
彈性進階:從對數導數到最適訂價與識別問題
當彈性沿著曲線滑動,一個彈性數字到底意味什麼?深入點彈性、替代彈性、反彈性訂價、Ramsey 課稅與工具變數識別。
如果彈性會隨著價格一路改變,那「一個」彈性數字到底有什麼意義?
你在入門篇學過:同一條直線型需求曲線上,彈性其實處處不同——高價段有彈性、低價段無彈性、中點剛好單位彈性。這個事實看似只是個小注腳,卻埋下了一個讓許多人困惑的問題:既然彈性會隨價格滑動,那麼當廠商說「我家產品的彈性大約是 1.8」、當論文寫「汽油的長期需求彈性約 0.7」時,他們指的究竟是哪一點的彈性?又或者,他們其實假設了一條處處彈性相同的需求曲線?
答案牽涉到一個進階篇才會認真面對的分水嶺:點彈性(point elasticity)與弧彈性(arc elasticity)的根本差異,以及為什麼經濟學家在實證與理論建模時,往往刻意選用一種「彈性是常數」的特殊需求函數。從這裡出發,我們會一路走到獨占廠商的最適訂價、最適課稅理論、與計量上如何把彈性「估」出來。這些都是彈性真正展現威力的地方——它不只是課本上的一個比值,而是把消費者理論、廠商行為、政府政策與計量方法串成一線的樞紐。
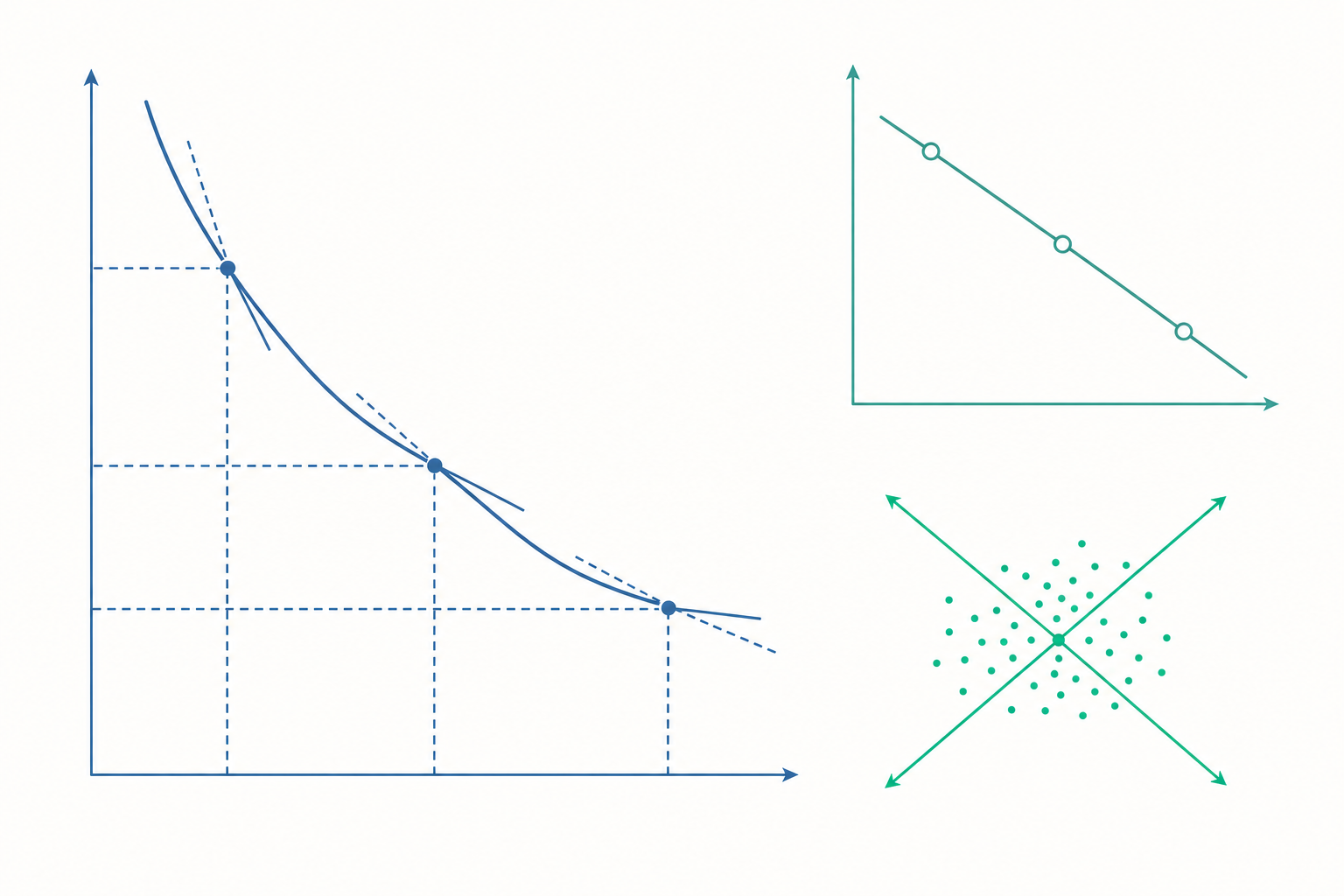
點彈性:把「百分比比值」變成「對數導數」
入門篇用的中點法,本質上是在一段「弧」上取平均,這在資料只有兩點時很實用。但理論分析需要的是某一點上的瞬間敏感度。我們讓價格的變動趨近於零,彈性就從差分變成微分:
$$\varepsilon_d = \frac{dQ/Q}{dP/P} = \frac{dQ}{dP}\cdot\frac{P}{Q}$$
這就是點彈性。它把「斜率的倒數 $dQ/dP$」乘上「該點的價量比 $P/Q$」。注意斜率 $dQ/dP$ 對一條直線型需求曲線而言是常數,但 $P/Q$ 會隨著你沿曲線移動而改變——這正是「同一條直線上彈性處處不同」的數學來源。
更優雅的寫法,是用對數微分。因為 $d\ln Q = dQ/Q$、$d\ln P = dP/P$,所以:
$$\varepsilon_d = \frac{d\ln Q}{d\ln P}$$
入門篇的研究所視角曾點到這個對數形式,但沒說它為什麼如此重要。關鍵在於:彈性等於「對數需求曲線的斜率」。如果我們把需求函數寫成 $Q = A P^{-b}$ 這種冪次型(power form),取對數後得到 $\ln Q = \ln A - b\ln P$,這是一條斜率為 $-b$ 的直線。於是這條需求曲線的彈性在每一點都恰好等於 $-b$——一個常數。
這種需求函數叫等彈性需求(constant-elasticity demand)。它解釋了一個你或許曾隱約覺得矛盾的現象:明明入門篇說「彈性會變」,為什麼實證論文卻動不動就報一個單一的彈性數字?因為他們在建模時,刻意假設需求是冪次型,使彈性成為一個可以被乾淨估計的常數參數。這不是偷懶,而是一個有意識的取捨:用「彈性恆定」換取「模型可估、結論可詮釋」。
看一個例子:直線需求 vs. 等彈性需求
假設兩家分析師面對同一組資料點:價格 50 元時賣 100 單位,價格 60 元時賣 80 單位。
