
發展經濟學進階:錯置、結構轉型與因果識別的工具箱
為什麼窮國的貧窮,有一大塊其實是「資源放錯地方」?從雙元經濟、結構轉型,到 DiD/RD/IV 與一般均衡批判的進階導覽。
如果窮國的資源沒有「放錯地方」,它們會富裕多少?
入門篇談了貧窮陷阱與制度命運。但現在請設想一個更精細的問題:把印度或奈及利亞的工廠、農地、勞工、資本通通拍照存檔,然後問——這些生產要素,是不是「擺錯位置」了?如果一間高生產力的工廠只用了 50 名工人,而隔壁一間瀕臨倒閉、生產力極低的工廠卻佔著 500 名工人與大筆貸款,那麼即使這個國家的「總要素」沒有改變,光是把資源從爛工廠搬到好工廠,總產出就會大幅躍升。
這個看似簡單的觀察,藏著當代發展經濟學最重要的量化發現之一:貧窮國家之所以窮,很大一部分不是因為它們缺乏資本或技術,而是因為它們「錯置(misallocation)」了既有的資源。Hsieh 與 Klenow(2009)的經典估計指出,若中國與印度的製造業要素配置效率能達到美國的水準,其製造業全要素生產力(total factor productivity, TFP)可分別提升約 30%–50% 與 40%–60%。換句話說,一大塊「貧窮」其實是組織與制度摩擦造成的浪費,而非物理稟賦的缺乏。
本篇承接入門篇,但轉向四個更進階的戰場:結構轉型(structural transformation)、資源錯置與雙元經濟(dual economy)、因果識別的工具箱(DiD/RD/IV),以及對 RCT 的一般均衡(general equilibrium)批判。我們會用到較多的公式與圖形語言,預設你已熟悉入門篇的貧窮陷阱與制度概念。
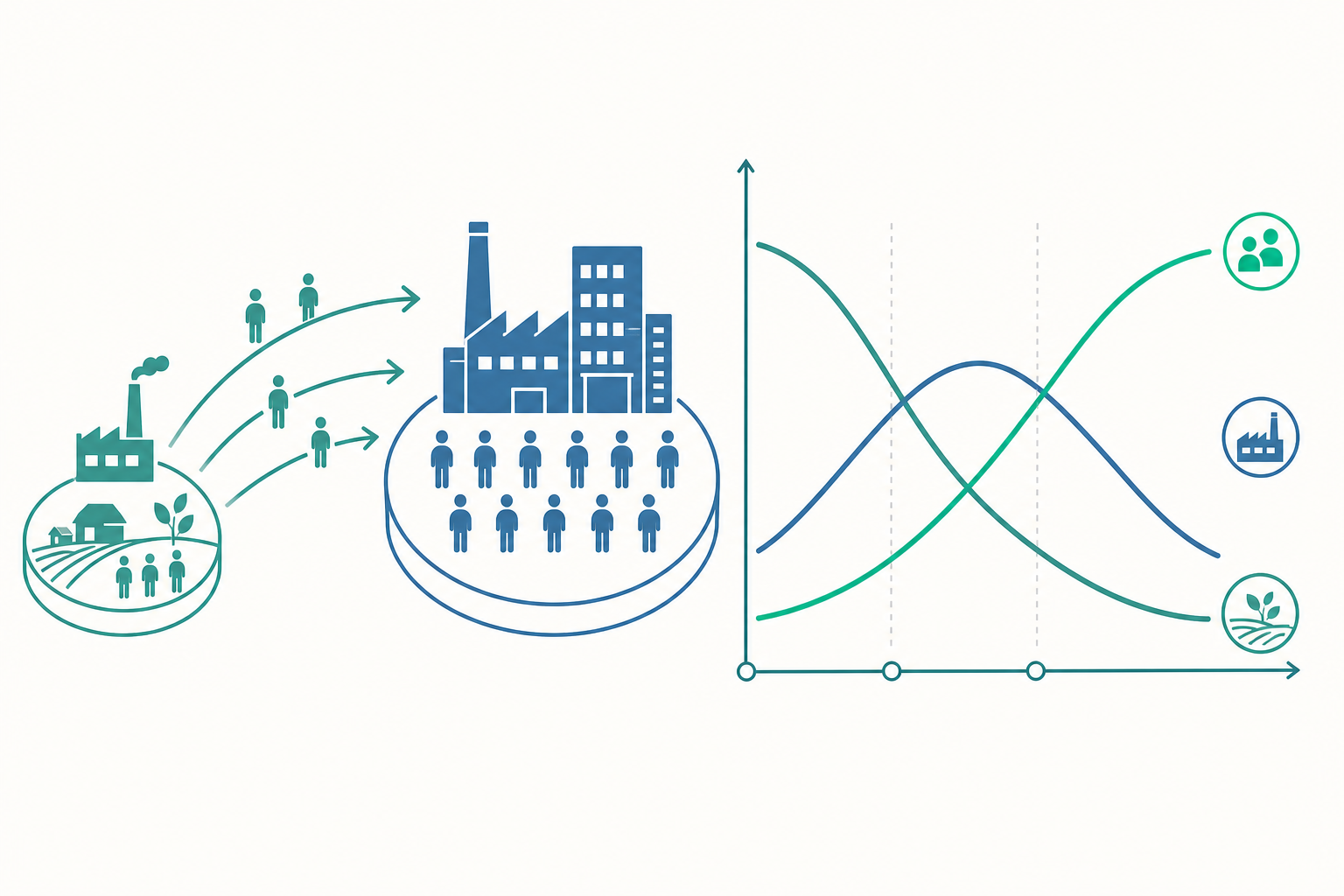
結構轉型:發展的真正「形狀」
入門篇問「成長為何發生」,進階篇要問「成長長什麼樣子」。所有富裕國家的發展歷程,幾乎都遵循同一個結構性軌跡,稱為結構轉型:勞動力與產出的重心,從農業移向製造業,再移向服務業。
這背後有一條跨越兩百年的經驗規律。令 $\theta_a, \theta_m, \theta_s$ 分別為農業、製造業、服務業佔總就業的比重($\theta_a + \theta_m + \theta_s = 1$)。隨著人均所得 $y$ 上升:
$$\frac{d\theta_a}{dy} < 0, \qquad \frac{d\theta_m}{dy} \;\text{先升後降(倒 U)}, \qquad \frac{d\theta_s}{dy} > 0$$
為什麼會這樣?兩股力量在拉扯。需求面是 Engel 法則(Engel's Law):人對食物的需求有上限,所得越高,花在食物上的比例越低,於是農業的相對需求萎縮。供給面則是各部門生產力成長速度不同——農業技術進步釋放出大量過剩勞動力,這些人必須有去處。
這裡有個常被誤解的重點:結構轉型的「方向」是規律,但「速度」與「順序」卻是發展成敗的關鍵。東亞奇蹟(韓國、台灣)的特徵是農業勞動力快速且大規模地轉入高生產力的出口製造業;而許多非洲與拉美國家卻出現了 Dani Rodrik 所稱的「過早去工業化(premature deindustrialization)」——製造業比重在人均所得還很低時就見頂下滑,勞動力直接從農業流向低生產力、非正式的都市服務業(街頭小販、零工)。這等於跳過了那個能累積技能、吸納大量人口、帶動生產力躍升的製造業階梯。
