
存活分析:Kaplan–Meier、Cox 迴歸與設限資料
當你關心的是「事件何時發生」而非「是否發生」——從設限資料、存活與危險函數,到 Kaplan–Meier 曲線、log-rank 檢定與 Cox 比例危險模型
為什麼「平均存活時間」會騙了你
假設你是一所大學的學務分析人員,想知道學生入學後「多久會輟學」。你手上有一份追蹤五年的資料,但難題立刻浮現:許多學生到資料截止那天還在學,他們根本還沒輟學,你不知道他們最終會不會輟學、何時輟學。如果你只計算「已經輟學者的平均在學時間」,會嚴重低估真正的留存能力——因為那些表現最好、一直沒離開的學生,全被你排除在分母之外了。
這正是存活分析(survival analysis)要解決的核心問題:當我們關心的不是「事件會不會發生」,而是「事件何時發生」,而且有一部分樣本在觀測期間內事件尚未發生時,傳統的線性迴歸或邏輯斯迴歸都會失靈。本文將帶你建立存活分析的完整圖像:從設限資料的本質,到 Kaplan–Meier 估計、log-rank 檢定,再到 Cox 比例危險模型與其背後的偏概似估計理論。
設限:為什麼不能用一般迴歸
存活分析處理的應變數是到事件發生的時間(time-to-event),例如學生從入學到輟學的天數、病人從確診到復發的月數。這種資料有兩個讓一般迴歸無法處理的特性。
第一,時間恆為正且分布通常嚴重右偏,違反線性迴歸的常態與等變異假設。第二,也是最關鍵的——設限(censoring)。
所謂設限,是指我們只擁有事件時間的「部分資訊」。最常見的是右設限(right censoring):在觀測結束時,某位學生仍在學,我們只知道他的真實輟學時間「大於」目前已觀測到的在學時間,但不知道確切值。其他形式還有左設限(事件在觀測開始前就已發生,只知時間小於某值)與區間設限(只知事件落在某段區間內)。
設限資料若被錯誤處理會造成系統性偏誤:
- 若把設限者直接當作「事件已發生」,會低估真實存活時間。
- 若直接刪除所有設限者,會丟掉大量資訊,且通常刪掉的正是存活最久的觀測,造成嚴重的選擇偏誤。
存活分析的精妙之處,在於它能同時利用「已發生事件」與「尚未發生事件」兩種觀測的資訊,讓設限者貢獻它所能提供的部分知識,而非全部丟棄。
兩個核心函數:S(t) 與 h(t)
要描述事件時間 $T$(一個非負隨機變數),我們用兩個互補的函數。
存活函數(survival function) 定義為個體存活超過時間 $t$ 的機率:
$$S(t) = P(T > t) = 1 - F(t)$$
其中 $F(t)$ 是累積分布函數。$S(t)$ 從 $S(0)=1$ 開始,隨時間單調遞減趨近於 0。在留存分析的語境裡,$S(t)$ 就是「入學後超過 $t$ 個學期仍在學的比例」。
危險函數(hazard function) 描述的是「在時間 $t$ 之前都尚未發生事件的條件下,恰好在 $t$ 這一瞬間發生事件的瞬時速率」:
$$h(t) = \lim_{\Delta t \to 0} \frac{P(t \le T < t + \Delta t \mid T \ge t)}{\Delta t}$$
危險函數刻畫的是「風險的即時強度」。例如學生輟學的危險率可能在第一學期最高、之後逐漸下降——這種「熬過第一年就穩定了」的型態,唯有危險函數能清楚呈現,存活曲線本身看不出來。