分析師 A 套用直線需求 $Q = 200 - 2P$(你可以驗證 $P=50$ 給 $Q=100$、$P=60$ 給 $Q=80$)。在 $P=50$ 這一點,斜率 $dQ/dP=-2$,所以:
$$\varepsilon_d = -2 \times \frac{50}{100} = -1$$
剛好單位彈性。但如果換算到 $P=60$:$\varepsilon_d = -2 \times 60/80 = -1.5$,變成有彈性。同一條曲線,兩個價格,兩個彈性。
分析師 B 套用等彈性需求 $Q = A P^{-b}$。用兩點解聯立:$\frac{100}{80} = (60/50)^{b}$,取對數得 $b = \ln(1.25)/\ln(1.2) \approx 1.22$。在這個模型裡,無論價格是 50 還是 60,彈性都固定是 $-1.22$。
兩位分析師看的是同一筆資料,卻會對「再漲一點價會怎樣」給出不同預測。這提醒我們:報告彈性時,背後永遠藏著一個函數形式的假設。沒有「客觀中立」的彈性數字,只有「在某模型、某價格區間下」的彈性。
馬歇爾 vs. 希克斯:一個價格變動,兩種彈性
入門篇提到 Slutsky 方程式把價格效果拆成替代與所得兩部分。進階篇我們把它完全寫成彈性的語言,因為這是福利分析與實證解讀的關鍵。
當價格上漲,消費者買得更少,原因有二:(1) 這個商品相對變貴了,轉而買替代品(替代效果);(2) 實質購買力下降,整體變窮了(所得效果)。我們平常在市場上觀察到的需求曲線,是兩者加總的馬歇爾需求(Marshallian / 一般需求);而只保留替代效果、把購買力補償到原效用水準的,是希克斯需求(Hicksian / 補償需求)。
把 Slutsky 方程式 $\frac{\partial x}{\partial P} = \frac{\partial x^h}{\partial P} - x\,\frac{\partial x}{\partial m}$ 各項乘上 $P/x$ 化為彈性,可得一個漂亮的關係:
$$\varepsilon_d = \varepsilon_d^{h} - s\,\varepsilon_m$$
其中 $\varepsilon_d$ 是(馬歇爾)價格彈性、$\varepsilon_d^{h}$ 是希克斯(補償)價格彈性、$\varepsilon_m$ 是所得彈性,而 $s = Px/m$ 是該商品佔總支出的比重。
這條式子一口氣解釋了入門篇列的兩個決定因素。第一,支出佔比 $s$ 越大,馬歇爾彈性與希克斯彈性差距越大——這就是為什麼房租、汽油這類「吃掉大半薪水」的商品,所得效果不可忽略。第二,對佔比極小的商品(一盒火柴的 $s$ 趨近 0),$\varepsilon_d \approx \varepsilon_d^{h}$,所得效果可以放心忽略。這也是為什麼局部均衡分析常假設「準線性效用」——好讓所得效果消失、兩種需求合而為一,使消費者剩餘的計算變得乾淨。
順帶一提,這也澄清了一個迷思:吉芬財(Giffen good)並不違反需求法則的本質。它之所以可能出現 $\varepsilon_d > 0$(漲價反而買更多),是因為它是極端劣等財($\varepsilon_m$ 為大負值)且佔支出比重高,使得 $-s\,\varepsilon_m$ 這個正項大到壓過了負的替代效果。希克斯需求(替代效果)永遠是負的;違反直覺的只是馬歇爾需求。
