
試題反應理論(IRT):從答對率到難度與鑑別度的現代測量
把「人的能力」與「題的特性」放上同一條尺度——理解 1PL/2PL/3PL、試題特徵曲線、資訊函數,以及 MML 與 DIF 的研究所視角
為什麼同樣答對 30 題,兩個人的能力卻不一樣?
假設兩位學生在不同的考卷上都答對了 30 題:一位寫的是難度偏高的進階卷,另一位寫的是偏簡單的基礎卷。直覺告訴我們,這兩個 30 分不該被當成同一回事。但古典測驗理論(Classical Test Theory, CTT)只看「總分」或「答對率」,它無從區分這件事——因為在 CTT 裡,題目的難度被定義成「這群受試者的平均答對率」,而學生的能力被定義成「這份題目上的總分」。題目特性依賴於施測樣本,受試者分數依賴於題目組成,兩者循環糾纏。試題反應理論(Item Response Theory, IRT)的整個出發點,就是把「人的能力」與「題的特性」放到同一條尺度上,各自獨立估計,讓「答對率」升級為「在某能力水準下答對某題的機率」。
CTT 的限制:分數與難度互相綁架
CTT 的核心模型是 $X = T + E$(觀測分數 = 真分數 + 誤差),它簡潔好用,但有兩個樣本依賴(sample-dependent)的致命弱點。
第一,題目難度依賴樣本。CTT 把難度定義為通過率 $p_i = \frac{\text{答對人數}}{\text{總人數}}$。同一題給資優班測 $p=0.9$、給後段班測 $p=0.3$,於是「這題有多難」竟然取決於誰來考。第二,受試者分數依賴題目。能力高低用總分衡量,但總分的高低同時取決於題目難易;換一份考卷,同一個人的分數就變了,跨測驗不可比。
此外 CTT 的信度(測量精度)是「整份測驗一個常數」,它假設對所有能力水準的受試者,測量誤差一樣大。但實務上,一份偏難的卷子對高能力者量得很準、對低能力者幾乎是猜測。IRT 要把這三件事都修正:難度與能力在同一尺度、彼此分離估計,且測量精度隨能力水準而變。
從答對機率出發:item characteristic curve
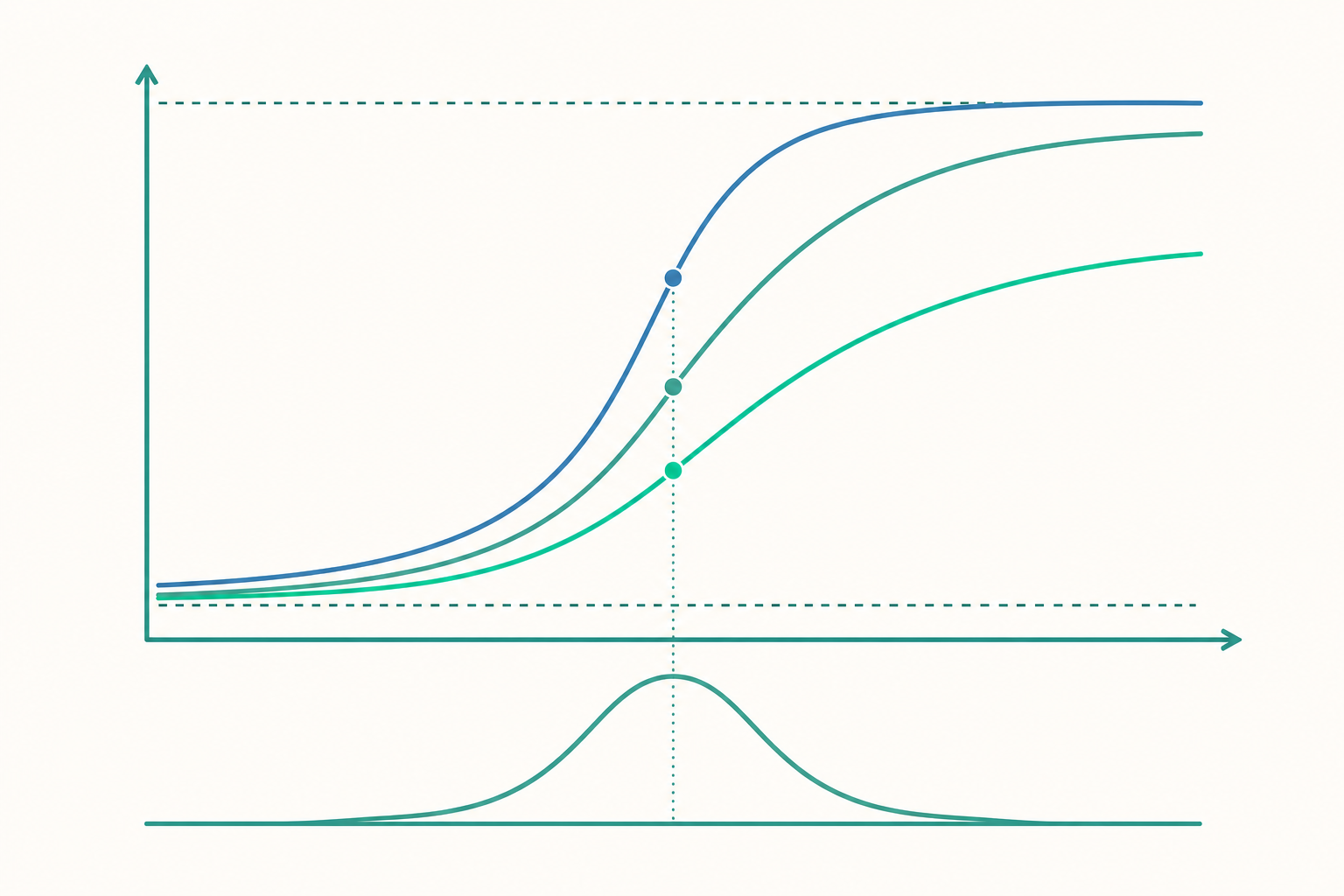
IRT 不問「答對幾題」,而是建模「能力為 $\theta$ 的受試者答對第 $i$ 題的機率」$P_i(\theta)$。把這個機率對能力 $\theta$ 畫出來,得到一條 S 形曲線,稱為試題特徵曲線(item characteristic curve, ICC)。能力 $\theta$ 通常標準化為平均 0、標準差 1 的尺度,越往右能力越高。
最簡單的模型是 Rasch 模型(1PL),每題只有一個難度參數 $b_i$:
$$P_i(\theta) = \frac{1}{1 + e^{-(\theta - b_i)}}.$$
注意當 $\theta = b_i$ 時,指數為 0,$P_i = 0.5$。所以難度參數 $b_i$ 的直觀意義是「答對機率恰為一半時所需的能力水準」。$b_i$ 越大代表題目越難(要更高的能力才能達到五成把握)。難度與能力放在同一條 $\theta$ 尺度上,這正是 IRT 與 CTT 的根本差異——難度不再是百分比,而是與人對齊的位置座標。
