
二因子變異數分析與交互作用:從平方和分解到效果調節
嚴謹推導正交分解、期望均方與 F 檢定,並延伸至混合模型、貝氏收縮與因果異質性
從「兩條主效果」到「斜率不平行」:交互作用的真正意義
當我們同時操弄兩個類別因子(例如「教學法」與「學生程度」),最容易犯的錯,是把兩個因子的效果當成彼此獨立、可以單純相加。二因子變異數分析(two-way ANOVA)的核心價值,恰恰在於它讓我們有能力檢驗「相加假設」是否成立——也就是是否存在交互作用(interaction)。直覺上,交互作用就是「一個因子的效果,會隨另一個因子的水準而改變」;幾何上,就是在因子水準均值圖上,兩條折線不平行。
設因子 $A$ 有 $a$ 個水準、因子 $B$ 有 $b$ 個水準,每個格子(cell)有 $n$ 個觀測值(平衡設計)。標準的可加效果模型寫成:
$$ Y_{ijk} = \mu + \alpha_i + \beta_j + (\alpha\beta)_{ij} + \varepsilon_{ijk}, \quad \varepsilon_{ijk}\overset{iid}{\sim}\mathcal{N}(0,\sigma^2) $$
其中 $i=1,\dots,a$、$j=1,\dots,b$、$k=1,\dots,n$。為了讓參數可辨識(identifiable),施加邊際約束:
$$ \sum_i \alpha_i = 0,\quad \sum_j \beta_j = 0,\quad \sum_i (\alpha\beta)_{ij}=0\ \forall j,\quad \sum_j (\alpha\beta)_{ij}=0\ \forall i. $$
主效果 $\alpha_i$、$\beta_j$ 描述各因子的邊際偏移,而 $(\alpha\beta)_{ij}$ 正是交互作用項:當且僅當所有 $(\alpha\beta)_{ij}=0$ 時,兩因子效果可加。
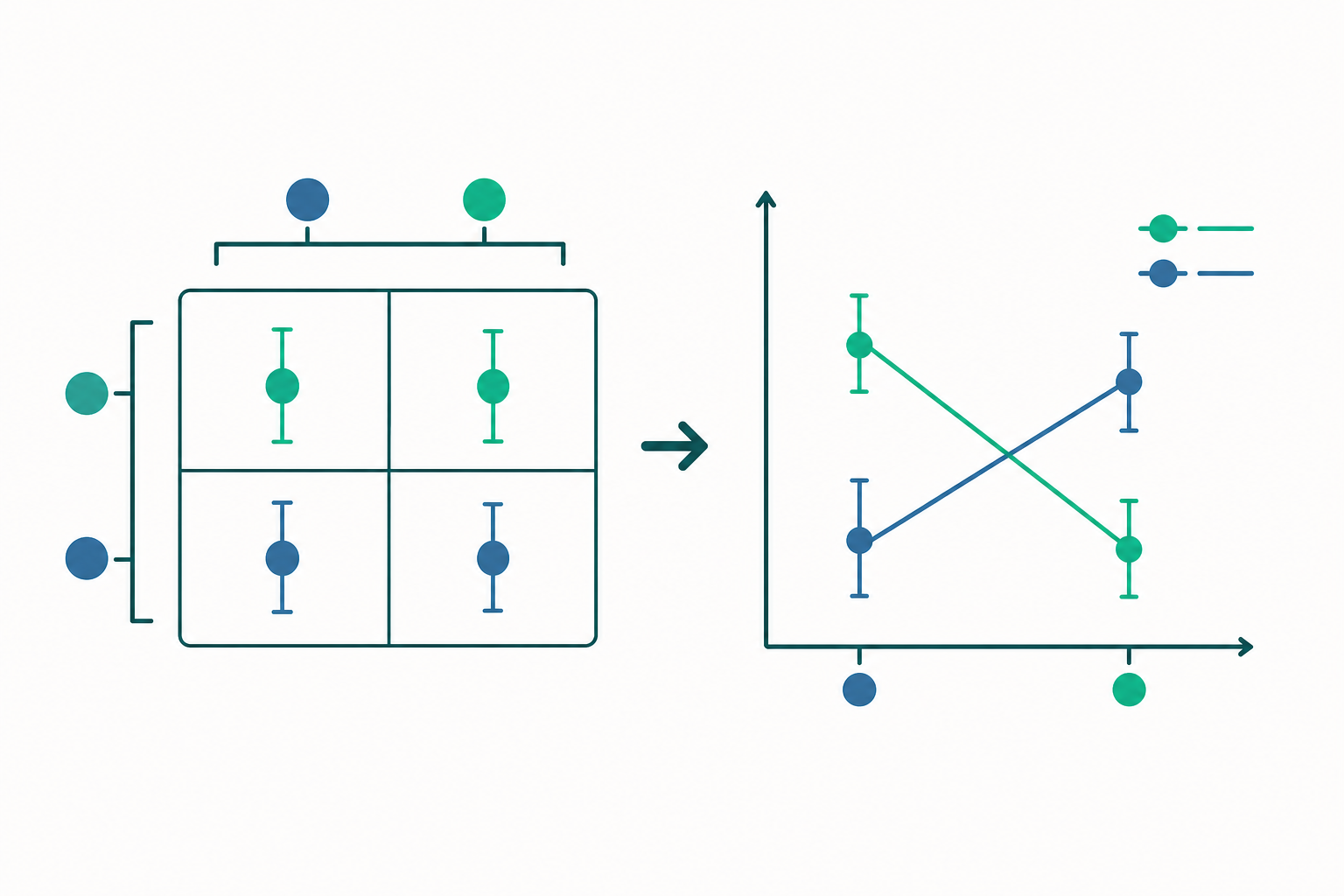
平方和的正交分解
二因子 ANOVA 的推導骨幹,是把總變異依正交對比拆解。記格均值 $\bar{Y}_{ij\cdot}$、列均值 $\bar{Y}_{i\cdot\cdot}$、行均值 $\bar{Y}_{\cdot j\cdot}$、總均值 $\bar{Y}_{\cdots}$。對單一觀測值做恆等分解:
$$ Y_{ijk}-\bar{Y}_{\cdots} = \underbrace{(\bar{Y}_{i\cdot\cdot}-\bar{Y}_{\cdots})}_{A} + \underbrace{(\bar{Y}_{\cdot j\cdot}-\bar{Y}_{\cdots})}_{B} + \underbrace{(\bar{Y}_{ij\cdot}-\bar{Y}_{i\cdot\cdot}-\bar{Y}_{\cdot j\cdot}+\bar{Y}_{\cdots})}_{AB} + \underbrace{(Y_{ijk}-\bar{Y}_{ij\cdot})}_{E}. $$