替代彈性:彈性家族裡最被低估的成員
到目前為止談的都是「需求量對價格」的反應。但生產與消費理論裡還有一個威力強大、入門篇完全沒提的概念:替代彈性(elasticity of substitution, $\sigma$)。它問的不是「量對價」,而是「兩種投入(或財貨)的相對使用量,對它們相對價格的反應有多大」。
以生產為例,廠商用資本 $K$ 與勞動 $L$ 生產。當工資相對資本租金變貴($w/r$ 上升),廠商會少用勞動、多用機器。替代彈性衡量這個替換的容易程度:
$$\sigma = \frac{d\ln(K/L)}{d\ln(w/r)}$$
- $\sigma \to 0$:兩投入是完全互補(如左鞋與右鞋),比例固定,再怎麼改變相對價格也換不動。對應 Leontief 生產函數。
- $\sigma \to \infty$:兩投入是完全替代,一點價差就全部換過去。
- $\sigma = 1$:對應大名鼎鼎的 Cobb–Douglas 生產函數,此時無論相對價格如何變,兩投入的支出佔比保持不變——這是 Cobb–Douglas 之所以好用的數學祕密。
更一般的 CES(constant elasticity of substitution)生產函數
$$Y = \left[\alpha K^{\rho} + (1-\alpha) L^{\rho}\right]^{1/\rho},\qquad \sigma = \frac{1}{1-\rho}$$
是現代總體經濟、成長理論、所得分配研究的主力工具。為什麼?因為「所得是否會越來越集中於資本」這個當代大哉問,數學上幾乎完全取決於 $\sigma$ 是否大於 1。若 $\sigma>1$(資本與勞動容易互換),當機器越來越便宜、越用越多時,資本的所得佔比會上升,勞動相對吃虧;若 $\sigma<1$ 則相反。Piketty 在《二十一世紀資本論》裡的核心爭論,本質上就是一場關於 $\sigma$ 數值的辯論。一個小小的彈性參數,竟撐起了關於貧富差距的世紀論戰。
廠商如何用彈性訂價:Lerner 指數與反彈性法則
入門篇談過彈性與總收入的關係,但那只回答了「漲價是賺是賠」。進階篇要回答更精準的問題:一個有市場力量的廠商,最適價格到底該訂在哪裡? 答案直接寫在彈性裡。
獨占廠商追求利潤極大,條件是邊際收入等於邊際成本($MR=MC$)。可以證明,邊際收入與彈性的關係是:
$$MR = P\left(1 + \frac{1}{\varepsilon_d}\right) = P\left(1 - \frac{1}{|\varepsilon_d|}\right)$$
把 $MR=MC$ 代入並整理,得到經濟學裡最實用的訂價公式之一——Lerner 指數(Lerner index),也就是反彈性訂價法則(inverse elasticity rule):
$$\frac{P - MC}{P} = \frac{1}{|\varepsilon_d|}$$
左邊是「加成率(markup)」:價格高出邊際成本的比例。這條式子說的是:廠商面對的需求越無彈性,加成越高、訂價越狠。
