
貝氏更新:先驗、概似與後驗的嚴謹推導
從比例式到共軛先驗,再看 Bernstein–von Mises 如何連接貝氏與頻率派
從一個信念到下一個信念:貝氏更新的核心
當我們手上有一個對未知參數的初步看法,又觀察到新資料時,理性的做法不是丟掉舊看法、也不是無視新證據,而是把兩者「按比例融合」。貝氏更新正是把這個直覺寫成嚴格機率運算的機器:它告訴我們先驗(prior)如何在概似(likelihood)的牽引下,演化為後驗(posterior)。
設未知參數為 $\theta$,觀察到的資料為 $D$。貝氏定理寫成
$$p(\theta \mid D) = \frac{p(D \mid \theta)\, p(\theta)}{p(D)}, \qquad p(D) = \int p(D \mid \theta)\, p(\theta)\, d\theta.$$
這裡 $p(\theta)$ 是先驗,$p(D \mid \theta)$ 視為 $\theta$ 的函數時稱為概似 $L(\theta)$,$p(\theta \mid D)$ 是後驗,分母 $p(D)$ 稱為邊際概似(marginal likelihood)或證據(evidence)。由於 $p(D)$ 不依賴 $\theta$,更新的核心可以濃縮成一句口訣:
$$\text{後驗} \propto \text{概似} \times \text{先驗}.$$
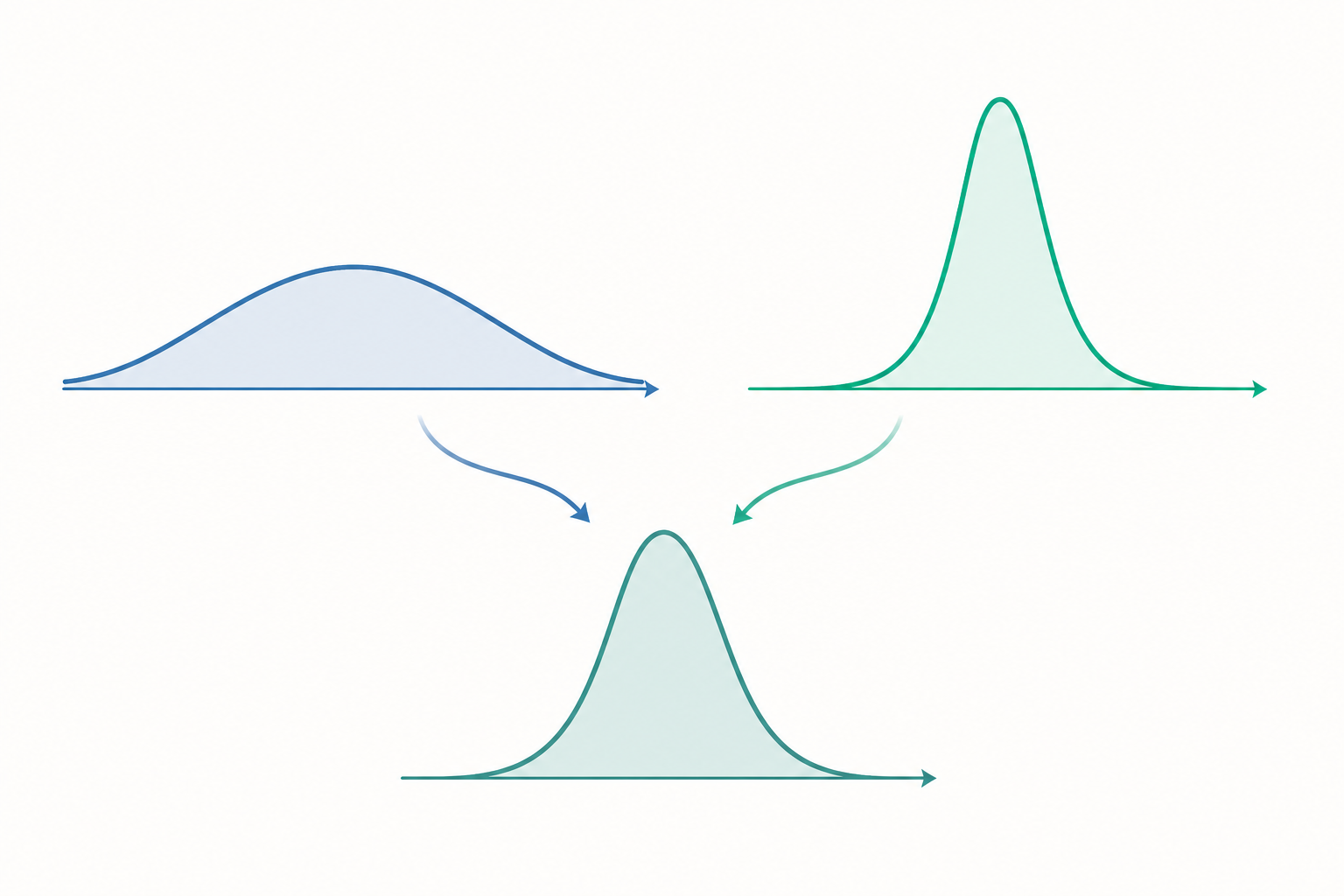
為什麼分母可以暫時忽略——但不能永遠忽略
把後驗寫成比例式之所以合法,是因為 $p(\theta \mid D)$ 必須在 $\theta$ 上積分為 1。換言之,分母 $p(D)$ 純粹扮演正規化常數(normalizing constant)的角色:它把「概似乘先驗」這個未必積分為 1 的函數,縮放成合格的機率密度。
但 $p(D)$ 並非毫無資訊。在模型比較中,
$$\text{Bayes factor} = \frac{p(D \mid M_1)}{p(D \mid M_2)}$$
正是兩個模型各自邊際概似的比值,它自動懲罰過度複雜的模型(Occam 剃刀效應內建於積分之中)。所以「忽略分母」只在固定模型、估計參數時成立;一旦要在模型之間抉擇,分母就是主角。
序貫更新:今天的後驗是明天的先驗
貝氏更新最迷人的性質是它的可遞迴性。若資料 $D = \{x_1, \dots, x_n\}$ 在給定 $\theta$ 下條件獨立,則
$$p(\theta \mid x_1, \dots, x_n) \propto p(\theta) \prod_{i=1}^{n} p(x_i \mid \theta).$$
這意味著我們可以一筆一筆地吸收資料:
$$p(\theta \mid x_1, x_2) \propto p(x_2 \mid \theta)\, \underbrace{p(\theta \mid x_1)}_{\text{昨日後驗作為今日先驗}}.$$
只要最終乘積相同,分批更新與一次更新得到的後驗完全一致。這正是線上學習(online learning)與序貫推論的理論基礎。
共軛先驗:讓更新有閉式解
一般而言分母的積分難以解析,但若選擇與概似「共軛」的先驗,後驗會落在與先驗相同的分布族,只需更新參數即可。最經典的是 Beta–Binomial 模型。