雙元經濟與資源錯置:開頭那個問題的正式版
要理解「資源放錯地方」,得回到發展經濟學的奠基模型之一:Arthur Lewis(1979 年諾貝爾獎)的雙元經濟(dual economy)模型。
Lewis 把開發中經濟切成兩塊:一個是傳統的、邊際勞動生產力近乎為零的農業部門(存在大量「隱藏性失業」,disguised unemployment);另一個是現代的、生產力高的資本主義部門。在轉型早期,現代部門可以用幾乎固定的低工資,從農業部門「無限供給」地吸收勞動力——這段期間的成長,本質上就是把人從邊際產出 ≈ 0 的地方,搬到邊際產出 > 0 的地方。
我們可以把錯置的代價形式化。設一個經濟有許多生產單位 $i$,各自的邊際產出價值記為 $MRPL_i$(邊際勞動產值)。在一個沒有摩擦的市場裡,工人會流動到報酬最高處,直到所有單位的邊際產值拉平:
$$MRPL_1 = MRPL_2 = \cdots = MRPL_n = w$$
這是配置效率的條件。一旦存在摩擦(信貸限制、政治關係、補貼、戶籍制度、土地不可交易),這個等式就會被打破——有些單位的 $MRPL_i$ 遠高於 $w$(它們「資源不夠」),有些遠低於 $w$(它們「霸佔資源」)。邊際產值的離散程度(dispersion),就是錯置的度量:離散越大,把資源重新洗牌所能釋放的產出潛力越大。Hsieh–Klenow 正是用扭曲後 $MRPL$(與邊際資本產值 $MRPK$)的離散度,反推出前述那 30%–60% 的 TFP 損失。
看一個例子
讓我們用具體數字感受錯置的代價。某地有兩間紡織廠,共用 100 名工人。兩廠的產出(單位:萬元)對投入工人數 $L$ 的生產函數同為 $f(L) = 20\sqrt{L}$,但高效廠面對的市場價格是低效廠的兩倍,故其產值函數為:
- 高效廠(H):$Y_H = 40\sqrt{L_H}$,邊際產值 $MRPL_H = 20/\sqrt{L_H}$
- 低效廠(L):$Y_L = 20\sqrt{L_L}$,邊際產值 $MRPL_L = 10/\sqrt{L_L}$
情境一(錯置):因為低效廠老闆與官員關係好,硬是分到 80 人,高效廠只剩 20 人。
$$Y_H = 40\sqrt{20} \approx 178.9,\quad Y_L = 20\sqrt{80} \approx 178.9,\quad \text{總產出} \approx 357.8$$
情境二(效率配置):讓兩廠邊際產值相等,$20/\sqrt{L_H} = 10/\sqrt{L_L}$,解得 $L_H = 4L_L$。代入 $L_H + L_L = 100$,得 $L_H = 80, L_L = 20$。
$$Y_H = 40\sqrt{80} \approx 357.8,\quad Y_L = 20\sqrt{20} \approx 89.4,\quad \text{總產出} \approx 447.2$$