這帶出兩個深刻結論。其一,獨占廠商絕不會在需求無彈性的區段($|\varepsilon_d|<1$)營運。因為若 $|\varepsilon_d|<1$,公式會要求 $P-MC$ 超過 $P$,亦即 $MC<0$,這不可能。直覺上,在無彈性區漲價既能增收又能省成本(賣得少),廠商一定會繼續漲到進入有彈性區為止。所以獨占的均衡必然落在 $|\varepsilon_d|>1$ 的區段——這是一個只有懂彈性才能看穿的結構性事實。
動手試試
某軟體公司估計其產品需求彈性為 $|\varepsilon_d|=4$,邊際成本(多一份授權的成本,幾乎只有伺服器費用)為每份 100 元。最適加成率是多少?最適價格呢?
由反彈性法則:$\frac{P-MC}{P}=\frac{1}{4}=0.25$,即價格的 25% 是加成。解 $P-100 = 0.25P$,得 $0.75P=100$,$P\approx 133$ 元。
現在假設這家公司透過品牌綁定與資料鎖定,把客戶的彈性壓到 $|\varepsilon_d|=2$(替代更難了)。重算:$\frac{P-MC}{P}=0.5$,$0.5P=100$,$P=200$ 元。彈性減半,最適價格從 133 漲到 200。 這就是為什麼企業砸大錢做品牌、做生態系綁定、做轉換成本——它們真正在買的,是「讓你的需求變得更無彈性」的權利。
反彈性法則的孿生兄弟:最適課稅與 Ramsey 法則
最迷人的是,同一個「反彈性」邏輯,從廠商訂價跳到政府課稅後依然成立,只是目標相反。獨占廠商用反彈性法則榨取消費者,而政府的最適課稅理論(Ramsey)用反彈性法則來最小化傷害。
入門篇的研究所視角談過:彈性越小的一方稅負越重、彈性越大則無謂損失越大。我們把無謂損失(deadweight loss, DWL)寫得更精確。對一個小幅單位稅 $t$,在局部近似下:
$$DWL \approx \frac{1}{2}\cdot\frac{|\varepsilon_d|\,\varepsilon_s}{|\varepsilon_d|+\varepsilon_s}\cdot\frac{t^2}{P}\cdot Q$$
兩個重點藏在這條式子裡。第一,DWL 與 $t^2$ 成正比——稅率加倍,效率損失變四倍,這是「寧可對很多商品各課一點,也別對單一商品課重稅」的數學根據。第二,DWL 與彈性正相關:對越有彈性的商品課稅,扭曲越嚴重。
於是 Ramsey 最適商品稅法則呼之欲出:若要籌一筆固定稅收又想把總無謂損失壓到最小,對需求越無彈性的商品,應該課越高的稅率。粗略地說,各商品的稅率應與其彈性成反比:
$$\frac{t_i}{P_i} \propto \frac{1}{|\varepsilon_i|}$$
這在效率上完美,卻立刻撞上公平的高牆。最無彈性的商品往往是米、鹽、藥這類民生必需品,而它們在窮人預算中佔比最大。純粹照 Ramsey 法則課稅,等於對窮人最重——這就是為什麼現實的稅制總是在「效率(Ramsey 偏好的反彈性課稅)」與「公平(對必需品減免、對奢侈品加稅)」之間痛苦拉鋸。彈性告訴你效率的方向,但它不會替你做價值判斷。理解這個張力,比背下公式更重要。
把彈性「估」出來:識別問題與工具變數
入門篇結尾提過識別問題:市場上觀察到的價量點,是供需曲線交點的軌跡,直接迴歸會得到混淆的偏誤估計。進階篇我們把這件事講透,因為這是「彈性從理論走向資料」最容易摔跤的地方。