在平衡設計下,這四個分量兩兩正交,因此平方和直接相加(交叉項加總為零):
$$ SS_{T}=SS_{A}+SS_{B}+SS_{AB}+SS_{E}, $$
其中
$$ SS_{A}=bn\sum_i(\bar{Y}_{i\cdot\cdot}-\bar{Y}_{\cdots})^2,\quad SS_{B}=an\sum_j(\bar{Y}_{\cdot j\cdot}-\bar{Y}_{\cdots})^2, $$
$$ SS_{AB}=n\sum_i\sum_j(\bar{Y}_{ij\cdot}-\bar{Y}_{i\cdot\cdot}-\bar{Y}_{\cdot j\cdot}+\bar{Y}_{\cdots})^2,\quad SS_{E}=\sum_i\sum_j\sum_k(Y_{ijk}-\bar{Y}_{ij\cdot})^2. $$
對應自由度為 $a-1$、$b-1$、$(a-1)(b-1)$、$ab(n-1)$,恰好加總為 $abn-1=N-1$。這個「自由度也可加」的事實,正是正交分解的副產品。
期望均方與 F 檢定的合理性
要理解為何用 $F$ 統計量,需計算各均方(mean square, $MS=SS/df$)的期望值。以固定效果模型為例,可推得:
$$ E[MS_{A}]=\sigma^2+\frac{bn}{a-1}\sum_i\alpha_i^2,\quad E[MS_{AB}]=\sigma^2+\frac{n}{(a-1)(b-1)}\sum_i\sum_j(\alpha\beta)_{ij}^2,\quad E[MS_{E}]=\sigma^2. $$
關鍵在於:在虛無假設 $H_0^{AB}:(\alpha\beta)_{ij}=0\ \forall i,j$ 下,$E[MS_{AB}]=\sigma^2=E[MS_{E}]$,兩者估計同一個量;而當交互作用存在時,分子期望被推高。由 Cochran 定理,標準化後的各平方和在常態假設下服從獨立的卡方分配:$SS_{AB}/\sigma^2\sim\chi^2_{(a-1)(b-1)}$、$SS_{E}/\sigma^2\sim\chi^2_{ab(n-1)}$,故
$$ F_{AB}=\frac{MS_{AB}}{MS_{E}}\overset{H_0^{AB}}{\sim}F_{(a-1)(b-1),\,ab(n-1)}. $$
這便是 $F$ 檢定的數學根據:它是「被效果污染的變異」對「純誤差變異」的比值。統計素養提醒:$p$ 值小只代表觀測到的折線不平行程度,在 $H_0$ 為真時罕見,並不等於「交互作用很強」或「實務上重要」;效果量(如 $\eta_p^2=SS_{AB}/(SS_{AB}+SS_{E})$)才回答「有多大」。
定量小範例
考慮 $a=2$(教學法:傳統/AI 輔助)、$b=2$(先備知識:低/高),每格 $n=3$。格均值與格內樣本如下(分數,已知 $\sigma$ 未知):
