
卡方、t 與 F 分布:常態抽樣理論的三根枝幹
從標準常態的平方和、未知變異數的標準化、到變異數比值,剖析三大抽樣分布的構造、自由度與推論連結
從常態母體出發:為什麼是這三個分布
當我們從常態母體抽樣並建構統計量時,會反覆遇到三個面孔:卡方分布 $\chi^2$、學生 t 分布、以及 F 分布。直覺上,它們分別回答三類問題:「平方和有多大?」「在不知道母體變異數時,平均數偏離多遠才算反常?」「兩個變異來源誰大誰小?」這三者並非各自獨立的發明,而是同一個常態抽樣骨架上長出的三根枝幹。本篇要把它們的數學機制攤開,說明彼此如何由標準常態變數組合而成,並串起 ANOVA、迴歸與假設檢定背後共通的抽樣分布邏輯。
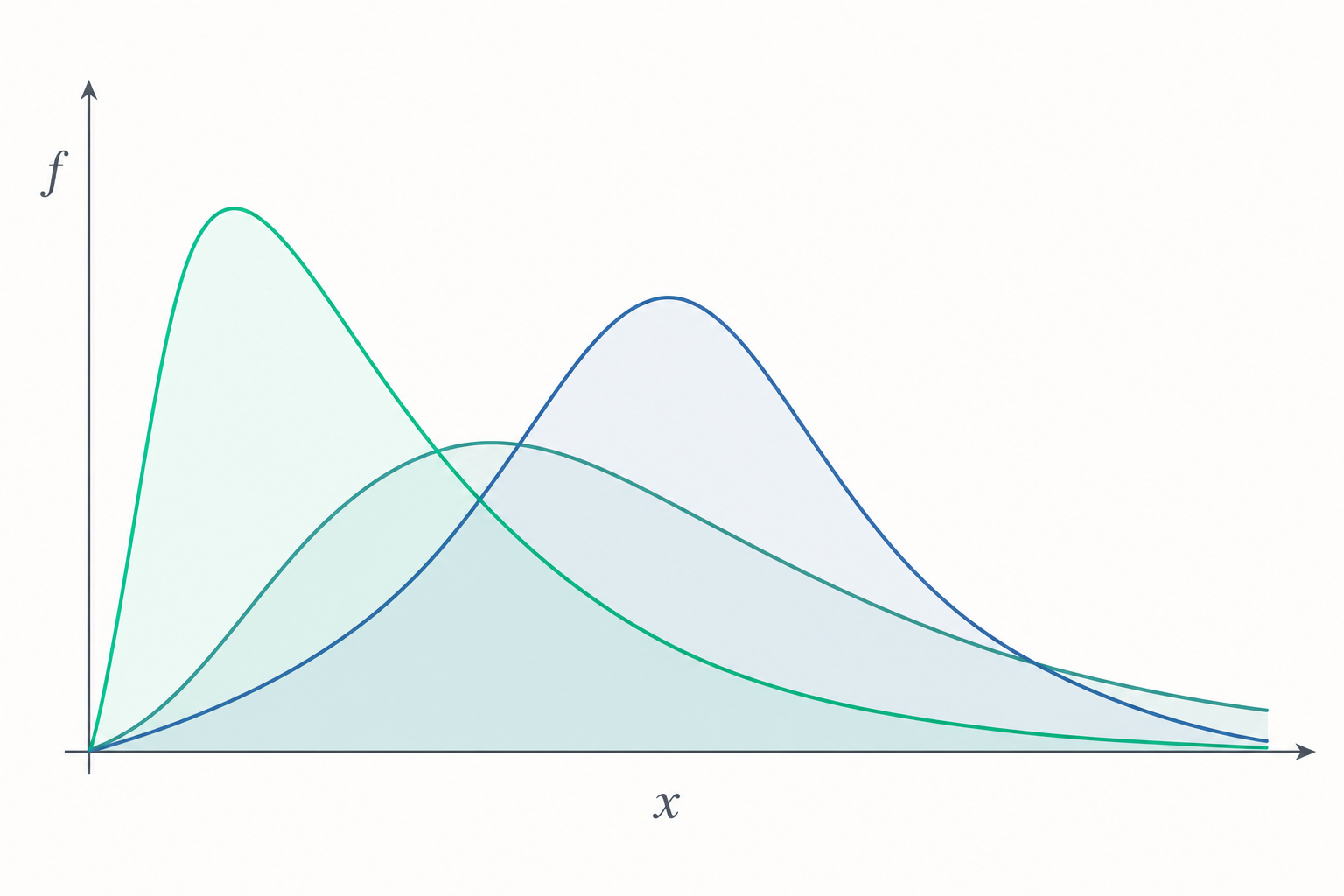
卡方分布:標準常態的平方和
設 $Z_1, \dots, Z_k$ 為獨立同分布的標準常態變數 $Z_i \sim N(0,1)$,則
$$Q = \sum_{i=1}^{k} Z_i^2 \sim \chi^2_{k}$$
其自由度為 $k$。其機率密度函數為
$$f(x;k) = \frac{1}{2^{k/2}\,\Gamma(k/2)}\, x^{k/2-1} e^{-x/2}, \quad x>0,$$
這正是形狀參數 $k/2$、尺度參數 $2$ 的 Gamma 分布。可由動差生成函數證明可加性:因 $M_{Z^2}(t) = (1-2t)^{-1/2}$,故 $M_Q(t) = (1-2t)^{-k/2}$,由此立即得 $E[Q]=k$、$\mathrm{Var}(Q)=2k$,且兩個獨立卡方變數相加,自由度直接相加。
統計推論中最關鍵的結果是樣本變異數的分布。給定 $X_1,\dots,X_n \sim N(\mu,\sigma^2)$,樣本變異數 $S^2 = \frac{1}{n-1}\sum (X_i-\bar X)^2$ 滿足
$$\frac{(n-1)S^2}{\sigma^2} \sim \chi^2_{n-1}.$$
自由度為何是 $n-1$ 而非 $n$?因為偏差 $X_i - \bar X$ 受到一條線性約束 $\sum(X_i-\bar X)=0$,少了一個自由維度。更深的根據是 Cochran 定理與 Fisher 的幾何論證:把 $n$ 維常態向量正交分解後,$\bar X$ 落在「全 1 方向」的一維子空間,而離差向量落在其 $n-1$ 維正交補空間,兩部分相互獨立。這個 $\bar X \perp S^2$ 的獨立性是常態分布獨有的性質,也是 t 分布得以成立的前提。
t 分布:未知變異數下的標準化
當母體變異數 $\sigma^2$ 已知時,標準化平均 $\frac{\bar X - \mu}{\sigma/\sqrt n}$ 服從 $N(0,1)$。但實務上 $\sigma$ 幾乎總是未知,只能用 $S$ 替代。代換後的統計量不再是常態,而是 William Gosset(筆名 Student)於 1908 年導出的 t 分布。
形式定義為:若 $Z \sim N(0,1)$ 與 $V \sim \chi^2_{\nu}$ 互相獨立,則
$$T = \frac{Z}{\sqrt{V/\nu}} \sim t_{\nu}.$$
把上式套用到單樣本:令 $Z = \frac{\bar X - \mu}{\sigma/\sqrt n}$,$V = \frac{(n-1)S^2}{\sigma^2}$,於是
$$T = \frac{\bar X - \mu}{S/\sqrt n} = \frac{Z}{\sqrt{V/(n-1)}} \sim t_{n-1}.$$