兩個函數之間有嚴格的數學關係。定義累積危險函數 $H(t)=\int_0^t h(u)\,du$,則:
$$S(t) = \exp\left(-\int_0^t h(u)\,du\right) = e^{-H(t)}$$
這個恆等式是整個存活分析的樞紐:知道危險函數就能還原存活函數,反之亦然。$h(t)$ 關注「機制」(風險如何隨時間變化),$S(t)$ 關注「結果」(最終還剩多少比例),兩者相輔相成。
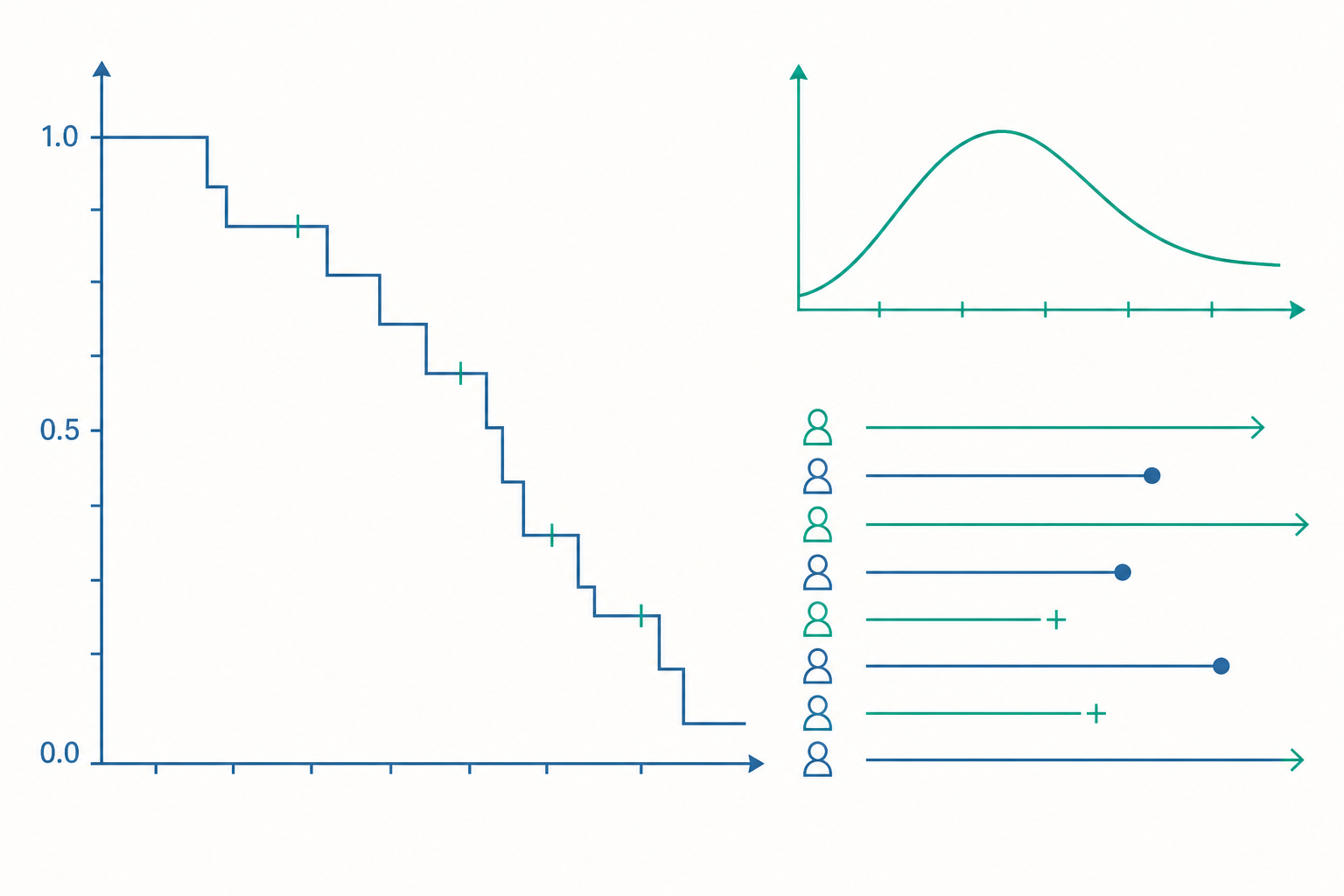
Kaplan–Meier:在設限下估計存活曲線
當我們不想對 $S(t)$ 的形狀做任何分布假設時,Kaplan–Meier(KM)估計量是最常用的無母數方法。它的核心思想是把存活機率拆解成一連串「條件存活」的連乘。
設觀測到事件發生的相異時間點為 $t_1 < t_2 < \cdots < t_k$。在每個事件時間 $t_i$:
- $d_i$ = 在 $t_i$ 發生事件(如輟學)的人數
- $n_i$ = 在 $t_i$ 之前仍處於「風險集合(risk set)」的人數,也就是還沒發生事件、也還沒被設限離開的人數
則 Kaplan–Meier 估計量為:
$$\hat{S}(t) = \prod_{t_i \le t} \left(1 - \frac{d_i}{n_i}\right)$$
每個因子 $(1 - d_i/n_i)$ 是「已經活到 $t_i$ 的人,能再撐過 $t_i$ 的條件機率」。設限資料的處理就藏在 $n_i$ 裡:當某人在 $t_i$ 與 $t_{i+1}$ 之間被設限,他會在下一個事件時間前從風險集合中移除,因此他在被設限「之前」對所有因子都有貢獻,但在被設限「之後」不再影響估計。這正是讓設限者貢獻部分資訊的機制。
KM 曲線是一條階梯狀遞減曲線,只在事件時間點下降,設限只會縮小風險集合而不造成下降(圖上常以小刻度標記設限點)。曲線的變異可用 Greenwood 公式估計,據此畫出信賴帶。
帶數字的小範例:手算 Kaplan–Meier
假設追蹤 10 位學生的在學情況(單位:學期),「+」表示設限(資料截止時仍在學):
2, 3, 3, 4+, 5, 6+, 7, 8+, 9, 10+
逐個事件時間計算:
| 時間 $t_i$ | 風險集合 $n_i$ | 事件數 $d_i$ | $1 - d_i/n_i$ | $\hat{S}(t_i)$ |
|---|---|---|---|---|
| 2 | 10 | 1 | 0.900 | 0.900 |
| 3 | 9 | 2 | 0.778 | 0.700 |
| 5 | 6 | 1 | 0.833 | 0.583 |
| 7 | 4 | 1 | 0.750 | 0.438 |
| 9 | 2 | 1 | 0.500 | 0.219 |
注意第 4 學期那位學生(4+)被設限,所以到 $t=5$ 時風險集合從 7 減為 6(少了 4+ 與已輟學的 3 人共 4 人,10−3−1=6)。最終 $\hat{S}(9) \approx 0.219$,意思是估計約有 21.9% 的學生能在學超過 9 個學期。
如果我們天真地只取「已輟學者」的平均在學時間 $(2+3+3+5+7+9)/6 \approx 4.83$ 學期,會嚴重低估留存能力,因為完全忽略了那 4 位仍在學、可能會撐更久的學生。