同樣的 100 名工人、同樣的技術,只是把人從低效廠搬到高效廠,總產出就從 357.8 跳到 447.2,提升約 25%。沒有任何新投資、沒有任何技術進步——這就是「制度摩擦稅」的真面目。一國若處處皆然,加總起來就是巨大的隱形貧窮。
因果識別工具箱:當你無法做隨機實驗時
入門篇介紹了 RCT。但現實中,大量重要的發展問題無法隨機分派——你不能隨機讓某些國家獨立、隨機讓某些村莊通電、隨機指定誰當總統。於是「可信度革命」發展出一整套準實驗(quasi-experimental)方法,從非隨機的現實中「借用」隨機性。研究所學生必須能分辨它們各自的識別假設。
雙重差分(Difference-in-Differences, DiD)。 當某政策只在某些地區、某個時點上路,我們可以比較「處理組前後變化」減去「對照組前後變化」:
$$\hat{\delta}_{DiD} = \big(\bar{Y}^{post}_{treat} - \bar{Y}^{pre}_{treat}\big) - \big(\bar{Y}^{post}_{ctrl} - \bar{Y}^{pre}_{ctrl}\big)$$
它的核心識別假設是平行趨勢(parallel trends):若沒有政策介入,兩組的結果會以相同的趨勢演變。第二個減項的作用,正是用對照組來「扣掉」那些同時影響兩組的共同時間衝擊(如全國性的景氣或天氣)。
斷點迴歸(Regression Discontinuity, RD)。 許多政策有一條人為的門檻:考試 60 分及格、所得低於某線才領補助、村莊人口超過某數才設醫院。剛好落在門檻兩側的人,幾乎在所有特質上都相同,唯一差別就是「有沒有越過門檻拿到處理」。於是門檻處結果變數的跳躍幅度,就是該政策的局部因果效果:
$$\tau_{RD} = \lim_{x \downarrow c} E[Y \mid X = x] - \lim_{x \uparrow c} E[Y \mid X = x]$$
其中 $X$ 是決定資格的「跑分變數(running variable)」,$c$ 是門檻。RD 的美感在於它在門檻附近逼近一場局部隨機實驗。
工具變數(Instrumental Variables, IV)。 當我們擔心解釋變數 $D$(如「制度品質」)與誤差項相關(內生性),可以找一個工具 $Z$,它只透過 $D$ 來影響結果 $Y$,本身與誤差無關。入門篇提到的 Acemoglu–Johnson–Robinson 用「殖民者死亡率」當工具來識別制度對成長的因果效果,正是 IV 的經典範例:死亡率影響殖民地建立何種制度,但(在控制變數後)不直接影響今日所得。IV 的兩個鐵則是相關性($Z$ 與 $D$ 相關)與排除限制(exclusion restriction)($Z$ 不經由 $D$ 以外的管道影響 $Y$)——後者無法被資料驗證,只能靠論證,這也是 IV 最常受攻擊之處。
