
試題反應理論(IRT)進階:多元計分、多維能力與跨年連結
當反應不再非對即錯、能力不只一維,IRT 如何用 GRM/GPCM、MIRT 與尺度連結,把測量推向大規模跨年代評量?
當題目不再是「對或錯」:李克特量表與部分給分怎麼進 IRT?
入門篇把試題反應理論(Item Response Theory, IRT)建立在「答對/答錯」的二元反應上:一條 S 形的試題特徵曲線(item characteristic curve, ICC),三個參數 $a$、$b$、$c$,再加上局部獨立與單維度假設,整套概似推論就站穩了。但真實世界的測量很少只有兩種結局。一份問卷的李克特量表(Likert scale)有「非常不同意」到「非常同意」五級;一道申論題可以拿 0、1、2、3 分的部分給分(partial credit);一個認知作業的反應同時帶著「對不對」與「花多久」兩條訊息。這些反應都是有序多元(ordered polytomous) 的,二元 IRT 直接套不上去。
於是進階的 IRT 要回答三個入門篇刻意略過的問題:第一,當每題有 $K$ 個有序等級時,ICC 要怎麼推廣?第二,當潛在能力不只一維(讀寫、計算、空間各自獨立)時,模型如何擴張?第三,不同年度、不同題本估出來的 $\theta$ 與 $b$,憑什麼放在同一條尺度上比較?這三問分別對應多元計分模型(polytomous models)、多維 IRT(multidimensional IRT, MIRT) 與尺度連結(scale linking / equating),也正是把 IRT 從「一次小考的分析工具」推向「跨年代、大規模測驗系統」的關鍵機制。
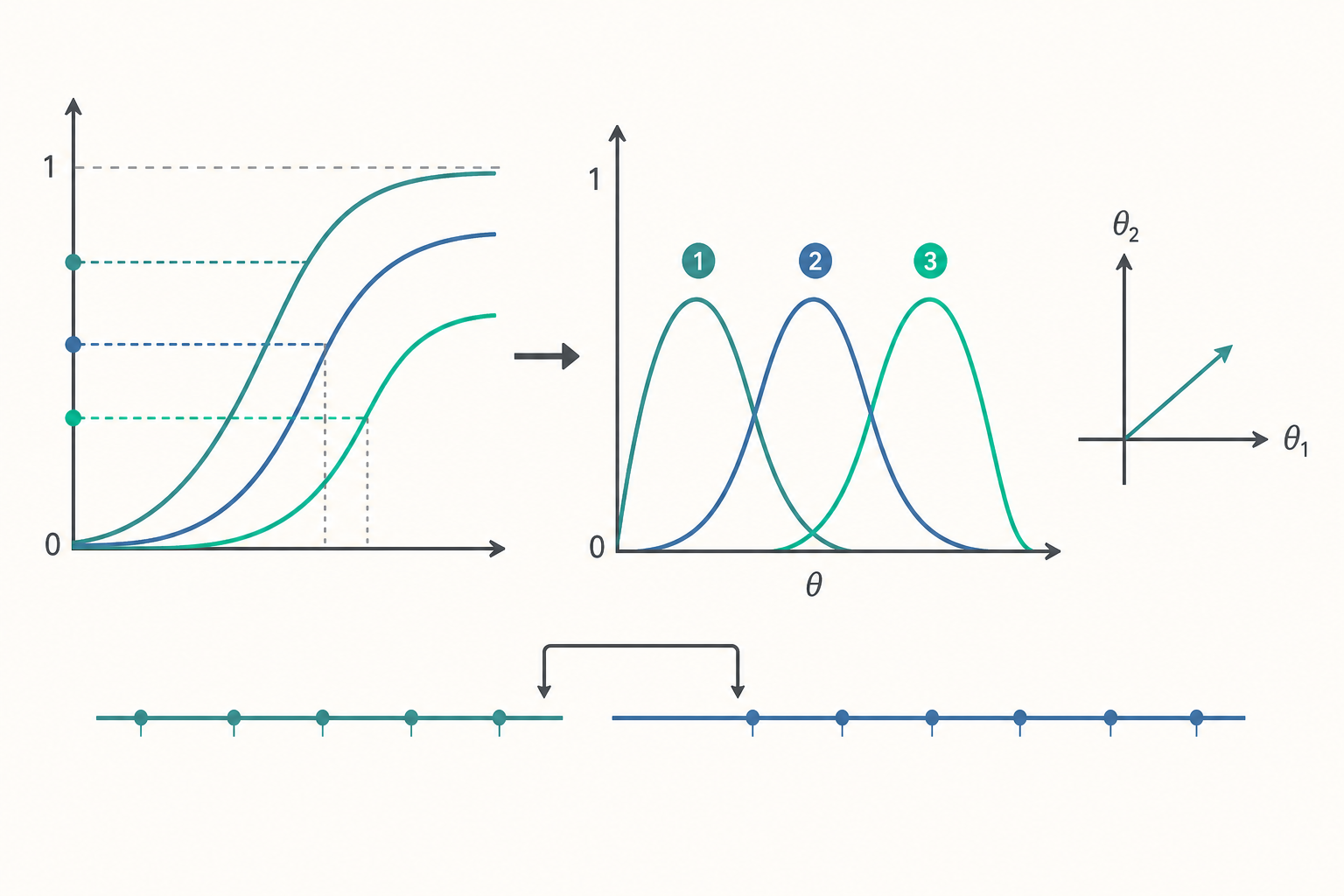
從二元到有序多元:累積機率的 GRM
最直接的推廣思路是 Samejima 的等級反應模型(graded response model, GRM),它的核心是把「拿到第 $k$ 級以上」當成一連串二元事件。假設第 $i$ 題有 $K$ 個有序等級($0,1,\dots,K-1$),我們為每個「邊界(threshold)」$b_{ik}$ 定義一條累積機率曲線:
$$P_{ik}^{*}(\theta) = P(\text{反應} \ge k \mid \theta) = \frac{1}{1 + e^{-a_i(\theta - b_{ik})}}, \quad k = 1, \dots, K-1.$$
注意這就是一條 2PL 曲線,只是「答對」被換成「達到第 $k$ 級或以上」。鑑別度 $a_i$ 在同一題的各邊界共用(同一題的各級「靈敏度」一致),而 $b_{i1} < b_{i2} < \dots < b_{i,K-1}$ 是一組遞增的邊界難度——要爬到越高的等級,需要越高的能力。
恰好落在第 $k$ 級的機率,就是相鄰兩條累積曲線相減:
$$P_{ik}(\theta) = P_{ik}^{*}(\theta) - P_{i,k+1}^{*}(\theta),$$
其中規定 $P_{i0}^{*}(\theta) = 1$(達到 0 級以上必然成立)、$P_{iK}^{*}(\theta) = 0$(沒有比最高級更高的)。這樣每一級都對應一條鐘形的類別反應曲線(category response curve, CRC):能力很低時最可能落在最低級,能力升高時機率峰值依序往高級移動。GRM 屬於「間接(difference)模型」——先算累積機率,再相減得各級機率。
相鄰類別的另一條路:PCM 與 GPCM
另一條主流是 Masters 的部分給分模型(partial credit model, PCM) 與其推廣 GPCM(generalized PCM)。它不走累積機率,而是直接建模「相鄰兩級之間」的轉換難度——這類稱為「直接(divide-by-total)模型」。GPCM 的每一級機率為:
$$P_{ik}(\theta) = \frac{\exp\!\left[\sum_{m=0}^{k} a_i(\theta - \delta_{im})\right]}{\sum_{r=0}^{K-1}\exp\!\left[\sum_{m=0}^{r} a_i(\theta - \delta_{im})\right]},$$
其中 $\delta_{im}$ 是第 $m$ 個步驟難度(step difficulty),代表從第 $m-1$ 級跨到第 $m$ 級所需的能力門檻(規定 $\sum_{m=0}^{0}$ 那一項為 0)。當所有題的 $a_i$ 被固定為相同常數時,GPCM 退化成 PCM,後者屬於 Rasch 家族,享有充分統計量(sufficient statistic)與題目能力分離估計的好性質。
GRM 與 GPCM 的關鍵差異在於對「邊界」的詮釋:GRM 的 $b_{ik}$ 是累積邊界,必然遞增;GPCM 的步驟難度 $\delta_{im}$ 是相鄰步驟門檻,不必然遞增——當某一中間等級很少有人選(反應分布凹陷),會出現「步驟反轉(disordered thresholds)」,這是診斷量表選項是否設計得當的重要訊號。換句話說,步驟反轉不是模型壞了,而是模型在告訴你:這個中間選項可能多餘,或受試者根本分不清它與鄰級的差別。
多元計分的試題資訊:訊息藏在哪一級
入門篇給過二元題的資訊函數 $I_i(\theta) = a_i^2 P(1-P)$。多元計分的資訊函數是各級的加權變異形式。對 GPCM,可寫成:
$$I_i(\theta) = a_i^2 \left[\sum_{k=0}^{K-1} k^2 P_{ik}(\theta) - \left(\sum_{k=0}^{K-1} k\, P_{ik}(\theta)\right)^2\right] = a_i^2 \cdot \mathrm{Var}(k \mid \theta).$$
這個式子很有啟發性:括號裡正是「在能力 $\theta$ 下,反應等級 $k$ 的條件變異數」。資訊量在「各級機率勢均力敵、最難預測會落在哪一級」的能力區間最大。相較二元題只有一個資訊峰,多元計分題往往在較寬的能力範圍都維持不錯的資訊——這正是李克特量表能用較少題數穩定測量態度構念的數理原因。一道五級題在直覺上「抵」好幾道是非題,背後就是它的資訊函數在一段連續區間都不塌下去。
動手算一下:三級部分給分題的各級機率
假設一道三級部分給分題(等級 0、1、2),用 GPCM,估得 $a_i = 1.0$,兩個步驟難度 $\delta_{i1} = -0.5$、$\delta_{i2} = 0.8$(規定 $\delta_{i0}=0$)。我們算能力 $\theta = 0$ 的學生落在各級的機率。
先算每一級的指數項(exponent),令 $z_k = \sum_{m=0}^{k} a_i(\theta - \delta_{im})$:
- 第 0 級:$z_0 = a_i(\theta - \delta_{i0}) = 1.0\times(0 - 0) = 0$。
- 第 1 級:$z_1 = z_0 + a_i(\theta - \delta_{i1}) = 0 + 1.0\times(0 - (-0.5)) = 0.5$。
- 第 2 級:$z_2 = z_1 + a_i(\theta - \delta_{i2}) = 0.5 + 1.0\times(0 - 0.8) = -0.3$。
取指數並求和當作分母:
$$e^{z_0} = 1.000,\quad e^{z_1} = e^{0.5} \approx 1.649,\quad e^{z_2} = e^{-0.3} \approx 0.741.$$
$$\text{分母} = 1.000 + 1.649 + 0.741 = 3.390.$$