注意 $\sigma$ 在分子分母同時消去——這正是 t 統計量的精妙之處:即使不知道 $\sigma$,分布仍完全確定。其密度函數為
$$f(t;\nu) = \frac{\Gamma\!\left(\frac{\nu+1}{2}\right)}{\sqrt{\nu\pi}\,\Gamma\!\left(\frac{\nu}{2}\right)} \left(1+\frac{t^2}{\nu}\right)^{-\frac{\nu+1}{2}}.$$
t 分布對稱於 0,但比常態更厚尾,反映了「以 $S$ 估計 $\sigma$ 帶來的額外不確定性」。當 $\nu \to \infty$,由 $\left(1+\frac{t^2}{\nu}\right)^{-\nu/2} \to e^{-t^2/2}$,t 分布收斂至標準常態。其變異數為 $\frac{\nu}{\nu-2}$(須 $\nu>2$),確實大於 1,量化了厚尾程度。
F 分布:兩個卡方的比值
F 分布度量兩個變異數估計的比值。若 $U \sim \chi^2_{d_1}$ 與 $V \sim \chi^2_{d_2}$ 互相獨立,則
$$F = \frac{U/d_1}{V/d_2} \sim F_{d_1,d_2}.$$
它有兩個自由度,分子 $d_1$、分母 $d_2$,且不對稱、右偏。兩個關係值得記住:其一,$t_\nu^2 = F_{1,\nu}$——把 t 統計量平方就得到分子自由度為 1 的 F,這也是為何雙尾 t 檢定與單因子 F 檢定在兩組時等價。其二,倒數對稱性 $F_{d_1,d_2} = 1/F_{d_2,d_1}$(在分位數意義上),用於查表時上下尾互換。
F 分布是變異數分析(ANOVA)與迴歸整體顯著性檢定的核心。在單因子 ANOVA 中,組間均方 $MS_B$ 與組內均方 $MS_W$ 各自是某個卡方除以自由度,在虛無假設(各組均值相等)下兩者都無偏估計 $\sigma^2$,因此
$$F = \frac{MS_B}{MS_W} \sim F_{k-1,\, N-k},$$
當組間變異顯著大於組內變異時 $F$ 偏大,據此拒絕虛無假設。
定量小範例:F 檢定兩變異數是否相等
假設甲班 $n_1=8$ 位學生考試成績的樣本變異數 $S_1^2 = 42.0$,乙班 $n_2=6$ 位的 $S_2^2 = 12.0$,欲在 $\alpha=0.05$ 下檢定兩班變異數是否相等(雙尾)。
步驟一:兩個卡方統計量 $\frac{(n_i-1)S_i^2}{\sigma_i^2} \sim \chi^2_{n_i-1}$。在虛無假設 $\sigma_1^2 = \sigma_2^2$ 下,比值
$$F = \frac{S_1^2}{S_2^2} \sim F_{n_1-1,\, n_2-1} = F_{7,5}.$$
步驟二:計算檢定統計量
$$F = \frac{42.0}{12.0} = 3.5.$$
步驟三:查臨界值。雙尾 $\alpha=0.05$ 取上尾 $0.025$,$F_{0.025,\,7,5} \approx 6.85$。因 $3.5 < 6.85$,落在接受域。
步驟四:下尾臨界值 $F_{0.975,7,5} = 1/F_{0.025,5,7} \approx 1/5.29 \approx 0.189$。由於 $0.189 < 3.5 < 6.85$,不拒絕虛無假設,沒有足夠證據顯示兩班變異數不同。
要特別提醒:傳統 F 檢定對常態假設極度敏感,若資料偏離常態,結論可能完全失效——這時應改用 Levene 或 Brown–Forsythe 檢定。