一個觀念上的統一:上述每一種方法(含 RCT)估計的都不是抽象的「政策效果」,而是某個特定群體的局部效果。RCT 給的是樣本平均處理效果,RD 給的是門檻附近的局部效果,IV 給的是「被工具推動而改變行為者」的局部平均處理效果(local average treatment effect, LATE)。它們是誰的效果,比效果本身更需要交代清楚。
RCT 的盲點:一般均衡與規模化
入門篇已提醒 RCT 有外部效度的問題。研究所視角要把這點推到更尖銳的地方:RCT 估的是「部分均衡(partial equilibrium)」效果,但政策的真正影響往往發生在「一般均衡」層次。
關鍵的盲區是外溢與價格反應。假設一個 RCT 發現「給某些年輕人職業訓練,他們的就業率上升了」。這個乾淨的估計隱含一個假設:對照組不受影響。但若把這個方案推廣到全國,會發生什麼?受訓者搶到的工作,可能正是原本屬於未受訓者的——這叫替代效應(displacement effect)。整體就業可能根本沒增加,只是重新分配。實驗的「處理組相對對照組」估計,會系統性高估全國規模化後的真實效果,因為它把被「偷走」的對照組工作也算成了淨增加。
同樣的邏輯適用於現金移轉、技能補貼、肥料補貼。Egger 等人(2022)在肯亞的大規模現金移轉實驗刻意做了飽和設計(saturation design)——隨機改變不同村莊「接受移轉的家戶比例」——正是為了測量這些外溢與當地物價反應。結果顯示在低度利用的當地經濟中,現金移轉產生了正向的地方乘數(local multiplier)而非顯著通膨,這恰恰是單純比較戶層處理/對照所看不到的一般均衡效應。
由此引出方法論的前沿趨勢:化約式(reduced-form)的乾淨實驗,與結構式(structural)模型的政策外推,正在融合。做法是用實驗去識別並估計結構模型的關鍵參數(如勞動需求彈性、移轉的邊際消費傾向),再把這些可信參數嵌入一般均衡模型,模擬「全國規模化」的反事實。這既保住了實驗的可信度,又補上了外推與機制的能力——這是當代發展計量最被看重的研究設計品味。
重點回顧
- 資源錯置(misallocation):貧窮國家窮,很大一部分源於既有要素「擺錯位置」。以邊際產值離散度衡量,Hsieh–Klenow 估計修正後可使中印製造業 TFP 提升 30%–60%。配置效率的條件是各單位邊際產值拉平。
- 結構轉型:發展的「形狀」是勞動力從農業 → 製造業(倒 U)→ 服務業移動,由 Engel 法則(需求面)與部門生產力差異(供給面)共同驅動;「過早去工業化」是當代發展的重大警訊。
- 雙元經濟(Lewis):早期成長的本質是把勞動力從邊際產出近乎零的傳統部門,移到生產力高的現代部門。
- 準實驗工具箱:DiD(平行趨勢)、RD(門檻跳躍)、IV(相關性+排除限制)讓我們在無法隨機分派時仍能識別因果,但每種方法估的都是特定群體的局部效果(如 IV 的 LATE)。
- 一般均衡批判:RCT 是部分均衡估計,忽略替代效應與價格反應,可能高估規模化後的真實效果;前沿做法是「實驗估參數+結構模型外推」。
深入探討(研究所視角)
