
一七四七年,一艘船上的十二個壞血病水手
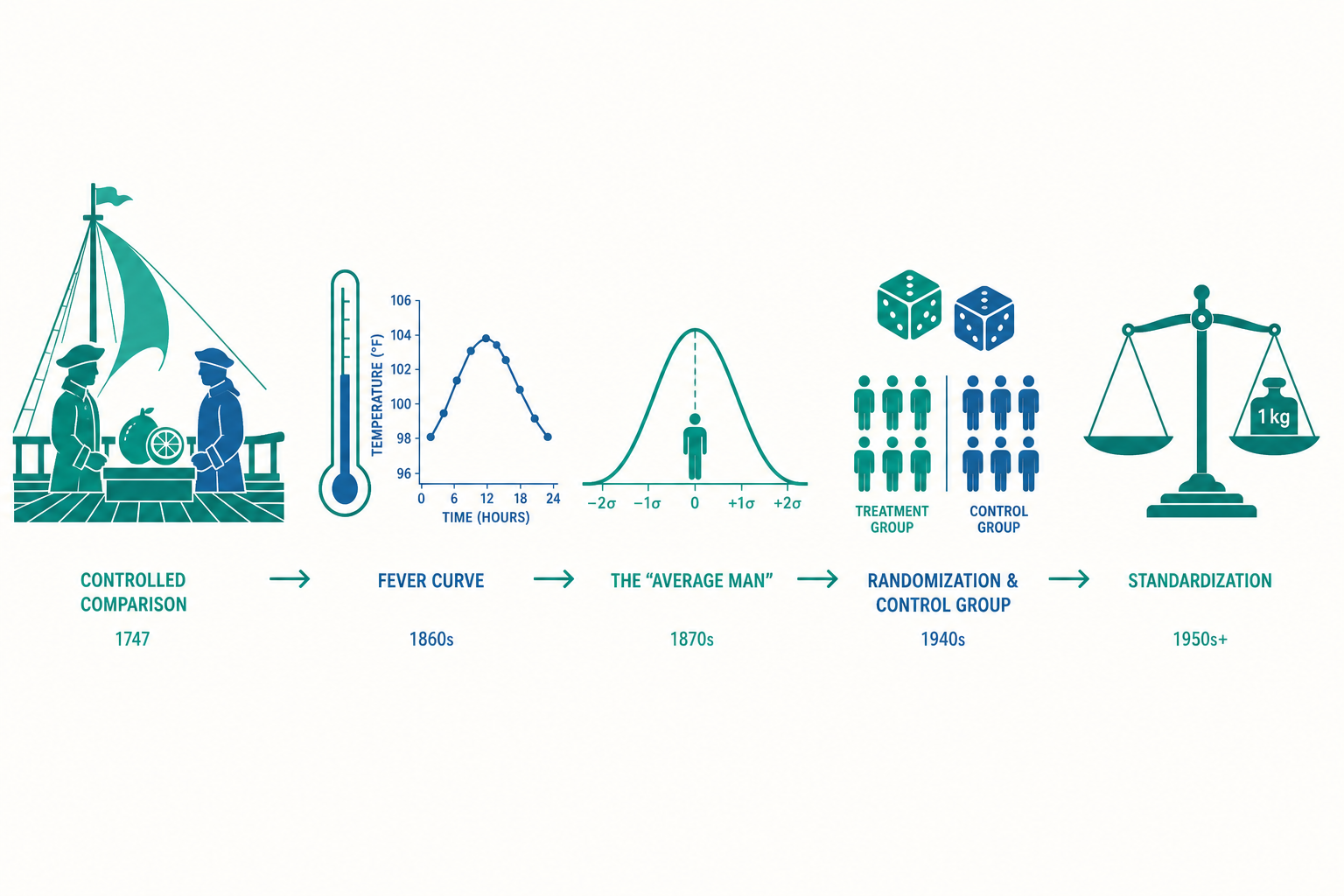
從林德的船上試驗到隨機對照試驗,追溯人類如何發明「測量、比較與證據」的方法,把主觀印象轉化為可被檢驗的科學知識。
一七四七年,一艘船上的十二個壞血病水手
一七四七年五月,英國皇家海軍「索爾茲伯里號」(HMS Salisbury)正在英吉利海峽巡航。船上的隨船外科醫師詹姆斯.林德(James Lind)面對一個古老的殺手:壞血病(scurvy)。在大航海時代,這種病奪走的水手性命,遠多於海戰與船難的總和。當時對病因眾說紛紜——有人說是潮濕的空氣,有人說是鹹肉,有人說是水手的怠惰與憂鬱。
林德做了一件在醫學史上罕見的事。他挑出十二名症狀相近的壞血病患者,讓他們吃一樣的伙食、住一樣的艙房,然後分成六組,每組兩人,分別給予不同的「療法」:有的喝蘋果酒,有的服稀硫酸,有的喝海水,有的吃藥糊,而其中一組——每天吃兩顆柳橙和一顆檸檬。六天後,吃柑橘的兩人幾乎康復,能起身照顧其他病人;其餘各組則不見起色。
入門篇問的是「科學、技術與社會如何彼此糾纏」。進階篇要追問一個更尖銳、也更現代的問題:人類究竟是在什麼時候、用什麼方法,學會了「比較」與「測量」,把『我覺得這個療法有效』這種主觀印象,轉變成可以被檢驗、可以被推翻的『證據』? 林德這場小小的船上試驗,正是這條漫長道路上的一個關鍵路標。它提醒我們,現代科學最深刻的革命,或許不在於發現了什麼新事物,而在於發明了一套判斷『我們怎麼知道一件事為真』的新方法。
從「權威」到「證據」:知識正當性的轉移
要理解林德試驗的份量,必須先理解他所反抗的東西。在近代以前,醫學知識的正當性主要來自權威與傳統:蓋倫(Galen)怎麼說、希波克拉底(Hippocrates)怎麼寫、老師怎麼教。一個療法之所以被相信,往往因為它「自古如此」,或因為某位德高望重的名醫背書。個別醫師的臨床經驗固然重要,但那是難以傳遞、無法累積、更無從驗證的私人印象。
林德的試驗悄悄地改換了知識的「裁判」。他不再訴諸權威,而是訴諸一個刻意安排的比較:在盡可能相同的條件下,只讓一個變因(吃什麼)不同,再看結果有何差異。這個看似簡單的動作,蘊含著現代實驗方法的核心邏輯——控制變因(controlling for variables)。當其他條件都被拉平,結果的差異就更可能歸因於那唯一不同的因素。
值得強調的是,林德並不知道「為什麼」柑橘有效。維生素C(vitamin C,即抗壞血酸 ascorbic acid)要到一九三○年代才被分離鑑定。換句話說,林德掌握了有效的療法,卻沒有掌握正確的機制——這和入門篇談到的斯諾(John Snow)如出一轍:知道「做什麼有用」可以先於知道「為什麼有用」。這正是科學史一再出現的模式,也提醒我們別把「知其然」與「知其所以然」混為一談。