三個參數:難度 b、鑑別度 a、猜測 c
Rasch 假設所有題目的 ICC 形狀相同(斜率一致),只是左右平移。但真實題目的「鑑別力」不同,於是引入 2PL 模型,加上鑑別度參數 $a_i$:
$$P_i(\theta) = \frac{1}{1 + e^{-a_i(\theta - b_i)}}.$$
$a_i$ 控制 ICC 在 $\theta=b_i$ 處的斜率(曲線最陡的地方),因此稱為鑑別度(discrimination)。斜率越陡,代表能力略高於或略低於 $b_i$ 的人,答對機率差距越大——這題越能把高低能力者「分得開」。鑑別度低(曲線平緩)的題目,無論能力高低答對機率都差不多,對量測幫助有限。
選擇題還有猜對的可能,於是 3PL 模型再加一個猜測參數 $c_i$(下漸近線,pseudo-guessing):
$$P_i(\theta) = c_i + (1 - c_i)\,\frac{1}{1 + e^{-a_i(\theta - b_i)}}.$$
當 $\theta \to -\infty$,$P_i \to c_i$ 而非 0:能力再低,亂猜也有 $c_i$ 的命中率(四選一的題理論下界約 0.25)。在 3PL 中,$b_i$ 仍是反曲點對應的能力,但此時 $P_i(b_i) = \frac{1+c_i}{2}$,不再是 0.5。三個模型由簡到繁,參數越多越貼近資料,但需要的樣本量也越大、估計越不穩定:1PL 約數百人即可穩定校準,2PL 通常建議數百至上千,3PL 因猜測參數與難度高度相關、概似面平緩,往往需上千份作答並對 $c_i$ 設先驗才不致發散。實務上的模型選擇是「貼合度」與「可估計性」的權衡,常以概似比檢定或資訊準則(AIC、BIC)比較巢狀模型,而非一味追求參數多。
局部獨立:把所有題串起來的關鍵假設
IRT 之所以能把整份測驗的反應拆解成一題一題的機率連乘,靠的是局部獨立(local independence)假設:在控制住能力 $\theta$ 之後,受試者在各題上的反應彼此獨立。換句話說,題目之間的相關「全部」由共同的潛在能力 $\theta$ 解釋,扣掉 $\theta$ 後就沒有殘餘關聯。
這讓某位能力為 $\theta$ 的受試者,其作答向量 $(u_1, u_2, \dots, u_n)$($u_i=1$ 為答對)的概似函數能寫成乘積:
$$L(\theta) = \prod_{i=1}^{n} P_i(\theta)^{u_i}\,[1 - P_i(\theta)]^{1-u_i}.$$
局部獨立若被違反(例如同一篇閱讀測驗的數小題共享題幹,答錯第一題就連帶答錯後面),會高估測驗資訊、低估標準誤,使能力估計過度自信。這也是為什麼題組(testlet)需要特別的模型處理,常見做法是引入題組隨機效果(testlet effect),或改用考慮殘餘相關的雙因子(bifactor)模型,把題幹共享造成的關聯吸收進額外的潛在維度。局部獨立是整套 IRT 概似推論的地基——一旦它與「單維度」一同成立,整份測驗的反應才能正當地拆成各題機率的連乘。
測驗資訊函數:精度隨能力而變