於是各級機率:
$$P_{i0}(0) = \frac{1.000}{3.390} \approx 0.295,\quad P_{i1}(0) = \frac{1.649}{3.390} \approx 0.486,\quad P_{i2}(0) = \frac{0.741}{3.390} \approx 0.219.$$
能力中等的學生最可能拿到「部分給分」的第 1 級(機率約 0.49),合乎直覺。接著算這題在 $\theta=0$ 的資訊。先求期望等級與其平方期望:
$$E[k] = 0\times0.295 + 1\times0.486 + 2\times0.219 = 0.924,$$ $$E[k^2] = 0\times0.295 + 1\times0.486 + 4\times0.219 = 1.362.$$ $$\mathrm{Var}(k) = 1.362 - 0.924^2 = 1.362 - 0.854 = 0.508.$$
$$I_i(0) = a_i^2 \cdot \mathrm{Var}(k) = 1.0^2 \times 0.508 = 0.508.$$
對照一道難度恰為 0 的二元題,其資訊上限是 $a^2 \times 0.25 = 0.25$(當 $a=1$)。這道三級題在 $\theta=0$ 提供約 0.51 的資訊,超過二元題峰值的兩倍——這量化地說明了「為什麼多級題單位題數攜帶更多訊息」。
不只一維:MIRT 把能力變成向量
入門篇假設單維度(unidimensionality):所有題目相關都由單一 $\theta$ 解釋。但一份「數學素養」測驗可能同時牽涉「計算流暢」與「閱讀理解」;一個跨領域評量更是天生多維。多維 IRT(MIRT) 把能力升級為向量 $\boldsymbol{\theta} = (\theta_1, \dots, \theta_D)$,題目鑑別度也升級為向量 $\boldsymbol{a}_i$。補償型(compensatory)二參數 MIRT 的答對機率為:
$$P_i(\boldsymbol{\theta}) = \frac{1}{1 + \exp\!\left[-\left(\boldsymbol{a}_i^{\top}\boldsymbol{\theta} + d_i\right)\right]},$$
其中 $d_i$ 是截距(與整體難度相關),$\boldsymbol{a}_i$ 的各分量代表這題對各維能力的負荷(loading)。「補償型」意味著某一維能力低,可由另一維高來彌補——線性組合 $\boldsymbol{a}_i^{\top}\boldsymbol{\theta}$ 只看加總。與之對照的是非補償(partially compensatory)模型,把各維機率相乘,任一維短板都會拖垮整體答對機率,較貼近「兩種能力缺一不可」的題目(例如需先讀懂題意才能計算)。
MIRT 與因素分析(factor analysis)有深刻的數學連結:二元題的 MIRT 本質上是帶 probit/logit 連結的潛在變數因素模型,$\boldsymbol{a}_i$ 對應因素負荷、$d_i$ 對應截距。這也帶來與因素分析相同的旋轉不確定性(rotational indeterminacy):在沒有額外限制下,$\boldsymbol{\theta}$ 的座標軸可任意正交(甚至斜交)旋轉而不改變概似,因此 MIRT 的維度詮釋必須靠理論限制(如指定某些 $a$ 為 0 的簡單結構)或事後旋轉。實務上常先用平行分析或探索性 MIRT 決定維度數,再轉成驗證性結構。一個常被忽略的事實是:「多維資料硬套單維模型」會讓估出的單維 $\theta$ 變成各維的某種加權混合,DIF 與連結都可能因此系統性偏誤——這是把 IRT 用在跨領域大型評量時最常見的隱患。
尺度連結:憑什麼跨年度比較?