然而,一個耐人尋味的歷史事實是:林德的發現並未立刻改變海軍。柑橘類在當時昂貴又難以保存,林德自己後來也對煮過的「濃縮果汁」抱持太多期望(高溫恰恰破壞了維生素C)。皇家海軍要到約四十年後,才在另一位醫師的推動下普遍配發檸檬汁。一個「正確的證據」要轉化為「制度化的實作」,中間隔著成本、後勤、信念與權力的重重關卡——這又呼應了入門篇的主軸。
把世界變成數字:量化的興起
林德比較的是「有效/無效」,還相當粗略。現代科學真正的銳器,是把品質(quality)轉換成數量(quantity)——也就是量化(quantification)。這場「量化革命」橫跨科學、醫療與整個社會的治理,影響之深遠,怎麼強調都不為過。
一個鮮明的例子是「體溫」。發燒是人類最古老的疾病經驗之一,但在十九世紀以前,醫師判斷發燒靠的是手摸額頭——這是一種模糊的、依賴個人觸感的「定性」判斷。一八六八年,德國醫師翁德利希(Carl Wunderlich)發表了他測量數萬名病人、累積數百萬筆體溫紀錄的研究,確立了攝氏三十七度左右為人體正常體溫,並描繪出不同疾病的「體溫曲線」。從此,發燒不再是「感覺很燙」,而是一個可以被儀器讀出、可以畫成曲線、可以在不同醫師之間傳遞與比較的數字。
請注意這背後的連鎖條件:需要可靠又便攜的臨床溫度計(技術)、需要統一的攝氏溫標(標準)、需要大量病人與系統性的記錄(制度),才能讓「體溫」成為一個有意義的臨床指標。量化從來不只是「拿尺去量」那麼簡單,它預設了一整套器物、標準與組織的基礎建設。
同樣的故事也發生在血壓、視力、血糖、心電圖。每一項今日我們視為理所當然的「生理數據」,背後都有一段把身體狀態轉譯成數字的歷史。而每一次成功的量化,都同時打開了新的可能與新的問題:數字讓比較與累積成為可能,卻也可能讓「無法被測量的東西」(如病人的痛苦感受、生活脈絡)變得不被重視。這個張力,至今仍縈繞在每一個強調「數據驅動」的領域。
統計學的誕生:當「平均人」走上舞台
當愈來愈多的身體被轉換成數字,一個新的學問應運而生:統計學(statistics)。這個詞的字根與「國家」(state)相關,最初指的正是國家為了治理而收集的人口、出生、死亡等數據。
十九世紀的比利時學者凱特勒(Adolphe Quetelet)提出了一個影響深遠又充滿爭議的概念——「平均人」(l'homme moyen, the average man)。他主張,把大量個體的某項特徵(如身高、體重)匯總起來,會呈現出一條規律的鐘形分布(即常態分布 normal distribution),而其平均值代表了某種「理想」或「典型」。凱特勒甚至把這套方法延伸到犯罪、自殺等社會現象,認為它們也遵循可預測的統計規律。
「平均人」的概念是一把雙面刃。一方面,它讓人類首度能夠用群體、機率的方式來思考健康與社會,催生了現代公共衛生、保險精算與社會科學。另一方面,它也潛藏著危險:當「平均」被偷偷等同於「正常」、「正常」又被等同於「應該」,統計就可能從描述工具變成規範武器。十九世紀末興起的優生學(eugenics)便是最沉痛的教訓——高爾頓(Francis Galton)等人發展了相關係數、迴歸等強大的統計工具,卻將其用於論證某些人「天生優越」、某些人「應被淘汰」。許多後來成為統計學支柱的方法,最初竟誕生於這套後來被徹底唾棄的意識形態之中。