想像每一期的供給或需求都會因為各種衝擊而左右移動。如果某段時間只有供給在動(需求穩定),那麼一連串的交點就會「描出」需求曲線——此時迴歸估到的是需求彈性。反之若只有需求在動,描出的是供給曲線。但真實世界兩條曲線同時亂晃,交點散成一團雲,對它硬跑迴歸得到的東西,既不是需求彈性也不是供給彈性,而是兩者糾纏的產物。這就是 1920 年代 Working 與 Wright 提出的經典識別問題(identification problem)。
解法是工具變數(instrumental variable, IV):找一個只移動其中一條曲線、卻不直接影響另一條的外生變數。
- 要估需求彈性,需要一個移動「供給」但不直接影響需求的工具。經典做法是用天氣:乾旱讓農產供給左移,但消費者想吃多少米並不直接看天氣。供給被天氣推著沿需求曲線滑動,於是需求曲線被「點亮」。
- 要估供給彈性,則反過來找移動需求的工具,如外國的所得衝擊(影響出口需求,不直接影響本國產能)。
在實作上,最常見的形式是把等彈性需求取對數後做兩階段最小平方(2SLS):
$$\ln Q = \alpha + \beta \ln P + \varepsilon,\qquad \beta = \varepsilon_d$$
第一階段用工具 $Z$(如天氣)預測 $\ln P$,第二階段再用預測值估 $\beta$。這樣估出的 $\beta$ 才是乾淨的需求彈性,而非供需混淆的相關係數。這個框架不只是歷史古董——今天數位平台做 A/B 定價實驗,本質上就是用隨機指派當工具變數,人為製造一個「只動價格、不動需求偏好」的外生變動,從而把彈性因果性地估出來。實驗設計,是 IV 思想在資料科學時代的化身。
重點回顧
- 點彈性 $\varepsilon_d = \dfrac{d\ln Q}{d\ln P}$ 是對數需求曲線的斜率;等彈性(冪次型)需求 $Q=AP^{-b}$ 之所以是實證主力,正因它讓彈性成為一個處處恆定、可乾淨估計的參數——但任何單一彈性數字都隱含一個函數形式假設。
- Slutsky 方程式可完全寫成彈性語言 $\varepsilon_d = \varepsilon_d^{h} - s\,\varepsilon_m$:支出佔比 $s$ 越大、所得效果越不可忽略;吉芬財是所得效果壓過替代效果的極端情形,而非違反需求法則的本質。
- 替代彈性 $\sigma$ 衡量投入或財貨相對使用量對相對價格的反應;CES 函數中 $\sigma$ 是否大於 1,決定了資本與勞動的所得分配走向,是貧富差距論戰的數學核心。
- 反彈性法則橫跨訂價與課稅:獨占的最適加成 $\frac{P-MC}{P}=\frac{1}{|\varepsilon_d|}$(故均衡必在有彈性區段),Ramsey 最適稅則要對越無彈性的商品課越高稅——但這與公平正面衝突。
- 估計彈性的核心障礙是識別問題:供需同時移動使直接迴歸偏誤;解法是用只移動單一曲線的工具變數(天氣估需求、所得衝擊估供給),現代 A/B 實驗即其化身。
深入探討(研究所視角)
把彈性推到研究所前沿,它會從「一個參數」升級為「一整套對偶結構與恆等式網絡」。