設成功機率為 $\theta$,先驗取 $\theta \sim \text{Beta}(\alpha, \beta)$,密度為
$$p(\theta) = \frac{\theta^{\alpha-1}(1-\theta)^{\beta-1}}{B(\alpha, \beta)}.$$
觀察 $n$ 次試驗中 $k$ 次成功,概似為 $L(\theta) \propto \theta^{k}(1-\theta)^{n-k}$。兩者相乘:
$$p(\theta \mid D) \propto \theta^{\alpha+k-1}(1-\theta)^{\beta+n-k-1},$$
恰好又是一個 Beta 分布:
$$\theta \mid D \sim \text{Beta}(\alpha + k,\ \beta + n - k).$$
更新規則漂亮得驚人:成功數加進 $\alpha$、失敗數加進 $\beta$。這也讓 $\alpha, \beta$ 獲得「虛擬先驗樣本數」的直觀解讀。
定量小範例:硬幣公正嗎
假設我們懷疑一枚硬幣,先驗採用較弱資訊的 $\text{Beta}(2, 2)$(偏好接近 $0.5$ 但不武斷)。實際投擲 $n = 10$ 次,得到 $k = 7$ 次正面。代入更新規則:
$$\theta \mid D \sim \text{Beta}(2 + 7,\ 2 + 3) = \text{Beta}(9, 5).$$
後驗的點估計可用後驗平均:
$$\mathbb{E}[\theta \mid D] = \frac{\alpha'}{\alpha' + \beta'} = \frac{9}{9 + 5} = \frac{9}{14} \approx 0.643.$$
注意它落在先驗平均 $0.5$ 與資料比例 $\hat\theta_{\text{MLE}} = 7/10 = 0.7$ 之間——後驗是先驗與資料的加權妥協。後驗變異數為
$$\operatorname{Var}[\theta \mid D] = \frac{\alpha' \beta'}{(\alpha'+\beta')^2 (\alpha'+\beta'+1)} = \frac{9 \times 5}{14^2 \times 15} = \frac{45}{2940} \approx 0.0153,$$
對應標準差約 $0.124$。後驗眾數(MAP 估計)為
$$\hat\theta_{\text{MAP}} = \frac{\alpha'-1}{\alpha'+\beta'-2} = \frac{8}{12} \approx 0.667.$$
若先驗改用無資訊的 $\text{Beta}(1,1)$(均勻分布),後驗變為 $\text{Beta}(8,4)$,後驗平均回到 $8/12 \approx 0.667$,更貼近資料。可見先驗的「強度」直接決定它在妥協中的話語權:資料越多,先驗影響越被稀釋。
統計素養提醒
後驗給出的是「在模型與先驗假設下,參數的機率信念」,而非客觀真理。$\text{Beta}(9,5)$ 的 $95\%$ 可信區間(credible interval)可直接解讀為「$\theta$ 有 $95\%$ 機率落在此區間」——這與頻率派信賴區間「重複抽樣下涵蓋率」的解讀截然不同,兩者不可混淆。同樣地,硬幣偏向正面是統計關聯,不能直接推論為某種物理因果;觀察到關聯仍需檢視機制與混淆因素。