這段歷史給我們一個深刻的提醒:統計方法本身的中性,不能保證它被使用的目的中性。 一個強大的量化工具,可以用來照亮真相,也可以用來合理化偏見。這正是為什麼今日談論演算法、大數據與人工智慧時,我們不能只問「模型準不準」,還必須問「它在為誰服務、它把誰當成了『平均人』、它讓誰變得不可見」。
隨機與對照:現代「證據」的黃金標準如何成形
回到林德的比較。他的試驗有一個現代研究者一眼就會看出的弱點:他是「親自挑選」病人分組的。萬一他在不知不覺中,把看起來病情較輕的病人分到了柑橘組呢?萬一兩組病人原本就有某些他沒注意到的差異呢?這種隱藏的偏差(bias),可能讓「療效」只是一種假象。
二十世紀的醫學統計學,給出了一個漂亮的解答:隨機分配(randomization)。
看一個例子:一九四八年的鏈黴素試驗
一九四八年,英國醫學研究委員會(Medical Research Council)發表了一項治療肺結核的鏈黴素(streptomycin)試驗報告,這通常被視為現代「隨機對照試驗」(Randomized Controlled Trial, RCT)的里程碑。設計這項研究的關鍵人物,是統計學家奧斯汀.布拉福.希爾(Austin Bradford Hill)。
這項試驗的巧妙之處,在於它用「擲骰子般的隨機」來決定每位病人接受新藥還是當時的標準療法(臥床休息)。為什麼隨機如此重要?因為隨機分配能在統計上「攤平」所有已知與未知的干擾因素。當分組純由機運決定,研究者的主觀偏好、病人病情輕重的差異、甚至那些我們根本還沒想到要控制的變因,都會在大數法則下大致均勻地分散到兩組。於是,最終兩組結果的差異,就更有把握歸因於「藥物」這個唯一被刻意操弄的變因。
更講究的是,分組資訊還被「盲化」(blinding)——讓評估病情的放射科醫師不知道每張X光片來自哪一組,以免他們的期待影響判讀。隨機(消除分組偏差)加上盲化(消除評估偏差),再加上對照組(提供比較基準),三者合一,構成了今日醫學「實證」(evidence-based)的方法論支柱。
請看這條從林德到希爾、長達兩百年的演進:從「刻意比較」(林德)→ 到「大量測量與統計描述」(翁德利希、凱特勒)→ 再到「隨機分配與盲化對照」(希爾)。每一步,都是人類在「如何更可靠地知道一件事」這個問題上的精進。現代科學的力量,與其說來自個別天才的聰明,不如說來自這套不斷自我修正的方法論——一套刻意設計來「對抗自己會犯錯」的程序。
動手試試:拆解一個健康宣稱
下次當你看到「研究顯示某補充品能提升記憶力」這類宣稱時,不妨用上面的歷史工具拆解它,問幾個問題:
- 有對照組嗎? 是和「什麼都不吃」或「吃安慰劑」的人比較,還是只看了吃補充品的人「自己覺得有沒有變好」?沒有對照,就無從判斷效果是來自補充品,還是來自安慰劑效應或時間自然推移。