log-rank 檢定:比較兩條存活曲線
當我們想知道「兩組學生(例如有無參與輔導方案)的存活曲線是否有顯著差異」時,log-rank 檢定是標準工具。
它的邏輯是:在每一個事件時間點,把「實際觀測到的某組事件數」與「在兩組存活率相同的虛無假設下的期望事件數」相比。對每個事件時間 $t_i$,在虛無假設下第 1 組的期望事件數為:
$$e_{1i} = d_i \cdot \frac{n_{1i}}{n_i}$$
其中 $n_{1i}$ 是第 1 組在 $t_i$ 的風險人數。把所有時間點的「觀測減期望」加總,並除以其變異數,得到近似卡方分布的檢定統計量:
$$\chi^2 = \frac{\left(\sum_i (d_{1i} - e_{1i})\right)^2}{\sum_i v_i}$$
log-rank 檢定對「比例危險」型態的差異最敏感,且不需指定存活時間的分布。但它只能告訴你「有無差異」,無法量化差異大小,也無法調整其他共變數——這正是 Cox 模型登場的理由。
Cox 比例危險模型:把共變數放進來
我們通常不只想比較分組,還想知道「年齡、入學成績、是否打工」等多個變數如何共同影響危險率。Cox 比例危險模型(Cox proportional hazards model) 把危險函數寫成:
$$h(t \mid \mathbf{x}) = h_0(t) \exp(\beta_1 x_1 + \beta_2 x_2 + \cdots + \beta_p x_p)$$
這裡 $h_0(t)$ 是基準危險函數(baseline hazard),代表所有共變數為 0 時的危險率隨時間的變化;指數部分則是共變數造成的「等比例放大或縮小」。
Cox 模型最迷人之處在於它是半母數(semiparametric)的:它完全不對 $h_0(t)$ 的形狀做任何假設(無母數部分),只假設共變數以對數線性的方式作用(母數部分)。這讓它在不知道事件時間真實分布時依然能穩健地估計共變數效果。
危險比 hazard ratio 的解讀
把係數取指數,得到危險比(hazard ratio, HR)。對某共變數 $x_j$,在其他變數固定時,$x_j$ 增加一單位會讓危險率乘上 $e^{\beta_j}$:
$$\text{HR}_j = e^{\beta_j} = \frac{h(t \mid x_j + 1)}{h(t \mid x_j)}$$
解讀方式:
- $\text{HR} = 1$:該變數對危險率無影響。
- $\text{HR} > 1$($\beta_j > 0$):增加事件風險,存活時間縮短。例如 HR = 1.5 表示風險提高 50%。
- $\text{HR} < 1$($\beta_j < 0$):降低事件風險,具保護作用。例如某輔導方案的 HR = 0.7,表示參與者的輟學瞬時風險只有未參與者的 70%。
關鍵在於:HR 是相對的、與時間無關的常數。Cox 模型假設兩組的危險比在任何時間點都維持固定,這就是「比例危險假設」。
比例危險假設:必須檢驗的前提
「比例危險(proportional hazards)」假設兩個個體的危險函數之比,不隨時間改變:
$$\frac{h(t \mid \mathbf{x}_a)}{h(t \mid \mathbf{x}_b)} = \exp\big(\boldsymbol{\beta}^\top (\mathbf{x}_a - \mathbf{x}_b)\big) \quad \text{(與 } t \text{ 無關)}$$
