$ 量級的修正。$r$ 的抽樣分布也高度偏斜且受 $-1,1$ 邊界擠壓,因此不能直接套常態近似做推論。Fisher 提出 $z=\frac{1}{2}\ln\frac{1+r}{1-r}=\operatorname{arctanh}(r)$ 變換,使其近似常態、變異數約為 $\frac{1}{n-3}$,這正是建構 $\rho$ 信賴區間與檢定 $H_0:\rho_1=\rho_2$ 的標準做法。
檢定 $H_0:\rho=0$ 時,統計量 $t=\frac{r\sqrt{n-2}}{\sqrt{1-r^2}}$ 在虛無假設下服從自由度 $n-2$ 的 $t$ 分布;自由度損失 2 是因為估計直線需要先估出截距與斜率兩個參數。此處要警惕對 p 值的誤解:$p$ 小只代表「若 $\rho$ 真為 0,看到這麼極端的 $r$ 很不尋常」,它不是 $\rho=0$ 的機率,也不衡量關係強弱;大樣本下即使 $r=0.05$ 都可能「顯著」。同理,95% 信賴區間的正確詮釋是「此種程序長期下有 95% 會涵蓋真值」,而非「真值有 95% 機率落在這個區間」。
$r^2$(決定係數)在簡單線性迴歸中等於被解釋變異的比例,常被當作效果量(effect size);Cohen 給出 $r=.1/.3/.5$ 為小/中/大的經驗參考。但效果量的判讀仍須回到領域脈絡。
皮爾森只捕捉線性,對單調但非線性的關係,Spearman 等級相關或 Kendall's $\tau$ 更穩健,後者對離群值與非常態更不敏感。資訊論的互資訊(mutual information)$I(X;Y)$ 則能偵測任意形式的依賴,$I=0$ 等價於統計獨立,是機器學習特徵選擇的常用判準。值得注意的是,$\rho=0$ 僅意味「不線性相關」而非「獨立」,唯有在聯合常態分布下兩者才等價。
貝氏觀點則為 $\rho$ 設先驗(如 LKJ 分布或在 Fisher $z$ 尺度上設常態先驗),由資料更新出後驗分布,直接給出「在已觀測資料下,$\rho$ 落在某區間的可信度」——這恰好是頻率學派信賴區間常被誤解成的那種陳述。