
失業(進階):流量視角、DMP 搜尋媒合與 Shimer 之謎
從存量快照走向流量引擎,用穩態方程式、職缺創造條件與 Nash 議價推導內生失業率,並直面標準模型對不上資料的量化難題。
失業率為什麼會「黏」在某個水準?流量的視角
入門篇把失業(unemployment)拆成摩擦性、結構性、循環性三種類型,也介紹了自然失業率與工資僵固性。那是一張「存量快照」(stock snapshot):某個時點上有多少人失業。但如果你盯著任何一個經濟體的月度資料看久了,會發現一個更深的謎題——失業率像被某種力量「黏」住,在景氣循環中緩慢漂移,卻又很少瞬間崩跌或暴衝。
要理解這種黏性,光看存量是不夠的。一個關鍵的觀念轉換是:失業是一個池子,水位由「進水」與「出水」兩股流量(flows)共同決定。 每個月都有人失去工作(進水),也有人找到工作(出水)。即使失業這個池子的水位(失業率)看起來穩定,底下其實有龐大的人流不斷進出。美國的資料顯示,每個月約有數百萬人在「就業」與「失業」之間切換——存量的平靜,掩蓋了流量的洶湧。
這篇進階篇要做的,就是把入門篇略過的「機制引擎」打開:用流量方程式重新定義失業,推導 DMP 搜尋媒合模型的均衡,並直面一個讓總體經濟學家頭痛多年的實證難題。
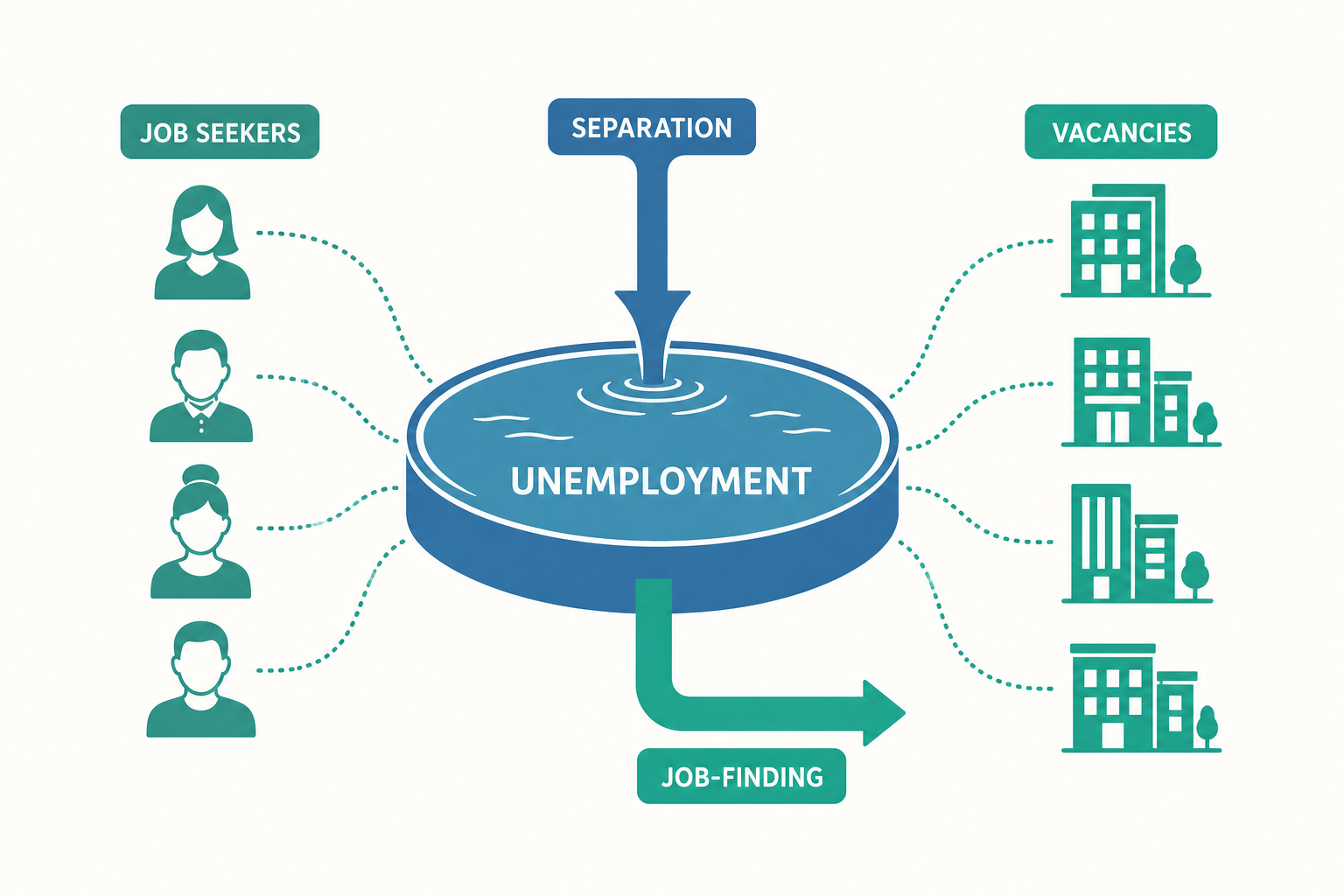
把失業寫成一條流量方程式
我們先建立最基本的勞動市場流量模型。把勞動力簡化為兩種狀態:就業(employed, $E$)與失業(unemployed, $U$),勞動力 $L = E + U$。定義兩個核心比率:
- 離職率/分離率(separation rate)$s$:每單位時間內,一個就業者失去工作的機率;
- 求職成功率/媒合率(job-finding rate)$f$:每單位時間內,一個失業者找到工作的機率。
在連續時間下,失業池的水位變化量等於「進水」減「出水」:
$$ \frac{dU}{dt} = \underbrace{s \cdot E}_{\text{新增失業}} - \underbrace{f \cdot U}_{\text{脫離失業}} $$
當系統達到穩態(steady state)時,水位不再變化,$dU/dt = 0$,於是 $s \cdot E = f \cdot U$。把 $E = L - U$ 代入並整理,可得穩態失業率:
$$ u^* = \frac{U}{L} = \frac{s}{s + f} $$
這條簡潔的公式威力驚人。它告訴我們:失業率不是由「失業有多嚴重」單獨決定,而是由分離率與求職率的相對大小決定。 失業率高,可能是因為人們容易丟工作($s$ 大),也可能是因為丟了工作後很難找回來($f$ 小)。這兩種情境對應截然不同的政策。