| 低先備 | 高先備 | |
|---|---|---|
| 傳統 | 60, 62, 58($\bar{Y}=60$) | 70, 72, 68($\bar{Y}=70$) |
| AI 輔助 | 66, 68, 64($\bar{Y}=66$) | 90, 88, 92($\bar{Y}=90$) |
邊際均值:列均值 $\bar{Y}_{\text{傳統}}=65$、$\bar{Y}_{\text{AI}}=78$;行均值 $\bar{Y}_{\text{低}}=63$、$\bar{Y}_{\text{高}}=80$;總均值 $\bar{Y}_{\cdots}=71.5$。
主效果平方和:
$$ SS_A=bn\sum_i(\bar{Y}_{i\cdot}-71.5)^2=2\cdot3\big[(65-71.5)^2+(78-71.5)^2\big]=6(42.25+42.25)=507. $$
$$ SS_B=an\sum_j(\bar{Y}_{\cdot j}-71.5)^2=2\cdot3\big[(63-71.5)^2+(80-71.5)^2\big]=6(72.25+72.25)=867. $$
交互作用平方和:計算各格的交互殘差 $\bar{Y}_{ij}-\bar{Y}_{i\cdot}-\bar{Y}_{\cdot j}+\bar{Y}_{\cdots}$。以傳統×低為例:$60-65-63+71.5=3.5$;由對稱性四格分別為 $3.5,-3.5,-3.5,3.5$。故
$$ SS_{AB}=n\sum_i\sum_j(\cdot)^2=3\cdot(4\times 3.5^2)=3\times49=147. $$
誤差平方和:每格格內偏差平方和均為 $(-2)^2+0+2^2=8$,四格共 $SS_E=4\times8=32$,$df_E=ab(n-1)=4\times2=8$,故 $MS_E=4$。
交互作用 F 值:$df_{AB}=(a-1)(b-1)=1$,$MS_{AB}=147/1=147$,
$$ F_{AB}=\frac{147}{4}=36.75. $$
對照 $F_{1,8}$ 的 $0.05$ 臨界值約 $5.32$,$36.75$ 遠超之,故拒絕「無交互作用」。詮釋:AI 輔助相對傳統的增益,在高先備($+20$ 分)遠大於低先備($+6$ 分)——折線不平行,這正是「先備知識調節(moderate)了教學法效果」。此時若只報告主效果(AI 平均高 13 分)將具誤導性,務必先看交互作用、再做單純主效果(simple main effects)的事後分解。
深入探討(研究所視角)
