
漲價導致買得少,還是「買得少的時段剛好漲價」?破解計量的內生性陷阱
當相關不等於因果——從內生性、工具變數到自然實驗,看計量經濟學如何把因果從相關裡撈出來
漲價導致買得少,還是「買得少的時段剛好漲價」?——當相關不等於因果
入門篇我們用價格與銷量的散布圖,畫出一條向下傾斜的迴歸線,得出「漲價之後人們買得比較少」的結論。看起來乾淨俐落,但這裡藏著一個會讓任何計量經濟學(econometrics)審稿人皺眉的陷阱:你估到的,真的是需求曲線嗎?
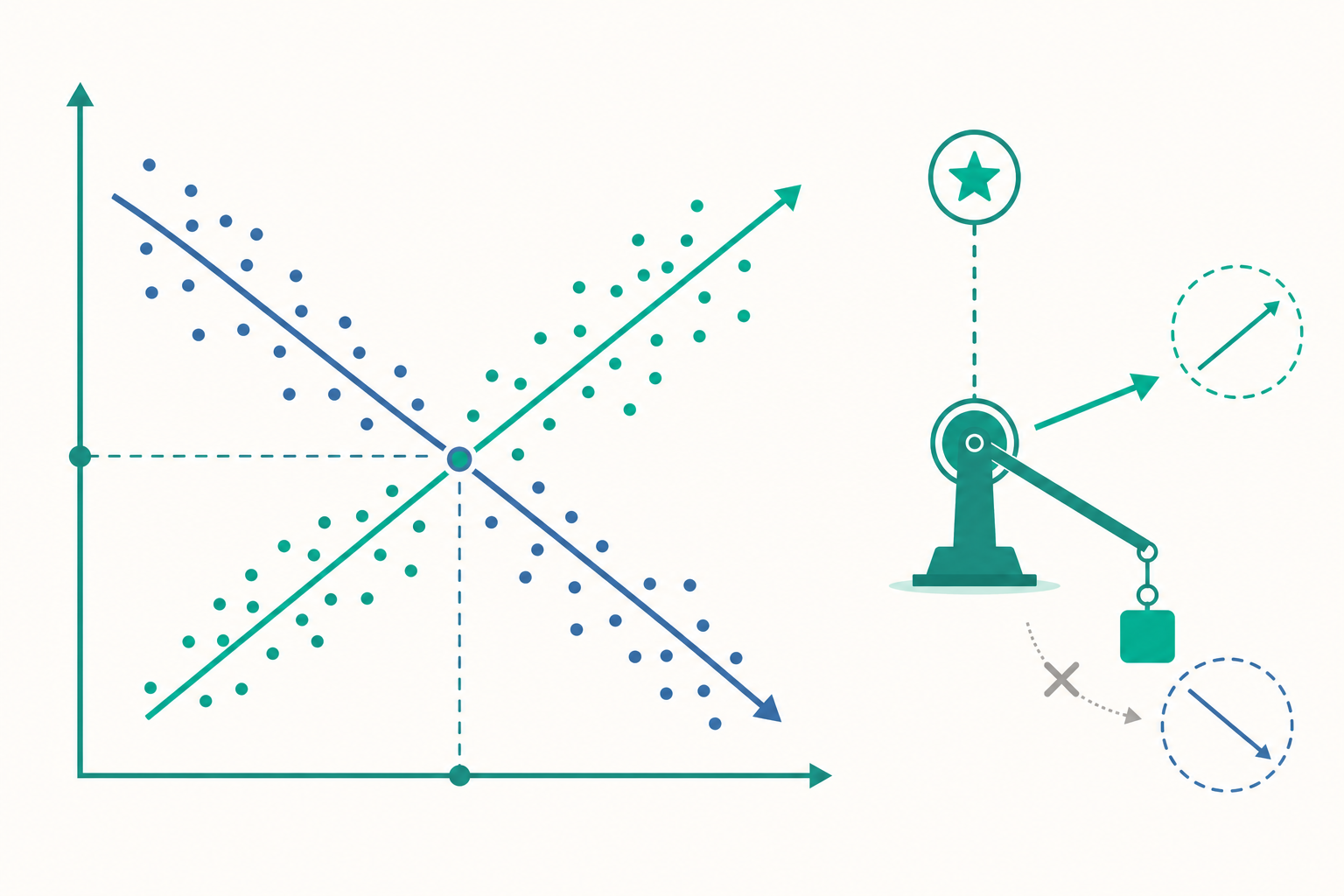
想像一杯手搖飲。夏天最熱、人潮最多的那幾週,店家因為原料成本上升而漲價;冬天客人少,店家為了清庫存而降價。如果你把「全年的價格 vs 銷量」丟進迴歸,你可能會發現——價格高的時候銷量「也」很高。一條向上傾斜的線。難道漲價反而讓人想買?