看一個例子:同樣的失業率,兩種完全不同的病
假設甲、乙兩國失業率都是 $5\%$,乍看之下勞動市場狀況相同。但拆開流量:
- 甲國:分離率 $s = 0.005$(每月只有千分之五的人丟工作),求職率 $f = 0.095$。代入 $u^* = 0.005 / (0.005 + 0.095) = 0.05$。
- 乙國:分離率 $s = 0.025$,求職率 $f = 0.475$。代入 $u^* = 0.025 / (0.025 + 0.475) = 0.05$。
兩國失業率都是 $5\%$,但乙國的兩個流量率都是甲國的五倍。這意味著乙國的勞動市場「流動性」極高:工作換得勤、丟得快、也找得快,平均失業時間短。甲國則相反,工作穩定但一旦失業就難以脫身,失業會集中在少數人身上、持續很久。
這正是歐洲與美國勞動市場長年差異的縮影。歐洲(尤其是 1980 年代後)的特徵是低流量、長期失業:分離率不高,但失業者的求職率偏低,失業久滯(這與較嚴格的解僱保護、較慷慨的失業給付有關)。美國則是高流量、短期失業:丟工作機率高,但找回工作也快。
政策啟示:對甲國(歐洲型),降低失業要從提升 $f$ 下手——改善媒合效率、再培訓、降低求職摩擦;對乙國(美國型)若想降低失業波動,反而要關注 $s$ 的循環性飆升。同一個失業率數字,背後是兩種不同的病,需要不同的藥。
DMP 模型:把摩擦寫成均衡
入門篇提到 DMP 模型(Diamond–Mortensen–Pissarides)與媒合函數 $M = m(U, V)$ 得到了 2010 年諾貝爾獎。這裡我們把這個模型的引擎拆開,看它如何把「摩擦性失業」從一句描述,變成一個可以求解的均衡。
媒合函數與市場緊俏度
設媒合函數 $M = m(U, V)$,其中 $V$ 是職缺數(vacancies)。假設它規模報酬不變(constant returns to scale),這是一個關鍵且有實證支持的假設。定義勞動市場緊俏度(labor market tightness):
$$ \theta = \frac{V}{U} $$
$\theta$ 衡量「每位失業者面對多少職缺」。$\theta$ 越高,代表市場越偏向求職者(缺工)。由規模報酬不變,可把求職率與職缺填補率都寫成 $\theta$ 的函數:
- 失業者的求職率:$f(\theta) = m(U,V)/U = m(1, \theta) \equiv q(\theta)\,\theta$,且 $f'(\theta) > 0$(市場越緊,越快找到工作);
- 職缺的填補率:$q(\theta) = m(U,V)/V = m(1/\theta, 1)$,且 $q'(\theta) < 0$(市場越緊,職缺越難填)。