從估計理論看,平衡固定效果二因子 ANOVA 的最小平方估計(OLS)等價於常態誤差下的最大概似估計(MLE),且因設計矩陣的各效果子空間正交,估計量 $\hat{\alpha}_i,\hat{\beta}_j,\widehat{(\alpha\beta)}_{ij}$ 彼此不相關、為 BLUE(Gauss–Markov)。其漸近性質可由 $M$-估計框架刻畫:在規律條件下 $\sqrt{N}(\hat{\theta}-\theta)\xrightarrow{d}\mathcal{N}(0,\,\sigma^2(\mathbf{X}^\top\mathbf{X}/N)^{-1})$,而 $F$ 檢定在 $H_0$ 下其分子分母比經 $\times df_1$ 後漸近於 $\chi^2_{df_1}$(即 Wald/LR/score 三者漸近等價)。動差法(method of moments)在此與 OLS 殊途同歸,因二階動差恰好給出 $\sigma^2$ 的無偏估計 $MS_E$。
不平衡設計的隱患最值得研究生警惕:當格內樣本數不等,效果子空間不再正交,$SS_A+SS_B+SS_{AB}\neq$「順序拆解之和」,於是出現 Type I/II/III 平方和之爭。Type III(邊際性、各效果在「其他效果已在模型中」下檢定)在主流軟體為預設,但其結果依賴對比編碼(必須用 sum-to-zero 而非 dummy 編碼才對應前述邊際約束),這是實證論文常見的隱性錯誤來源。
隨機效果與混合模型進一步推廣此框架:若 $B$ 為隨機因子,則 $E[MS_A]$ 的誤差項變為 $\sigma^2+n\sigma^2_{\alpha\beta}$,正確的 $F$ 分母不再是 $MS_E$ 而是 $MS_{AB}$。此一「找對誤差項」的問題,自然導向變異成分估計(REML)與線性混合模型(LMM),後者允許不平衡、缺失與層級巢狀結構,是當代教育與心理計量的主力工具。
貝氏對應將固定效果視為帶先驗的參數:常以階層先驗 $(\alpha\beta)_{ij}\sim\mathcal{N}(0,\tau^2)$ 取代硬性「等於零」假設,透過 $\tau^2$ 的後驗實現對交互作用的收縮(shrinkage),並可用 Bayes factor 或後驗區間取代二元的顯著與否判定,緩解 $p$ 值的閾值崇拜。
與機器學習/因果推論的連結最具啟發性。從預測角度,交互作用即「特徵間的非可加性」,對應到帶交互項的線性模型、樹模型的分裂結構,乃至 Friedman 的 H-statistic 與 SHAP interaction values——ANOVA 可視為這類非可加性偵測的古典原型,甚至有 functional ANOVA 分解將任意黑箱函數拆為主效果與高階交互。從因果角度,在潛在結果框架下,交互作用對應「效果調節」(effect modification),即 $E[Y(1)-Y(0)\mid B=j]$ 隨 $j$ 變化的異質處理效應(HTE)。但統計素養紅線在此尤其關鍵:ANOVA 的交互作用是觀測到的條件均值結構,唯有在隨機分派(或可忽略性成立)下才能賦予因果解讀;在觀察性資料中,看似的交互作用可能源自未測量混淆或選擇偏誤——別把「相關的調節」當成「因果的調節」。