CTT 用一個信度數字概括「整份測驗有多準」,IRT 則用試題資訊函數(item information function)描述「每一題在不同能力水準提供多少資訊」。對 2PL:
$$I_i(\theta) = a_i^2\,P_i(\theta)\,[1 - P_i(\theta)].$$
由於 $P(1-P)$ 在 $P=0.5$(也就是 $\theta = b_i$)時最大,一題在「難度等於受試者能力」時提供最多資訊;偏離越遠,資訊越少。鑑別度 $a_i$ 以平方放大資訊,高鑑別度題目貢獻特別大。
由局部獨立,測驗資訊函數(test information function)就是各題資訊相加:
$$I(\theta) = \sum_{i=1}^{n} I_i(\theta).$$
能力估計的標準誤則為資訊的倒數開根號:
$$\mathrm{SE}(\hat\theta) = \frac{1}{\sqrt{I(\theta)}}.$$
這帶來一個 CTT 給不了的洞見:測量精度是 $\theta$ 的函數。若把題目難度集中在中等能力區間,測驗對中段最準、對極端者誤差大。要量得準,就該在受試者能力附近多放高鑑別度的題——這正是適性測驗的理論支點。
帶數字的小範例:解讀一題並算資訊
某題以 2PL 估出 $a_i = 1.5$、$b_i = 0.4$。先看一位能力 $\theta = 0.4$(恰等於難度)的學生答對機率:
$$P_i(0.4) = \frac{1}{1 + e^{-1.5(0.4 - 0.4)}} = \frac{1}{1 + e^{0}} = \frac{1}{2} = 0.50.$$
如預期,能力等於難度時答對機率為五成。再看一位能力 $\theta = 1.4$ 的學生(高出難度 1 個單位):
$$a_i(\theta - b_i) = 1.5 \times (1.4 - 0.4) = 1.5,\qquad P_i(1.4) = \frac{1}{1 + e^{-1.5}} = \frac{1}{1 + 0.2231} \approx 0.818.$$
能力高 1 個標準差,答對機率從 0.50 跳到約 0.82。接著算這題對 $\theta=0.4$ 者提供的資訊:
$$I_i(0.4) = a_i^2\,P(1-P) = 1.5^2 \times 0.5 \times 0.5 = 2.25 \times 0.25 = 0.5625.$$
對 $\theta=1.4$ 者:
$$I_i(1.4) = 1.5^2 \times 0.818 \times (1 - 0.818) = 2.25 \times 0.818 \times 0.182 \approx 0.335.$$
同一題,對能力等於難度者提供 0.56 的資訊,對能力偏離 1 單位者只剩 0.34。若整份測驗在 $\theta=0$ 處累積出 $I(0)=10$,則該處標準誤為 $1/\sqrt{10} \approx 0.316$;若在 $\theta=2$ 處只累積出 $I(2)=2.5$,標準誤達 $1/\sqrt{2.5} \approx 0.632$,是前者的兩倍。同一份測驗對不同能力者的可靠度,相差一倍。