這裡出現一個重要的搜尋外部性(search externality):當更多廠商開職缺($\theta$ 上升),失業者更容易找到工作(對失業者是正外部性),但每個職缺卻更難填補、互相排擠(對其他廠商是負外部性)。市場參與者各自只看自己的利益,未必能達到社會最適。
職缺創造條件:廠商何時願意開缺
廠商開一個職缺要付出搜尋成本 $c$(每單位時間),開缺後以機率 $q(\theta)$ 填補。一旦媒合成功,這份工作每期帶來的剩餘(產出 $p$ 減去工資 $w$)會持續,直到以機率 $s$ 被打散。
用貝爾曼方程(Bellman equation)描述廠商持有「空缺職位」的價值 $J_V$ 與「已填補職位」的價值 $J_F$。在自由進入(free entry)的均衡下,廠商會持續開缺直到開缺的淨值為零,即 $J_V = 0$。經過推導,可得到簡潔的職缺創造條件(job creation condition):
$$ \frac{c}{q(\theta)} = \frac{p - w}{r + s} $$
左邊 $c/q(\theta)$ 是「填滿一個職缺的預期搜尋成本」(每期成本 $c$ 乘以平均等待時間 $1/q(\theta)$)。右邊是「一份工作帶來的折現後剩餘」——分子是每期利潤 $p - w$,分母 $r + s$ 是有效折現率(利率 $r$ 加上工作被打散的風險 $s$)。這個等式的直覺是:廠商開缺直到「找人的邊際成本」等於「找到人後的預期收益」。
Nash 議價:工資如何決定
職缺創造條件裡的工資 $w$ 從哪來?DMP 模型不假設工資由競爭市場決定(因為有摩擦,媒合成功的雙方之間存在一塊「剩餘」可以分配),而是用Nash 議價(Nash bargaining)來分剩餘。設勞工的議價力為 $\beta \in (0,1)$,工資 $w$ 由下式決定,讓勞工分得總媒合剩餘的 $\beta$ 比例:
$$ w = \beta (p + c\,\theta) + (1 - \beta)\, z $$
其中 $z$ 是失業者的「外部選項」(unemployment value,包含失業給付與閒暇價值)。直覺上,工資是勞工外部選項 $z$ 與廠商生產力 $p$ 之間的加權平均,權重由議價力 $\beta$ 決定;當市場越緊($\theta$ 高),勞工外部機會越好,工資也越高。
把這條工資方程式代回職缺創造條件,就得到一條只含 $\theta$ 的方程,可解出均衡的市場緊俏度 $\theta^*$。有了 $\theta^*$,便能算出均衡求職率 $f(\theta^*)$,再代入前一節的穩態公式 $u^* = s/(s + f(\theta^*))$,就得到內生決定的均衡失業率。摩擦性失業,至此成為一個完整模型的均衡輸出,而不只是一個分類標籤。
動手試試:當失業給付提高,均衡失業率往哪走?