統計素養:別誤讀 p 值與信賴區間
這三個分布常被用來算出 p 值與信賴區間,但兩者都極易被誤解。p 值是「假設虛無為真時,觀察到至少這麼極端統計量的機率」,不是「虛無為真的機率」,更不是效果大小。一個 $p=0.04$ 的結果在大樣本下可能對應微不足道的實質差異。95% 信賴區間的正確詮釋是「在重複抽樣的長期意義下,這類區間有 95% 會涵蓋真值」,而非「真值有 95% 機率落在這個特定區間」——真值是固定常數,隨機的是區間本身。此外,F 檢定顯示組間差異顯著,也僅意味著「存在差異」,並不告訴你是哪一組、更不等於因果。相關與顯著從來都不是因果的同義詞。
深入探討(研究所視角)
從更高的視角看,卡方、t、F 都只是常態理論下的「精確抽樣分布」(exact distribution),其優雅來自常態母體的封閉性質。一旦離開常態,這些精確結果就要讓位給漸近理論。中央極限定理保證 $\sqrt n(\bar X - \mu) \xrightarrow{d} N(0,\sigma^2)$,而由 Slutsky 定理,以一致估計量 $S$ 替換 $\sigma$ 不改變極限分布,故 t 統計量在 $n\to\infty$ 時漸近標準常態——這解釋了為何大樣本下 t 與 z 檢定幾乎無異。卡方分布的漸近角色更為深刻:在最大概似估計(MLE)框架下,Wilks 定理指出對數概似比統計量 $-2\log\Lambda$ 在虛無假設下漸近服從 $\chi^2$,自由度等於受限參數的個數;Wald 檢定與 Score(Lagrange multiplier)檢定亦同。三者的共通根源是 MLE 的漸近常態性 $\hat\theta \approx N(\theta, I(\theta)^{-1})$,其中 $I(\theta)$ 為 Fisher 資訊量。二次型 $(\hat\theta-\theta)^\top I(\theta)(\hat\theta-\theta)$ 自然落入卡方分布——這把「平方和」的幾何直覺推廣到任意參數模型。
動差法(Method of Moments)提供另一條估計路徑:以樣本動差匹配理論動差解方程,雖然通常不如 MLE 有效率,卻在計算上更穩健,且常作為 MLE 數值優化的初始值。兩者在指數族下往往一致。
貝氏對應則重新詮釋了這些分布。在常態模型中,若對 $\sigma^2$ 採用共軛的逆 Gamma 先驗、對 $\mu$ 採常態先驗,則 $\mu$ 的後驗邊際分布恰為 t 分布——這意味著古典的 t 區間在「無資訊先驗」極限下與貝氏可信區間數值重合,但詮釋截然不同:貝氏直接給出「參數落在區間的機率」,正是頻率派信賴區間被誤解成的那個意思。卡方與逆 Gamma 的對偶、F 分布與 Beta 分布的關係($\frac{d_1 F}{d_1 F + d_2} \sim \mathrm{Beta}(d_1/2, d_2/2)$),都顯示這些「抽樣分布」在貝氏框架下化身為共軛後驗的成員。
與機器學習與因果推論的連結同樣值得注意。正則化迴歸(Ridge)等價於對係數施加常態先驗,其有效自由度需以跡運算重新定義,傳統 F 檢定的自由度不再適用。在因果推論中,工具變數的「弱工具」問題正是透過第一階段迴歸的 F 統計量診斷(經驗法則 $F>10$),而異質處理效果的檢定、置換檢定(permutation test)則繞過常態假設,直接從資料重抽建構經驗分布。可以說,卡方、t、F 是參數統計的三塊基石,而現代統計正不斷在「放鬆常態假設」與「保留可解釋推論」之間尋找新的平衡。理解這三個分布的精確構造,正是看懂這場演進的起點。