重點回顧
- CTT 的根本問題是樣本依賴:難度(通過率)依賴施測對象、能力(總分)依賴題目組成,兩者循環綁定且不可跨測驗比較;IRT 把人與題放到同一條 $\theta$ 尺度上分離估計。
- 三個參數各司其職:難度 $b$ 是答對機率達中點所需的能力位置,鑑別度 $a$ 是 ICC 的陡峭程度(分辨高低能力的力道),猜測 $c$ 是下漸近線(亂猜的命中率)。1PL/2PL/3PL 依序加入這些參數。
- 試題特徵曲線(ICC) 把「答對率」升級為「能力的函數」,是 IRT 視覺化與直覺的核心。
- 資訊函數讓精度隨能力變化:$I_i(\theta)=a_i^2 P(1-P)$ 在 $\theta=b_i$ 最大,$\mathrm{SE}(\hat\theta)=1/\sqrt{I(\theta)}$;這是 CTT 單一信度做不到的局部精度刻畫,也是適性測驗(CAT)選題的依據。
- 局部獨立 是把多題串成概似連乘的地基,違反它會讓測驗資訊被高估、能力估計過度自信。
深入探討(研究所視角)
參數估計:JML、MML 與 EAP。 早期的聯合最大概似(joint maximum likelihood, JML)同時估計所有人的 $\theta$ 與所有題的參數,但因人數隨樣本增加(incidental parameters problem),題目參數估計不一致。現代主流是邊際最大概似(marginal maximum likelihood, MML):把能力 $\theta$ 視為來自某母體分布(通常假設 $\theta \sim \mathcal{N}(0,1)$),對它積分積掉,得到只含題目參數的邊際概似
$$L(\boldsymbol{a},\boldsymbol{b},\boldsymbol{c}) = \prod_{j=1}^{N}\int_{-\infty}^{\infty}\Big[\prod_{i=1}^{n} P_i(\theta)^{u_{ji}}(1-P_i(\theta))^{1-u_{ji}}\Big]\,g(\theta)\,\mathrm{d}\theta.$$
這個積分沒有封閉解,實務以 Gauss–Hermite 求積離散近似,再用 EM 演算法迭代:E 步以當前題目參數計算每人 $\theta$ 的後驗期望(expected counts),M 步把每個求積節點當作「已知能力」更新題目參數。MML 讓題目參數估計在受試者數 $N\to\infty$ 時一致且漸近常態,標準誤由觀測 Fisher 資訊矩陣取得。
題目參數估出後,回頭估個別能力。最大概似估計 $\hat\theta_{\text{MLE}}$ 解 $\frac{\partial}{\partial\theta}\log L(\theta)=0$,但對全對或全錯的作答會發散($\pm\infty$)。EAP(expected a posteriori) 改採貝氏觀點,以先驗 $g(\theta)$ 結合概似得後驗,取後驗期望為點估計:
$$\hat\theta_{\text{EAP}} = \frac{\int \theta\, L(\theta)\,g(\theta)\,\mathrm{d}\theta}{\int L(\theta)\,g(\theta)\,\mathrm{d}\theta}.$$
EAP 永遠有限、計算只需一次求積(不必迭代),且後驗標準差直接給出測量誤差,因此在電腦化適性測驗(CAT)的即時計分中廣泛採用;代價是向先驗均值收縮(shrinkage),對極端能力者略有偏誤。MAP(後驗眾數)則介於兩者之間。
DIF:差異試題功能。 若一道題在控制住能力 $\theta$ 後,不同群組(如性別、語言背景)的答對機率仍有系統差異,即構成差異試題功能(differential item functioning, DIF)——這是測驗公平性的核心威脅。形式上,DIF 違反「條件獨立於群組」:$P(u_i=1 \mid \theta, G=A) \neq P(u_i=1 \mid \theta, G=B)$ 對某些 $\theta$ 成立。均勻 DIF(uniform DIF) 是兩群 ICC 平行位移($b$ 不同、$a$ 相同),非均勻 DIF(non-uniform DIF) 則是斜率也不同($a$ 交互作用),ICC 交叉。常用偵測法包括 Mantel–Haenszel(以總分分層後檢定 $2\times 2$ 表的勝算比一致性,適合均勻 DIF)、邏輯斯回歸法(在 logit 模型中加入群組主效果與群組 $\times$ 能力交互項,後者顯著即非均勻 DIF),以及 IRT-based 的概似比檢定(比較限制兩群題目參數相等與否的兩模型概似)。須強調:DIF 是「條件機率差異」,不等於「組間平均分差」——後者可能只反映真實的能力分布差異(impact),唯有扣除能力後仍存在的差異才算 item bias。偵測到 DIF 後仍需內容專家判斷該題是否真涉及與構念無關的偏誤,統計訊號不能單獨定罪一道題。
與 Uedu 平台的連結。 Uedu 的 quiz 題庫累積了大量跨課程、跨學期的作答資料,正是估計 $a_i$、$b_i$ 的素材:以 MML 校準後,每道題能附上難度與鑑別度,教師可汰除鑑別度過低($a$ 接近 0)或難度極端的題目,並以資訊函數規劃一份在目標能力區間量得最準的考卷。Uedu Cognomics(UCG)的 14 個認知測驗則對應到反應時間與正確率的潛在能力建模,是 IRT 與其延伸(如反應時間的對數常態模型、適性化施測)的應用場域。更進一步,資訊函數 $\mathrm{SE}(\hat\theta)=1/\sqrt{I(\theta)}$ 提供了 電腦化適性測驗(CAT) 的選題準則:每答一題就更新 $\hat\theta$,再從題庫挑出在當前 $\hat\theta$ 處資訊最大的下一題,使測驗以最少題數達到目標精度。需提醒的是,這些估計建立在局部獨立、單維度(unidimensionality)與模型設定正確的假設上;若題庫實際為多維、或存在 DIF 與題組效應,參數校準會偏誤,CAT 的選題與計分也會連帶失準。IRT 強大,但它是「假設驅動」的測量框架,模型診斷(如殘差分析、$\theta$ 不變性檢驗)與假設檢核應與估計同等被重視。