- 分組是隨機的嗎? 還是讓受試者「自願」選擇要不要吃?自願吃補充品的人,可能本來就更注重健康(這叫選擇偏差 selection bias),記憶力好未必是補充品的功勞。
- 樣本有多大? 林德每組只有兩人,差異夠戲劇化才看得出來;但細微的效果需要更大的樣本,否則可能只是隨機波動。
- 量的是什麼? 「記憶力」這種抽象概念,被操作化(operationalized)成了什麼具體可測量的指標?這個指標真的測到了我們關心的東西嗎?
你會發現,這些問題沒有一個需要你懂生物化學。它們是方法論的問題,而方法論正是兩百多年來科學社群一點一滴打磨出來的集體智慧。學會這套提問方式,比記住任何單一結論都更接近科學的本質。
標準化:讓數字能夠跨越時空
最後一塊拼圖,是一個容易被忽略、卻支撐起一切量化的隱形基礎——標準化(standardization)。
一個體溫數字要能在台北的醫師與柏林的醫師之間傳遞,前提是兩地用的是同一套溫標、同一種校準過的儀器。一份藥物試驗的「劑量」要有意義,前提是「一公克」在任何實驗室都指涉同樣的質量。這些今日視為理所當然的共識,其實是漫長協商與制度建構的成果。法國大革命後推動的公制(metric system)、十九世紀末成立的國際度量衡局(BIPM),都是人類試圖建立一套「放諸四海皆準」的測量語言的努力。
這正呼應了入門篇談過的標準時間:技術帶來的協調需求(火車、貿易、跨國科學合作),推動了標準的建立,而標準一旦確立,又反過來讓更大規模的協作成為可能。科學知識之所以能夠累積、能夠跨越國界共享,靠的不只是聰明的腦袋,更是這套看不見的「度量衡基礎建設」。沒有標準化,每個實驗室都將是一座孤島,誰也無法檢驗誰的結果——而「可被他人重複檢驗」(replicability),恰恰是科學區別於私人信念的根本特徵。
重點回顧
- 現代科學的核心革命是方法論的革命:不在於發現了哪些新事物,而在於發明了一套判斷「我們如何知道一件事為真」的程序——刻意比較、控制變因、可被重複檢驗。
- 量化把品質轉為數量,讓身體狀態(體溫、血壓)得以被儀器讀取、累積與跨人比較;但量化也預設了儀器、標準與制度的基礎建設,並可能讓「無法被測量者」被忽視。
- 統計學是雙面刃:它讓人類能以群體與機率思考健康與社會,卻也曾被優生學濫用為合理化偏見的工具。方法本身的中性,不保證使用目的的中性。
- 隨機對照試驗(RCT)是實證醫學的支柱:隨機分配攤平已知與未知的干擾因素,盲化消除評估偏差,對照組提供比較基準——這是一套刻意設計來「對抗研究者自身會犯錯」的程序。
- 標準化是量化的隱形基礎:沒有統一的度量衡與校準,數字便無法跨越時空傳遞,科學賴以為生的「可重複檢驗」也無從談起。
深入探討(研究所視角)
對於希望進一步鑽研的學習者,「量化」與「客觀性」的歷史是科學史與 STS 領域最活躍的研究戰場之一,以下幾個方向值得深入。