請用上面的模型推理鏈,自己走一遍因果,再對照答案。
問題:政府提高失業給付,使失業者的外部選項 $z$ 上升。均衡失業率會如何變化?
推理:
- $z$ 上升 → 由工資方程式 $w = \beta(p + c\theta) + (1-\beta)z$,工資 $w$ 上升。
- $w$ 上升 → 由職缺創造條件 $c/q(\theta) = (p-w)/(r+s)$,右邊的工作剩餘 $p - w$ 下降,廠商開缺的誘因減弱。
- 廠商減少開缺 → $\theta = V/U$ 下降 → 求職率 $f(\theta)$ 下降。
- 由 $u^* = s/(s+f)$,$f$ 下降 → 均衡失業率 $u^*$ 上升。
結論:在這個機制下,更慷慨的失業給付會透過「推高工資、壓低職缺、降低求職率」這條鏈,提高均衡失業率。但請注意,這只是模型的一個面向——慷慨的給付同時也讓失業者有餘裕找到更匹配的工作(提升媒合品質),並在衰退期支撐總需求。政策評估必須權衡這些力量,不能只看單一機制。這也是為什麼經濟學家對「最適失業給付」始終存在嚴肅辯論。
Shimer 之謎:漂亮的模型,對不上的資料
DMP 模型優雅、可解、得了諾貝爾獎,但它在 2005 年遭遇一個著名的實證挑戰,史稱 Shimer 之謎(Shimer puzzle)。
Robert Shimer 拿標準校準的 DMP 模型去模擬:當生產力 $p$ 發生與資料相符的小幅波動時,模型預測的失業率與職缺數波動有多大?結果發現,模型產生的波動遠小於實際資料——大約只有資料的十分之一。換句話說,現實中失業與職缺隨景氣的劇烈起伏,標準 DMP 模型解釋不了。
問題的根源在 Nash 議價。當生產力 $p$ 上升時,工資 $w$ 也跟著等比例上升(因為工資是 $p$ 的加權平均),於是工作剩餘 $p - w$ 幾乎不變,廠商開缺的誘因也幾乎不變——職缺與失業因此紋風不動。工資太有彈性,把所有生產力衝擊都「吸收」掉了。
學界提出了幾條主要的修補方向:
- 工資僵固性(wage rigidity):Hall(2005)主張若工資對生產力衝擊反應遲鈍(黏性工資),則 $p$ 上升時 $p - w$ 會明顯放大,職缺反應就會被放大。這呼應了入門篇的工資僵固性,但這裡是用它來解釋「波動的放大」,而非單純的失業存在。
- 小剩餘校準(small surplus calibration):Hagedorn 與 Manovskii(2008)指出,若把失業者外部選項 $z$ 設得接近生產力 $p$(即工作剩餘 $p - z$ 很小),則生產力的小變動會對「剩餘」造成巨大的百分比變化,放大職缺反應。
- 沿用既有匹配的工資僵固(rigidity in new matches):區分新舊工作的工資調整速度。
Shimer 之謎的意義超越技術細節:它示範了一個內部邏輯自洽、能得諾貝爾獎的模型,仍可能在量化上對不上真實世界。好的理論不只要能講故事,還要能在數字上對帳。這正是現代總體經濟學從「定性敘事」走向「定量校準與檢驗」的縮影。
重點回顧
- 存量看水位,流量看引擎:失業率穩態為 $u^* = s/(s+f)$,由分離率 $s$ 與求職率 $f$ 共同決定,而非由「失業嚴重程度」單獨決定。
- 同樣的失業率可能是兩種病:低流量/長期失業(歐洲型,問題在 $f$ 太低)與高流量/短期失業(美國型,波動在 $s$)需要不同政策。