對偶性與 Roy 恆等式。 馬歇爾需求可由間接效用函數 $v(P,m)$ 透過 Roy 恆等式 $x_i = -\dfrac{\partial v/\partial P_i}{\partial v/\partial m}$ 導出;希克斯需求則由支出函數 $e(P,u)$ 經 Shephard 引理 $x_i^h = \partial e/\partial P_i$ 導出。彈性因而不是孤立的數字,而是這些對偶函數一階導數的對數正規化。Slutsky 矩陣 $\left[\frac{\partial x_i^h}{\partial P_j}\right]$ 的對稱性與半負定性,translate 成彈性後給出一組可檢驗的交叉彈性對稱限制:$s_i\,\varepsilon_{ij}^h = s_j\,\varepsilon_{ji}^h$。這些限制是需求系統實證(如 AIDS、Almost Ideal Demand System)施加在迴歸係數上的理論約束,也是檢驗「資料是否與理性消費者一致」的工具。
加總限制(aggregation restrictions)。 完整需求系統必須滿足三組來自預算限制的恆等式:(1) Engel 加總——所得彈性的支出加權平均等於 1,$\sum_i s_i\,\varepsilon_{mi}=1$(所得多出來的錢必須花光);(2) Cournot 加總——任一價格的交叉彈性加權和受限;(3) 零次齊性——所有名目價格與所得同比例上漲,需求不變,意味各財貨對全部價格與所得的彈性總和為零,$\sum_j \varepsilon_{ij}+\varepsilon_{mi}=0$。這條最後的恆等式正是「沒有貨幣幻覺」的彈性表述:經濟主體只對相對價格反應。估計需求系統時違反這些限制,往往是模型設定錯誤的警訊。
動態與長短期彈性。 入門篇說「時間越長彈性越大」,研究所層次用部分調整模型(partial adjustment)或誤差修正模型(ECM)把它形式化。在 $\ln Q_t = \alpha + \beta_0 \ln P_t + \gamma \ln Q_{t-1}+\varepsilon_t$ 的設定下,$\beta_0$ 是短期彈性,而長期彈性為 $\beta_0/(1-\gamma)$,因為過去消費習慣 $\ln Q_{t-1}$ 帶來慣性。這解釋了為何油價的短期彈性常估在 0.1 上下、長期卻可達 0.6—0.8:換車、搬家、產業轉型需要時間累積。能源與氣候政策評估若誤用短期彈性去推估長期碳稅效果,會嚴重低估減排潛力——這是一個彈性誤用會直接釀成政策失誤的真實案例。
前沿方向。 當代研究把彈性推向更細的維度。其一,異質彈性(heterogeneous elasticity):不同所得、不同地區的消費者彈性差異極大,平均彈性會掩蓋分配後果,需用追蹤資料(panel)與分量迴歸捕捉。其二,結構需求估計(如 BLP 隨機係數 logit)從個體選擇導出市場層級的彈性矩陣,是產業組織與反托拉斯分析(評估併購是否抬價)的標準工具。其三,機器學習因果推論(雙重機器學習、因果森林)讓我們在高維控制變數下,估計隨情境變動的「條件彈性」。無論工具多麼進步,核心問題始終如一:我們想知道的是因果性的反應幅度,而資料給的往往只是相關性的交點軌跡。 從 Wright 的天氣工具變數,到今日平台的隨機定價實驗,整部彈性實證史,其實就是一部人類設法把「敏感度」從觀察資料中乾淨識別出來的奮鬥史。