錯置的微觀基礎與「扭曲楔子」。 Hsieh–Klenow 框架的數學核心,是在 monopolistic competition(壟斷性競爭)下,為每個生產單位定義產出扭曲楔子 $\tau_{Y,i}$ 與資本扭曲楔子 $\tau_{K,i}$。無扭曲時,最適配置使各廠 $MRPK$ 與 $MRPL$ 相等;扭曲存在時,廠商有效規模偏離其生產力應有的水準,最終 TFP 可寫成「無扭曲 TFP」乘上一個由扭曲的離散度決定的折扣項。要小心的是,觀測到的離散度並不全等於錯置:衡量誤差、調整成本、加成(markup)異質性、需求衝擊都會混入。後續文獻(如 Restuccia–Rogerson 的回顧)因此主張,務必區分「真扭曲」與「效率本就應有的異質性」,這也是該領域至今的活躍辯論。
內生性的成長理論橋接。 把錯置與結構轉型放進動態框架,會連到內生成長(endogenous growth)與「成長診斷(growth diagnostics)」。Hausmann–Rodrik–Velasco 的成長診斷框架主張:每個國家的成長受限於不同的「束縛性約束(binding constraint)」——有的卡在融資成本、有的卡在低社會報酬(基礎建設、人力資本)、有的卡在私人專享性低(協調失靈、產權)。其方法論精神是反對萬靈丹式的改革清單,改採類似醫療診斷的「找出此時此地最痛的那一個約束」。這與入門篇的制度觀並不衝突,而是把「制度」拆解成可操作的、依國情排序的具體約束。
空間與聚集:發展的地理維度。 一條快速崛起的前沿,是把發展經濟學與空間/都市經濟學(spatial economics)結合。新經濟地理(Krugman)的核心張力是聚集力(agglomeration)(規模報酬遞增、知識外溢、厚勞動市場)對抗擴散力(dispersion)(地租、壅塞、運輸成本)。這解釋了為何發展高度集中於少數都市群,也引出量化空間模型(quantitative spatial models)——用大量區域資料與一般均衡結構,模擬修一條公路、設一個經濟特區、放寬戶籍遷徙,會如何重新分配人口與產出。這正是「資源錯置」在地理維度的延伸:人也可能「擺錯地方」。
測量革命與機器學習。 傳統發展研究苦於資料稀缺,前沿則用夜間燈光、衛星影像、手機通聯、行動支付等替代資料,以機器學習估計傳統普查觸及不到地區的貧窮與經濟活動(如 Jean 等人 2016 的衛星影像貧窮預測)。這在方法上呼應 Educational Omics 以多模態、細粒度量測理解人類發展的精神——當量測尺度從「國家年資料」細化到「網格月資料」,許多過去無法識別的因果與動態才終於浮現。
對有志深入者,建議在讀完入門篇推薦的 Poor Economics、Why Nations Fail 後,循三條主線前進:方法上精讀 Angrist–Pischke 的 Mostly Harmless Econometrics 掌握 DiD/RD/IV/LATE 的識別邏輯;錯置與生產力上研讀 Hsieh–Klenow(QJE 2009)與 Restuccia–Rogerson 的回顧;理論統一上回到 Debraj Ray 的 Development Economics 與 Acemoglu 的 Introduction to Modern Economic Growth。如此便能把「貧窮」從一個道德概念,重建為一個可量測、可識別、可被政策槓桿撬動的結構性現象。