IRT 的能力尺度 $\theta$ 有一個與生俱來的不確定性:模型對 $\theta$ 與題目參數同時做線性變換 $\theta \to \alpha\theta + \beta$、$b \to \alpha b + \beta$、$a \to a/\alpha$ 時,答對機率完全不變(indeterminacy of scale)。為了定錨,我們通常硬性規定母體 $\theta \sim \mathcal{N}(0,1)$。但問題來了:A 年的考生在他們自己的卷子上被標準化成平均 0,B 年的考生在另一份卷子上也被標準化成平均 0——這兩個「0」根本不是同一個能力水準。要跨年度比較,必須把兩套估計連結(link) 到共同尺度。
最常見的設計是共同題錨定(anchor items / common-item design):兩份題本共享一批錨題。錨題的真實難度不該因為換了年度而改變(這正是 IRT 參數不變性的承諾),於是我們找出線性變換 $\theta_B^* = \alpha\theta_B + \beta$,使 B 年估出的錨題參數在變換後對齊 A 年。求 $(\alpha, \beta)$ 的經典方法有平均數—平均數法(mean/mean)、平均數—標準差法(mean/sigma),以及更穩健的特徵曲線法(characteristic curve methods) ——Haebara 法與 Stocking–Lord 法。後兩者不只對齊參數的矩,而是最小化「兩套參數所畫出的試題(或測驗)特徵曲線」之間的差距。以 Stocking–Lord 為例,目標函數是錨題集上、對能力分布加權的測驗特徵曲線平方差:
$$\mathrm{SL}(\alpha,\beta) = \sum_{q} W(\theta_q)\left[\sum_{i \in \text{anchor}} P_i(\theta_q; \hat{a}_i^A, \hat{b}_i^A) - P_i\!\left(\theta_q; \tfrac{\hat{a}_i^B}{\alpha}, \alpha\hat{b}_i^B+\beta\right)\right]^2,$$
對 $(\alpha,\beta)$ 求極小。連結做好後,才談得上等化(equating)——把分數轉成可互換的報告分數。值得釐清的是:linking 是把參數放到共同尺度,equating 是更嚴格地讓「不同題本的同一報告分數代表同等能力,可互換使用」,後者對題本平行性的要求更高。沒有可靠的共同題錨定與連結,所謂「今年比去年進步 5 分」很可能只是兩把不同的尺在各說各話。
重點回顧
- 多元計分有兩大家族:GRM 走累積機率相減(difference 模型,邊界 $b_{ik}$ 必遞增),GPCM/PCM 走相鄰類別轉換(divide-by-total 模型,步驟難度 $\delta_{im}$ 可反轉)。步驟反轉是診斷量表選項冗餘的訊號,不是錯誤。
- 多級題資訊更寬廣:$I_i(\theta)=a_i^2\,\mathrm{Var}(k\mid\theta)$,一道好的李克特或部分給分題,在較寬的能力區間都維持高資訊,等效於數道二元題。
- MIRT 把能力變成向量:補償型用 $\boldsymbol{a}_i^{\top}\boldsymbol{\theta}+d_i$(短板可被彌補),非補償型相乘(缺一不可);它與因素分析同源,並繼承旋轉不確定性,維度詮釋需理論限制。
- $\theta$ 尺度本質上可線性變換:跨年度、跨題本要先做尺度連結(mean/sigma、Haebara、Stocking–Lord),再談等化,否則分數不可比。
- 共同題錨定是連結的骨幹:靠參數不變性把不同題本對齊到同一尺度;錨題品質不佳或本身有 DIF,整套跨年比較都會失真。
深入探討(研究所視角)