若這個假設不成立——例如某輔導方案在第一年大幅降低輟學風險,但效果隨時間消退——那麼用單一 HR 描述就會誤導。檢驗方法包括:
- 圖示法:畫 $\log(-\log \hat{S}(t))$ 對 $\log t$ 的曲線,各組曲線若大致平行則支持假設。
- Schoenfeld 殘差檢定:檢驗 Schoenfeld 殘差與時間是否存在趨勢;若殘差對時間有顯著斜率,表示違反假設。
若假設被違反,補救做法包括:加入時變共變數(讓效果隨時間改變)、分層 Cox 模型(對違反的變數分層、各層有自己的 $h_0(t)$),或改用加速失效時間模型(AFT)。
重點回顧
- 設限是核心問題:事件時間資料常有右設限(觀測結束時事件尚未發生),一般迴歸無法處理;存活分析能同時利用已發生與未發生兩種觀測的資訊。
- S(t) 與 h(t) 互補:存活函數描述「還剩多少」,危險函數描述「即時風險強度」,兩者透過 $S(t)=e^{-H(t)}$ 相互換算。
- Kaplan–Meier 是無母數的存活曲線估計,用條件存活率連乘,並透過風險集合自然處理設限。
- log-rank 檢定比較組間存活曲線差異(觀測對期望);Cox 模型則進一步納入多個共變數,輸出與時間無關的危險比。
- 比例危險假設是 Cox 模型的關鍵前提,務必以 Schoenfeld 殘差或 log-log 圖檢驗,違反時改用時變共變數或分層模型。
深入探討(研究所視角)
偏概似:Cox 如何繞過基準危險
Cox 模型最深刻的創見,在於它能在完全不估計 $h_0(t)$ 的情況下估計 $\boldsymbol{\beta}$。這透過 偏概似(partial likelihood) 達成。
考慮在事件時間 $t_i$ 發生事件的個體 $(i)$。在「此時刻風險集合 $R(t_i)$ 中恰有一人發生事件」的條件下,事件「正好落在個體 $(i)$ 身上」的條件機率為:
$$L_i(\boldsymbol{\beta}) = \frac{\exp(\boldsymbol{\beta}^\top \mathbf{x}_{(i)})}{\sum_{j \in R(t_i)} \exp(\boldsymbol{\beta}^\top \mathbf{x}_j)}$$
注意分子分母的 $h_0(t_i)$ 完全約掉了——這正是奧妙所在。把所有事件時間的條件機率相乘,得到偏概似:
$$L(\boldsymbol{\beta}) = \prod_{i: \, \delta_i = 1} \frac{\exp(\boldsymbol{\beta}^\top \mathbf{x}_{(i)})}{\sum_{j \in R(t_i)} \exp(\boldsymbol{\beta}^\top \mathbf{x}_j)}$$
其中 $\delta_i=1$ 標記未設限的事件。最大化 $\log L(\boldsymbol{\beta})$ 可用 Newton–Raphson 求解;雖然只是「偏」概似,Cox(1972, 1975)與後續學者(如 Andersen–Gill 的計數過程鞅論)證明了所得估計量仍具有一致性與漸近常態性。值得注意的是,偏概似只用到事件的排序(ranking)而非確切時間值,這也解釋了為何 Cox 模型對時間軸的單調變換穩健。當多筆資料同時發生事件(ties),需用 Breslow、Efron 或精確法近似。$h_0(t)$ 若仍需估計,可在事後用 Breslow 估計量補上。