當然不是。你看到的不是需求曲線,而是供給與需求同時移動之後,那些交點所連成的軌跡。這篇進階篇要處理的,正是入門篇刻意略過的核心問題:為什麼樸素的迴歸會系統性地估錯,以及計量經濟學發明了哪些武器來把「因果」從「相關」裡撈出來。
內生性:迴歸最危險的敵人
回到入門篇的迴歸式。我們想估計需求方程:
$$ Q_t = \alpha + \beta P_t + \varepsilon_t $$
其中 $Q_t$ 是銷量、$P_t$ 是價格、$\varepsilon_t$ 是「其他影響需求但我們沒放進模型的因素」——天氣、人潮、競爭店促銷、社群媒體上突然爆紅等等。
最小平方法(OLS, Ordinary Least Squares)能給出 $\beta$ 的不偏估計,有一個關鍵前提:解釋變數與誤差項不相關,也就是 $\text{Cov}(P_t, \varepsilon_t) = 0$。這個條件叫做外生性(exogeneity)。
問題來了。價格是誰決定的?是店家。店家在決定價格時,會看到那些被我們塞進 $\varepsilon_t$ 的東西——他知道今天人潮洶湧,於是漲價。這意味著當 $\varepsilon_t$ 偏高(需求旺)時,$P_t$ 也偏高。於是:
$$ \text{Cov}(P_t, \varepsilon_t) \neq 0 $$
這就是內生性(endogeneity)。一旦解釋變數與誤差相關,OLS 估出來的 $\hat{\beta}$ 就會有偏誤(bias),而且這個偏誤不會因為樣本變大而消失(這叫不一致性,inconsistency)。樣本越多,你只是越來越精確地估到一個錯的數字。
內生性的三大來源值得記住:
- 同時性(simultaneity):價格決定銷量,銷量也回頭決定價格(供需同時成立),這正是手搖飲的例子。
- 遺漏變數(omitted variable):有個同時影響 $P$ 和 $Q$ 的因素沒被控制(例如「氣溫」同時推高成本與需求)。
- 測量誤差(measurement error):$P$ 本身量測有雜訊,會使係數被往零稀釋(attenuation bias)。
入門篇的迴歸線之所以「看起來合理」,往往只是因為手搖飲這個例子裡需求波動沒蓋過供給波動。換一個資料集,同樣的天真迴歸就可能給你向上傾斜的「需求曲線」。
工具變數:找一根只動供給、不碰需求的槓桿
要把需求曲線從供需糾纏中分離出來,計量經濟學最經典的武器是工具變數(IV, Instrumental Variable)。
直覺是這樣:我們需要一個變數 $Z$,它能讓價格動,但只能透過供給端讓價格動,而不直接影響需求。如果價格的變動「只是因為成本變了」,那麼此時觀察到的銷量變化,就純粹是需求曲線上的移動——我們終於沿著需求曲線在滑動,而不是在交點之間跳。
一個好的工具變數要滿足兩個條件:
- 相關性(relevance):$\text{Cov}(Z, P) \neq 0$,工具要真的能推動價格。
- 外生性 / 排除限制(exclusion restriction):$\text{Cov}(Z, \varepsilon) = 0$,工具除了透過價格之外,沒有別的管道影響銷量。
對手搖飲來說,珍珠(樹薯澱粉)的國際批發價可能就是不錯的工具:它推高店家成本進而推高售價(滿足相關性),但消費者通常不知道、也不在意原料批發價,它不會直接改變人們今天想不想喝飲料(滿足排除限制)。
看一個例子:兩階段最小平方法(2SLS)怎麼運作
最常用的 IV 估計法是兩階段最小平方法(2SLS, Two-Stage Least Squares)。
第一階段:把內生的價格對工具迴歸,取出「由工具解釋的那部分價格」:
$$ P_t = \pi_0 + \pi_1 Z_t + u_t \quad\Rightarrow\quad \hat{P}_t = \hat{\pi}_0 + \hat{\pi}_1 Z_t $$
這個 $\hat{P}_t$ 是「乾淨的價格變異」——它的變動全部來自成本(工具),與需求衝擊 $\varepsilon_t$ 無關。
第二階段:用這個乾淨的 $\hat{P}_t$ 取代原始價格,再跑一次迴歸:
$$ Q_t = \alpha + \beta \hat{P}_t + \text{error} $$
此時的 $\hat{\beta}_{2SLS}$ 才是一致的需求斜率估計。
放個數字感受一下。假設原始 OLS 估出 $\hat{\beta}_{OLS} = -0.3$(每漲 1 元,少賣 0.3 杯),但因為同時性偏誤,這個數字被「需求旺→漲價」的正向關聯往上拉了,低估了需求的敏感度。用珍珠批發價當工具的 2SLS 估出 $\hat{\beta}_{2SLS} = -1.2$——真實的需求其實敏感得多。換成彈性語言:原本看起來「缺乏彈性」的飲料,其實價格彈性遠大於 1。對店家的訂價決策,這是天差地別的結論。
警告:弱工具(weak instrument)問題。 如果工具與價格的相關性很弱(第一階段的 $\hat{\pi}_1$ 接近 0),2SLS 不但變得非常不精確,偏誤甚至可能比 OLS 還嚴重。經驗法則:第一階段迴歸的 F 統計量要大於 10(Staiger–Stock 1997 的著名門檻),否則你的工具不值得信任。
自然實驗:當資料自己幫你「隨機分組」
IV 是一種思路;近三十年「可信度革命(credibility revolution)」帶來更廣的視角——尋找自然實驗(natural experiment),讓現實世界替我們製造近似隨機的處理。其中最常用的兩把刀是 DID 與 RDD。
雙重差分(DID, Difference-in-Differences)
假設某縣市突然對含糖飲料課徵「糖稅」,使售價上升,鄰縣沒有。我們想知道糖稅對銷量的影響,但不能只看課稅縣稅前 vs 稅後的差(因為季節、景氣也在變)。
DID 的做法是「差兩次」:
$$ \hat{\delta}_{DID} = \underbrace{(Q^{\text{課稅}}_{\text{後}} - Q^{\text{課稅}}_{\text{前}})}_{\text{含季節+政策}} - \underbrace{(Q^{\text{對照}}_{\text{後}} - Q^{\text{對照}}_{\text{前}})}_{\text{只含季節}} $$
第一個括號是課稅縣的變化(混了政策效果與共同趨勢),第二個括號是沒課稅的對照縣的變化(純粹是共同趨勢)。兩者相減,共同趨勢被消掉,剩下的就是政策的淨效果。
DID 的命脈是平行趨勢假設(parallel trends):若沒有糖稅,兩縣的銷量本來應該以相同步調變動。這個假設無法直接驗證(因為「沒課稅的反事實」看不到),但我們可以檢查課稅前兩縣趨勢是否平行來增加說服力。
斷點迴歸(RDD, Regression Discontinuity Design)
當「處理」由一條明確的門檻決定時,RDD 特別有力。例如,某補助方案規定「家庭年收入低於 60 萬」才能領取育兒券。剛好 59.9 萬與 60.1 萬的兩個家庭,幾乎一模一樣,唯一差別是一個有券、一個沒有——這個門檻附近,等於老天爺幫你做了隨機分派。
於是我們比較門檻兩側「緊鄰」的家庭,估計補助的因果效果:
$$ \hat{\tau}_{RDD} = \lim_{x \downarrow c} \mathbb{E}[Y \mid X = x] - \lim_{x \uparrow c} \mathbb{E}[Y \mid X = x] $$
其中 $X$ 是收入(running variable)、$c = 60$ 萬是門檻、$Y$ 是結果(如就業率)。圖形上,你會看到結果變數在門檻處出現一個跳躍(jump),跳躍的高度就是因果效果。RDD 的隱憂是有人會「操弄」running variable(例如刻意把收入報成 59.9 萬),這會破壞門檻附近的隨機性,可用 McCrary 密度檢定來偵測。
別忘了標準誤:點估計只是故事的一半
很多人盯著 $\hat{\beta}$ 的數字,卻忽略它的不確定性。同一個 $\hat{\beta} = -1.2$,標準誤是 $0.1$ 還是 $0.9$,意義完全不同。
時間序列與面板資料常違反 OLS 標準誤的兩個假設:
- 異質變異(heteroskedasticity):誤差的變異不固定(旺季雜訊大、淡季雜訊小)。
- 序列相關 / 群聚(autocorrelation / clustering):今天的需求衝擊與昨天相關;同一家店不同日子的觀測也彼此相關。
若忽略這些,傳統標準誤會被嚴重低估,讓你誤以為結果「高度顯著」。解法是使用穩健標準誤(robust / heteroskedasticity-consistent SE),面板資料則用群聚標準誤(clustered SE),按店家或地區分群。一個好習慣:報告係數時,永遠附上它是用哪種標準誤算的。
重點回顧
- 內生性是迴歸最危險的敵人:當解釋變數與誤差相關($\text{Cov}(P,\varepsilon)\neq 0$),OLS 估計有偏且不一致,樣本變大也救不了。
- 入門篇的天真迴歸常估到的不是需求曲線,而是供需交點的軌跡——這是同時性偏誤的經典範例。
- 工具變數(IV)+ 2SLS 透過一個「只動供給、不碰需求」的外生變數,把乾淨的價格變異分離出來;但要小心弱工具(第一階段 F < 10 就別用)。
- DID 靠平行趨勢消掉共同趨勢,RDD 靠門檻附近的近似隨機分派——兩者都是自然實驗思維的代表。
- 點估計之外,標準誤的選擇(穩健、群聚)決定了你的信賴區間是否誠實,別只看係數不看不確定性。
深入探討(研究所視角)
LATE 而非 ATE:IV 估的到底是誰的效果? Imbens 與 Angrist(1994)證明,在處理效果異質(不同人反應不同)的情況下,IV / 2SLS 估到的不是平均處理效果(ATE, Average Treatment Effect),而是局部平均處理效果(LATE, Local Average Treatment Effect)——亦即「順從者(compliers)」這群人的效果,也就是那些「因為工具改變而真的改變了行為」的個體。在四種人(always-takers、never-takers、compliers、defiers)的框架下,LATE 依賴單調性假設(monotonicity):工具的推力對每個人方向一致,不存在「反其道而行」的 defiers。這解釋了為什麼用「珍珠批發價」當工具估出的彈性,嚴格說是「對成本敏感而調價的那些店、那些消費情境」的彈性,外推到其他族群要謹慎。
結構式 vs. 縮減式之爭。 上面 IV/DID/RDD 都屬於「縮減式(reduced-form)」或「設計導向(design-based)」陣營,強調可信的識別策略。另一條路線是結構估計(structural estimation):直接寫下消費者效用最大化與廠商利潤最大化的方程,估計深層的偏好參數(如 BLP 模型估計差異化商品的需求系統)。結構式的優勢是能做反事實政策模擬(counterfactual),例如「若課 20% 糖稅、廠商如何重新訂價、消費者福利損失多少」——這是純縮減式做不到的。代價是更強的函數形式假設。兩派的張力(Angrist–Pischke 對上 Heckman–Nevo)至今仍是計量經濟學方法論的核心辯論。
現代趨勢:機器學習進入因果推論。 當控制變數很多、函數形式未知時,Chernozhukov 等人(2018)的雙重 / 去偏機器學習(Double/Debiased Machine Learning, DML)用機器學習估計干擾參數(nuisance parameters),再透過 Neyman 正交化(orthogonalization)與樣本分割(cross-fitting)還原出有效的因果估計與正確的標準誤。與此並行的是 staggered DID 的新進展:Goodman-Bacon(2021)揭示傳統 two-way fixed effects 在「不同單位於不同時點受處理」時,會用到「已處理組當對照組」這種有問題的比較,催生了 Callaway–Sant'Anna 等新估計量。這些都是當代頂尖期刊(如 Econometrica、AER)的活躍前沿,也是把「漲價之後人們真的買得比較少嗎」這個樸素問題,一路推到可信因果推論最前線的縮影。