多元模型的估計與可辨識性。 多元 IRT 同樣以邊際最大概似(MML)搭配 EM 求解,但多維情況下 E 步的後驗期望需要在 $D$ 維潛在空間積分,Gauss–Hermite 求積的節點數隨維度指數成長(curse of dimensionality):$Q$ 個一維節點在 $D$ 維變成 $Q^D$ 個。實務上高維問題改用 adaptive quadrature、蒙地卡羅 EM(MCEM),或近年流行的 Metropolis–Hastings Robbins–Monro(MH-RM) 演算法與全貝氏 MCMC(如 Stan / JAGS)。可辨識性(identifiability)在多維下尤其棘手:除了前述旋轉不確定性,還需固定潛在變數的尺度(變異數設為 1)與部分負荷以避免標籤交換(label switching)。驗證性 MIRT 透過理論驅動的零負荷模式(item-by-factor 指派)來達成簡單結構與可辨識。
Rasch 的特殊地位與「specific objectivity」。 GPCM 退化為 PCM、2PL 退化為 1PL 時,模型進入 Rasch 家族,獲得一項其他 IRT 模型沒有的性質:充分統計量分離。在 Rasch 模型中,受試者的總分是其能力 $\theta$ 的充分統計量,題目的邊際次數是難度 $b$ 的充分統計量,因此可用條件最大概似(conditional maximum likelihood, CML) 在「給定總分」的條件下估計題目參數,使題目校準完全不依賴 $\theta$ 的母體分布假設——這是 Rasch 學派強調的「特定客觀性(specific objectivity)」:兩道題的難度比較不該因為拿哪一群人、哪一個能力區段去比而改變。代價是 Rasch 強制所有題等鑑別度,當資料的鑑別度確實異質時會犧牲適配度。Rasch 與 2PL/3PL 之爭,本質是「測量理論的公理優先」對上「資料適配優先」的方法論立場差異,沒有單一正解。
電腦化適性測驗(CAT)的工程現實。 入門篇指出資訊函數 $\mathrm{SE}(\hat\theta)=1/\sqrt{I(\theta)}$ 是 CAT 選題的支點:每答一題更新 $\hat\theta$,再挑當前 $\hat\theta$ 處資訊最大的題。但純「最大資訊」選題在實務上會出兩個問題。其一是題目曝光(item exposure):高鑑別度、難度適中的「好題」會被反覆選中,少數題目承擔過半施測量,既威脅題庫安全(被洩題)又浪費題庫。對策是 Sympson–Hetter 曝光控制(為每題設一個機率閘門,讓它以受控頻率才真正被施測)、$a$-stratified 分層選題(先用低鑑別度題粗估、再用高鑑別度題精測),或對選題目標函數加入隨機化。其二是內容平衡(content balancing):考科各子領域的題數比例必須符合測驗藍圖,不能因為某子領域的題剛好資訊高就全選它,這催生了帶約束的選題法與「shadow test」做法——每一步都先解一個整數規劃,組出一份滿足所有內容、曝光、長度約束且資訊最大的「影子完整測驗」,再從中取下一題。此外,貝氏選題準則(如最小化後驗變異的 MEPV、或 Kullback–Leibler 資訊)在估計初期 $\hat\theta$ 還很不準時,比 Fisher 資訊更穩健,因為 Fisher 資訊是「在當前點估計處」的局部量,早期容易把測驗導向錯誤難度。
回到 Uedu 的測量治理。 Uedu 的 quiz 與 UCG 認知測驗若要從「單次小考分析」走向「跨學期、跨課程的能力追蹤」,多元計分、MIRT 與尺度連結三者缺一不可:申論與評分規準(rubric)題用 GRM/GPCM 才能誠實利用部分給分的訊息;跨領域素養評量需要 MIRT 才不會把多維能力壓扁成偏誤的單維分數;而要主張「同一學生這學期比上學期成長」,就必須以共同錨題把不同學期的題本連結到同一尺度——否則所有縱貫(longitudinal)比較都建立在浮動的原點上。更進一步,認知測驗常同時記錄正確率與反應時間,這把問題推向反應時間聯合建模(如 van der Linden 的階層式速度—正確性模型,把作答速度 $\tau$ 與能力 $\theta$ 視為相關的潛在向量),讓「又快又準」與「慢而準」在計量上被區分開來。需要再次強調的是,這些進階模型全都是「假設驅動」的:多元模型有等鑑別度或邊界遞增的內隱假設、MIRT 的維度結構是研究者指定的、連結倚賴錨題的參數不變性。模型診斷(適配度檢定、殘差分析、錨題穩定性檢核、DIF 篩查)應與估計同等被重視——IRT 的力量來自它的假設,而它的風險也來自同一批假設。