時變共變數:當風險因子會隨時間改變
基本 Cox 模型假設共變數在追蹤期間固定,但許多情況並非如此——學生的累積 GPA、是否轉換主修、是否中途開始打工,都會隨時間變動。時變共變數(time-varying covariates) 把模型推廣為:
$$h(t \mid \mathbf{x}(t)) = h_0(t) \exp\big(\boldsymbol{\beta}^\top \mathbf{x}(t)\big)$$
此時偏概似中個體 $j$ 在時間 $t_i$ 所用的是該時刻的共變數值 $\mathbf{x}_j(t_i)$。實作上常用「(start, stop] 計數過程格式」把每位個體切成多段時間區間。一個重要前提是區分外生(external)與內生(internal)時變共變數:內生共變數(如生物標記,本身會被事件過程影響)需謹慎處理,否則會引入偏誤。此外,把交互項 $x_j \cdot g(t)$($g(t)$ 為時間的某函數)放入模型,本身就是「放寬比例危險假設」的標準手法。
競爭風險:當事件不只一種
標準存活分析隱含「只有一種事件、且設限與事件獨立」。但現實常見競爭風險(competing risks):學生可能「輟學」、「轉學」或「休學」,這些是互斥的終點,一旦發生其中之一,其他事件便不再可能。若把「轉學」單純當成設限,會違反獨立設限假設並高估「輟學」的累積發生率。
正確做法是分析累積發生函數(cumulative incidence function, CIF),對事件類型 $k$ 定義為:
$$F_k(t) = P(T \le t, \, \text{event type} = k)$$
對應的建模工具有二:因果別危險(cause-specific hazard) 模型把其他競爭事件視為設限、各自配適 Cox 模型,回答「在尚未發生任何事件者中,某類事件的瞬時率」;Fine–Gray 部分分布危險(subdistribution hazard) 模型則直接對 CIF 建模,回答「某類事件的累積發生機率如何受共變數影響」。兩者解讀不同、不可混用:前者談機制(為何發生此類事件),後者談負擔(最終有多少比例會經歷此類事件)。在學生留存分析中,若同時關心輟學與轉學,競爭風險框架能避免把兩種離校原因混為一談。
與 Uedu 留存分析的連結
回到開頭的學生留存問題:傳統「是否輟學」的邏輯斯迴歸只能回答「會不會」,丟失了「何時」的全部資訊,也無法妥善處理仍在學的設限者。改用存活分析後,我們能畫出不同入學管道或不同輔導介入的 Kaplan–Meier 留存曲線、用 log-rank 檢定差異、再以 Cox 模型在控制背景變數後估計各因子的危險比;若關心多種離校型態,則進一步採競爭風險模型。
最後必須強調方法的限制與假設:所有結論都建立在「設限機制與事件獨立」「比例危險(若用 Cox)」等前提上,且 Cox 危險比是關聯性而非自動的因果效應;要做因果推論,仍需結合隨機分派、傾向分數或其他識別策略,並對未測量的干擾因子保持審慎。存活分析提供的是描述事件時序的強大語言,而非取代研究設計的萬靈丹。