深入探討(研究所視角)
把貝氏更新放進更大的推論版圖,會看到它與頻率派估計、漸近理論與現代機器學習的深層連結。
最大概似、動差法與貝氏的關係。 最大概似估計(MLE)$\hat\theta_{\text{MLE}} = \arg\max_\theta L(\theta)$ 在正則條件下具有一致性與漸近常態性:
$$\sqrt{n}\,(\hat\theta_{\text{MLE}} - \theta_0) \xrightarrow{d} \mathcal{N}\!\big(0,\ I(\theta_0)^{-1}\big),$$
其中 $I(\theta) = -\mathbb{E}\!\left[\frac{\partial^2 \log p(X\mid\theta)}{\partial \theta^2}\right]$ 為 Fisher 資訊,其倒數即 Cramér–Rao 下界。動差法(method of moments)則以樣本動差匹配理論動差求解,計算簡單但效率通常不如 MLE。貝氏的 MAP 估計可視為帶懲罰項的 MLE:$\hat\theta_{\text{MAP}} = \arg\max_\theta \big[\log L(\theta) + \log p(\theta)\big]$,當先驗趨於均勻時 MAP 收斂回 MLE。
Bernstein–von Mises 定理。 這是連接兩派的橋樑:在正則模型與固定真值 $\theta_0$ 下,當 $n \to \infty$,後驗分布漸近於以 MLE 為中心、變異數為 $I(\theta_0)^{-1}/n$ 的常態分布,且先驗的影響被洗去。形式上
$$p(\theta \mid D) \approx \mathcal{N}\!\big(\hat\theta_{\text{MLE}},\ [n I(\theta_0)]^{-1}\big).$$
其深刻含義是:大樣本下貝氏可信區間與頻率派信賴區間數值趨於一致,先驗的選擇僅在小樣本或高維時才舉足輕重。這也解釋了為何在資訊充足時,兩派常得到實務上相近的結論。
先驗的客觀化與正則化視角。 Jeffreys 先驗 $p(\theta) \propto \sqrt{\det I(\theta)}$ 在參數重新參數化下不變,是「無資訊先驗」的一種原則性選擇。從機器學習角度看,先驗即正則化:高斯先驗對應 L2(Ridge)懲罰、Laplace 先驗對應 L1(Lasso)懲罰,MAP 估計與正則化經驗風險最小化在數學上同構。這把貝氏推論與深度學習的權重衰減統一在同一框架下。
計算與前沿連結。 多數現實模型沒有共軛閉式解,需仰賴 MCMC(如 Hamiltonian Monte Carlo)或變分推論(variational inference)近似後驗,後者把推論轉化為最佳化問題,是貝氏深度學習與變分自編碼器(VAE)的核心。在因果推論中,貝氏框架可自然納入結構假設與先驗知識,對處理效果(treatment effect)的後驗分布做不確定性量化;但須謹記:再精緻的後驗也無法從純觀察資料憑空產生因果結論,識別性(identifiability)仰賴設計與假設,而非更新次數。貝氏更新給的是「在假設成立下信念如何隨證據演化」,假設本身的可信度仍須由科學論證與實驗設計來承擔。