- DMP 模型把摩擦寫成均衡:媒合函數 + 職缺創造條件 + Nash 議價,三者聯立解出內生的市場緊俏度 $\theta^*$ 與均衡失業率。
- 搜尋外部性無所不在:廠商開缺對失業者是正外部性、對其他廠商是負外部性,市場均衡未必社會最適。
- Shimer 之謎是一記警鐘:標準 DMP 模型量化上低估了失業波動,工資的議價彈性是元兇;理論不只要自洽,還要對得上資料。
深入探討(研究所視角)
進到研究所層次,搜尋摩擦的勞動市場理論會與效率分析、最適政策與一般均衡建模交織,以下提供幾條值得深挖的線索。
Hosios 條件與社會效率。 既然搜尋外部性使市場均衡未必有效率,那什麼時候才有效率?Hosios(1990)給出了一個漂亮的答案:當勞工的議價力 $\beta$ 恰好等於媒合函數對失業的彈性 $\eta = -\frac{U}{m}\frac{\partial m}{\partial U}$ 時,正負外部性恰好抵銷,分散式均衡達到社會最適。
$$ \beta = \eta \quad\Longrightarrow\quad \text{均衡有效率(Hosios condition)} $$
當 $\beta > \eta$,勞工議價力過強、廠商開缺不足,失業偏高;當 $\beta < \eta$,則職缺過多。Hosios 條件把「外部性是否內部化」化約成一個可檢驗的參數關係,是搜尋理論最優美的結果之一,也是評估失業政策(如失業給付、聘僱補貼)是否改善效率的基準。
內生分離與工作摧毀。 標準 DMP 常把分離率 $s$ 視為外生常數,但 Mortensen 與 Pissarides(1994)進一步將 $s$ 內生化:每個工作的特定生產力會隨機波動,當它跌破一個「保留生產力」門檻 $\tilde{p}$ 時,雙方協議結束這份工作。於是分離也成為均衡選擇。這讓模型能同時解釋工作創造(job creation)與工作摧毀(job destruction)兩條流量,並對應到 Davis、Haltiwanger 與 Schuh 的著名實證——衰退期失業飆升,主要來自工作摧毀的劇烈跳升,而非工作創造的崩跌。
遲滯與多重均衡的再思考。 入門篇談過遲滯效應(hysteresis)。在搜尋架構下,遲滯可被建模為狀態依賴的求職率:長期失業者因技能折舊與雇主篩選(employer screening,雇主以失業時長作為負面信號)而面臨更低的 $f$,形成「失業越久越難脫身」的負向回饋(duration dependence)。這條機制把「暫時的循環性失業固化為結構性失業」給出了微觀基礎,也支持衰退期積極干預(避免長期失業累積)的政策論證。實證上要區分「真正的負向狀態依賴」與「異質性篩選」(找得到工作的人本來就先離開、留下的人本來就難媒合)是一大難題,需要動態追蹤資料與結構估計。
跨領域連結。 這套流量—搜尋框架的影響力遠超勞動市場:貨幣搜尋理論(Kiyotaki–Wright)用同樣的媒合邏輯解釋貨幣為何被接受;住房市場、婚配市場、線上平台媒合都借用了媒合函數。對教育與科技政策而言,搜尋摩擦的視角提醒我們:當生成式 AI 同時改變「工作摧毀」(自動化淘汰舊職位)與「媒合效率」(AI 求職/徵才工具改變 $f$)兩端,自然失業率與貝弗里奇曲線的位置都可能位移。理解失業的流量引擎,正是判讀這場技術變遷將如何重塑勞動市場的必備工具——而終身學習與技能再造,本質上就是在對抗負向的 duration dependence,避免暫時的衝擊在個人身上固化為永久的傷痕。