「機械客觀性」的歷史性。 科學史家達斯頓(Lorraine Daston)與蓋里森(Peter Galison)在《客觀性》(Objectivity, 2007)一書中提出,我們今日奉為圭臬的「客觀性」並非永恆不變的理想,而是有其歷史。他們區分了不同時代科學圖像背後的認識德性(epistemic virtues):十八世紀追求的是描繪「理想型」的「忠於自然」(truth-to-nature),十九世紀中葉才轉向力求排除觀察者主觀介入的「機械客觀性」(mechanical objectivity)——這正是攝影、自動記錄儀器被神聖化的時代。這個視角逼我們反思:當代對「演算法」「自動化」「去除人為偏見」的崇拜,是否正是機械客觀性理想的最新化身?而它又遮蔽了哪些必然存在的人為選擇?
「信任數字」的政治。 歷史學家波特(Theodore Porter)在《信任數字》(Trust in Numbers, 1995)中提出一個反直覺的論點:量化的興起,往往不是因為數字「更準確」,而是因為它提供了一種「無關個人的客觀性」(impersonal objectivity),能在缺乏信任、權力分散的場域中充當公共溝通的語言。當專業菁英的個人判斷不被信任時,「讓數字說話」成為抵禦質疑、分散責任的策略。這個洞見對理解現代官僚、風險評估乃至教育評量(標準化測驗)都極具穿透力——量化常常是社會信任結構的產物,而非單純的技術進步。
操作化與「製造」研究對象。 從哲學與社會學角度,值得追問的是:當我們把「智力」「健康」「學習成效」這類複雜概念「操作化」為某個可測量的指標時,我們究竟是在「測量」一個既存的對象,還是在某種程度上「製造」了它?哈金(Ian Hacking)關於「製造人的種類」(making up people)與「迴圈效應」(looping effect)的討論指出,分類與測量會反過來形塑被分類者的自我理解與行為。這對任何收集人類行為數據的研究——包括多模態學習分析——都是根本性的方法論與倫理警示。
可深化的研究路徑。 若要將上述視角落實於具體研究,可考慮幾條路徑:其一是儀器與基礎建設史,追蹤某項測量技術(如腦電圖 EEG、心率變異 HRV、眼動追蹤)從實驗室走向標準化臨床/教育工具的過程,揭示其中的標準協商與權力配置;其二是指標的批判性系譜學,考察某個今日通行的評量指標(如智商、GPA、各類學習成效量表)如何被建構、被自然化,又排除了什麼;其三是比較與在地化研究,探討同一套量化標準在不同文化脈絡中如何被接受、抵抗或改寫。
最後值得反思的,正是當代教育科技與多模態學習分析所站的位置。當我們把學習者的認知歷程、語言表達、生理訊號與學習環境一一轉換成可計算的數據時,我們正在親身參與一場新的量化革命。林德、翁德利希、凱特勒與希爾的歷史提醒我們:每一次量化都既是賦能也是風險——它讓我們看見前所未見的模式,卻也可能讓某些「無法被數據捕捉」的學習經驗變得不被看見。理解這段「測量如何形塑知識」的歷史,是為了讓我們在設計與使用這些工具時,能更清醒地追問:我們究竟測量了什麼、遺漏了什麼、又把誰當成了那個沉默的「平均學習者」。